Lesen Sie auch: Grundkurs Microservices: Warum Frameworks nicht genug sind
The post CUPID ‒ for joyful coding! appeared first on JAX.
]]>Daniel has been thinking about this for a long time, especially since he poked a stick at the SOLID principles for fun a few years ago and people came after him with pitchforks. Now he has codified his thoughts into his own pithy five-letter acronym, CUPID: Composable, Unix philosophy, Predictable, Idiomatic, Domain-based. Why these characteristics, what do they mean, and why should you care? Can they improve your coding experience or is this just more programmer navel-gazing?
Verschaffen Sie sich den Zugang zur Java-Welt mit unserem kostenlosen Newsletter!
More Topics at JAX & W-JAX:
● Track: Core Java & JVM Languages
● Track: Software Architektur
The post CUPID ‒ for joyful coding! appeared first on JAX.
]]>The post Domain-Driven Design: Wie Domain Storytelling Fachexperten und Entwickler zusammenbringt appeared first on JAX.
]]>Hans betreibt ein kleines Arthouse-Kino, das unter Cineasten einen hervorragenden Ruf genießt. Vorführungen werden oft durch Filmanalysen ergänzt. Lokales Craft-Bier rundet das Kinoerlebnis ab. Eines Tages begegnet Hans seiner Schulfreundin Anna. Als er erfährt, dass Anna seit fast zehn Jahren Apps entwickelt, kommt ihm eine Idee.
Hans: „Meine Kunden mögen den altmodischen Charme meines Kinos. Aber keiner hat Lust, drei Tage vor einer Vorstellung an die Kasse zu kommen und Karten zu kaufen. Und dann gibt’s lange Gesichter, wenn eine Vorstellung ausverkauft ist. Kannst du nicht eine App für mich entwickeln?“
Anna: „Ein Kinosaal, zwei bis drei Vorführungen pro Tag, Karten verkaufen. Klingt machbar.“
Hans: „Super! Aber eine Kleinigkeit noch: Wir haben auch Vorträge von Filmkritikern im Programm. Und die Abendkasse brauche ich schon noch, komplett auf die App zu setzen ist mir dann doch zu riskant. Aber die Abos würde ich schon gern über die App verwalten.“
Anna: „Abos? Vorträge? Abendkasse? Das ist ja komplizierter als gedacht…“
Am nächsten Tag treffen sich die beiden wieder. Sie stehen vor einem Whiteboard, Anna hält einen Whiteboard-Marker in der Hand.
Anna: „Ich hab gestern verstanden, dass die App im Wesentlichen drei Anwendungsfälle hat: Abos verkaufen, Einzeltickets verkaufen und Tickets für Vorträge verkaufen.“
Hans: „Äh, ja, das klingt gut.“
Anna: „Ich würde gern verstehen, wie du heute arbeitest. Die App muss ja schließlich in deine Arbeitsabläufe reinpassen. Wollen wir vielleicht mal mit dem Ticketverkauf an der Abendkasse anfangen?“
Hans: „Das ist einfach. Man verkauft die Karten und streicht den Sitzplatz aus dem Saalplan und…“
Anna: „Warte mal. Wer verkauft die Karten?“
Hans: „Ich habe zwei Studenten, die bei mir jobben. Aber manchmal mach ich das auch selbst.“
Anna: „Okay, aber welche Rolle hast du dann?“
Hans: „Ach so, bei uns heißt das Kartenverkäufer.“
Anna malt ein Männchen an das Whiteboard und schreibt „Kartenverkäufer“ darunter (Abb. 1).
Abb. 1: Hans‘ Rolle ist „Kartenverkäufer“
Anna: „Und wer kauft die Karten?“
Hans: „Ein Besucher. Also einer ohne Abo.“
Anna malt ein zweites Männchen und nennt es „Besucher“. Am Rand notiert sie, dass der Besucher kein Abo hat (Abb. 2).
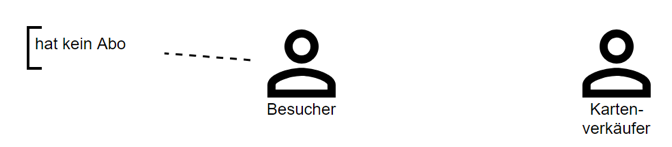
Abb. 2: Der „Besucher“ hat kein Abo.
Anna: „Was muss ich als Besucher tun, um eine Karte zu kaufen?“
Hans: „Du sagst dem Kartenverkäufer, welche Vorstellung du sehen willst. Also welchen Film an welchem Tag und welcher Zeit. Und wie viele Karten du haben willst.“
Anna: „Ich male hier eine Sprechblase, weil die beiden miteinander reden.“
Anna zeichnet weiter. An den Pfeil schreibt Anna eine Eins (Abb. 3).
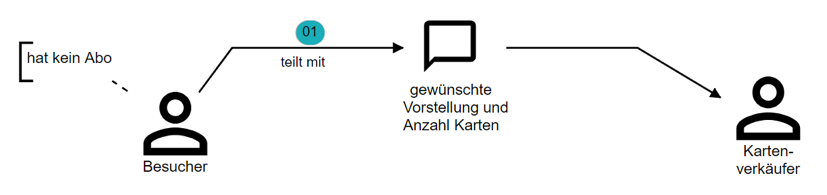
Abb. 3: Kartenverkäufer und Besucher kommunizieren
Anna: „Und dann?“
Hans: „Meistens schlägt der Kartenverkäufer die besten noch verfügbaren Sitzplätze vor.“
Anna: „Und wie macht der Kartenverkäufer das?“
Hans: „Man schaut auf den Saalplan der Vorstellung. Darauf sieht man, welche Sitzplätze schon verkauft sind und wo noch was frei ist.“
Anna zeichnet und wiederholt, was sie verstanden hat (Abb. 4).
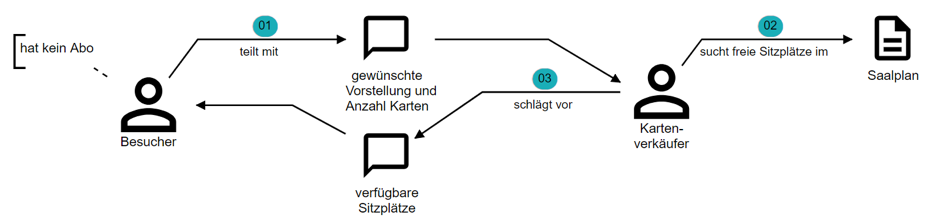
Abb. 4: Der Ticketverkäufer sucht nach freien Sitzplätzen für den Besucher
Anna: „Der Ticketverkäufer sucht im Saalplan nach der gewünschten Anzahl freier Sitzplätze. Stimmt das so?“
Innerhalb weniger Minuten füllt sich das Whiteboard mit einer fachlichen Geschichte, die erzählt, wie ein Kinobesucher Karten an der Abendkasse kauft (Abb. 5). Am Ende erzählt Anna die Geschichte noch einmal von vorne.
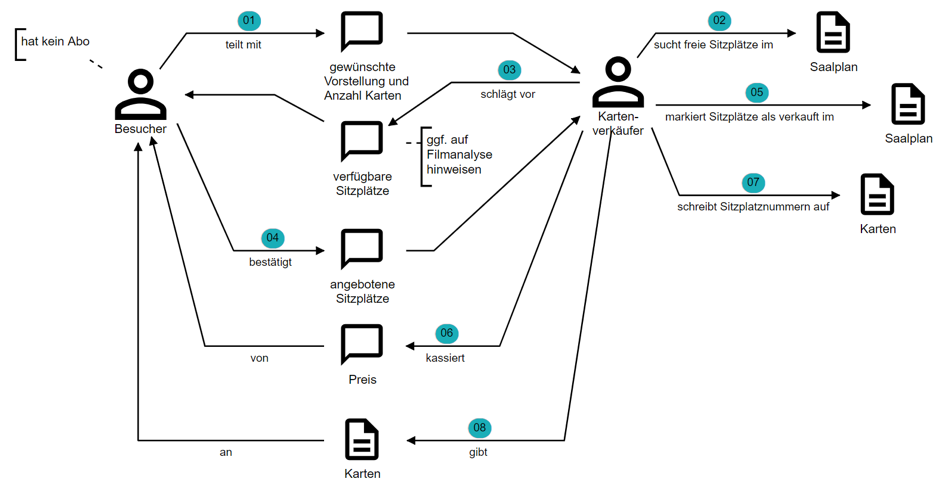
Abb. 5: Wie ein Besucher Karten an der Abendkasse kauft
Hans: „Ja, das passt so. Nur die Filmanalysen habe ich vergessen.“
Anna: „Du meinst das mit den Filmkritikern? Sind das nicht eigene Veranstaltungen?“
Hans: „Nein. Die Filmanalysen finden nach der Vorführung statt. Wir bieten das bei ein, zwei Vorführungen pro Woche an. Die sind dann etwas teurer. Extra verkaufen tun wir die Vorträge nicht, das wäre zu kompliziert. Man muss die Besucher nur darauf hinweisen, dass die Vorführung im Anschluss von einem Filmkritiker analysiert wird.“
Anna: „Wann macht der Kartenverkäufer das?“
Hans: „Hier.“
Hans zeigt auf den Pfeil mit der Nummer 3. Anna ergänzt einen Kommentar (Abb. 6).
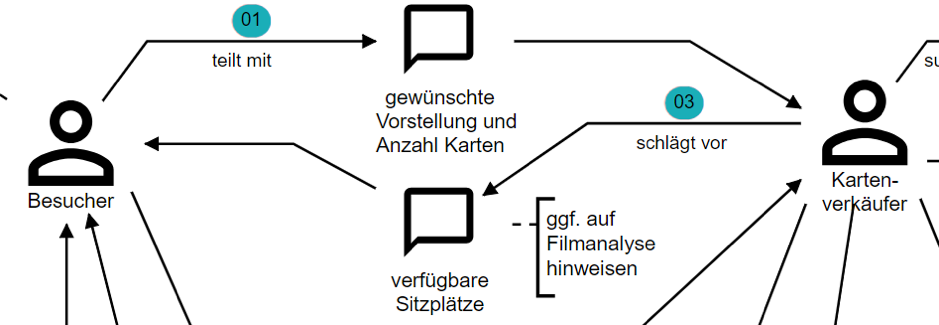
Abb. 6: Anna und Hans füllen ihr Modell mit Kommentaren
Anna: „Du verkaufst auch Abos. Wie funktioniert das?“
Anna dreht das Whiteboard um und Hans beginnt mit einer neuen Geschichte (Domain Story).
Nach wenigen Domain Stories hat Anna einen guten Einblick in die Domäne „Kino“ erlangt. Sie kennt Begriffe wie „Saalplan“, „Vorführung“ und „Kartenverkäufer“. Sie hat ein erstes Verständnis der wichtigsten Abläufe und kann sich nun Gedanken machen, was die Einführung einer App für diese Abläufe bedeuten würde.
Das Bild zur Geschichte
Es ist sehr einfach, jemandem zuzuhören und zu glauben, dass man ihn verstanden hat. Man nickt und stimmt zu – und hat dabei ein völlig anderes Bild im Kopf. Menschliche Kommunikation ist durch Missverständnisse geprägt. Deshalb unterstützt Domain Storytelling beim aktiven Zuhören. Wir lassen uns nicht nur einfach eine Geschichte erzählen. Beim Zuhören zeichnen wir die Domain Stories vor den Augen der Fachleute auf. Dazu verwenden wir bewusst einfache Symbole. Die Fachleute sehen unmittelbar, ob wir ihre Geschichte richtig wiedergeben können. Damit folgen wir dem agilen Grundprinzip des möglichst frühen Feedbacks.
Die Bildsprache besteht aus zwei Arten von Symbolen und einer Art von Pfeil (Abb. 7):
Actors – Die handelnden Personen und IT-Systeme einer Geschichte. Typischerweise benannt mit einer Rollenbezeichnung oder Persona.

Abb. 7.1: Der “Actor”-Teil der Bildsprache
Work Objects – Die Arbeitsgegenstände, mit denen die Akteure ihre Arbeit machen. Oft etwas, das man anfassen und sehen kann, wie der Saalplan. Manchmal auch ein vergegenständlichtes Konzept, wie die Vorstellung.

Abb. 7.2: Der “Work Object”-Teil der Bildsprache
Activities – Das, was die Akteure tun.
Abb. 7.3: Der “Activity”-Teil der Bildsprache
Durch die Symbole der Work Objects sehen wir, welche Informationen verbal ausgetauscht werden (Symbol: Gesprächsblase) und in welchen Schritten (digitale) Dokumente eine Rolle spielen (Symbol: Dokument). Die Symbole dienen also nicht bloß der Optik, sondern veranschaulichen wichtiges Wissen über den Prozess. Je nach Domäne werden die Symbole angepasst. In einem Logistikunternehmen ist beispielsweise ein Symbol für einen Container nützlich, wenn in der Domain Story dargestellt wird, dass Container verladen werden. Für diesen Artikel verwenden wir einige Google Material Icons [1], die gut zu typischen Bürotätigkeiten passen und sich in vielen Domänen bewährt haben.
Mit dieser einfachen Notation können wir leicht verständliche Sätze verbildlichen: „Der Kartenverkäufer sucht freie Sitzplätze im Saalplan“ wird zu Abbildung 8.
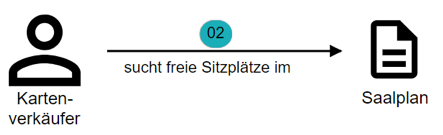
Abb. 8: Via Icons lassen sich Sätze leicht verbildlichen
Reiht man mehrere Sätze aneinander, entsteht eine Geschichte. Die Aktivitäten zu nummerieren drückt die Reihenfolge der Sätze aus. Da eine Geschichte ohne Fallunterscheidungen erzählt wird, benötigt die Bildsprache keine Symbole für Verzweigungen. Annahmen, Varianten und Ausnahmen einer Domain Story können als textuelle Notizen festgehalten werden. Wichtige Varianten, die sich nicht mit einer kurzen Notiz beschreiben lassen, verdienen eine eigene Domain Story.
Die Akteure sind der Dreh- und Angelpunkt einer Domain Story. Daher kommt jeder Akteur nur einmal pro Domain Story vor. Work Objects können hingegen mehrfach auftauchen, wenn sie zu unterschiedlichen Zeitpunkten der Geschichte eine Rolle spielen. Im Lauf der Geschichte können Work Objects durch unterschiedliche Symbole repräsentiert werden. In unserem Kinobeispiel könnte eine Kinokarte etwa erst digital als E-Mail verschickt und später auf Papier gedruckt werden.
Von der Erzählung zum Bild
Domain Stories werden in Workshops erzählt. Neben einem Moderator braucht es dazu Fachexperten, die aus erster Hand zur Geschichte beitragen können. In komplexen Domänen gibt es immer seltener eine einzelne Person, die eine Geschichte von Anfang bis Ende kennt. Deswegen versammelt man Vertreter verschiedener Fachabteilungen und der IT, die die Geschichte gemeinsam erzählen.
Domain Storytelling macht auf unterschiedliche Arten Spaß. Wenn man noch unerfahren ist, wird man es schätzen, wenn ein Moderator die Diskussion führt und zentral die Domain Story aufzeichnet. Häufig ist der Moderator der wichtigste Nutznießer der Domain Stories – etwa, wenn er als Product Owner, Softwareentwickler oder Businessanalyst das erworbene Wissen für ein Entwicklungsprojekt nutzt. Erfahrene Teams machen auch gerne Sessions, bei denen alle zusammen vor dem Whiteboard stehen und gemeinsam Pfeile malen und Zettel kleben.
Je nachdem, was mit dem Workshop bezweckt wird, müssen die Geschichten mal oberflächlich und breit und mal mit klarem Fokus und detailliert erzählt werden. Außerdem muss ein Moderator gegensteuern, wenn sich Diskussionen entwickeln, die das Fortschreiten der Geschichte verhindern. Ein typisches Beispiel: An einem Punkt der Geschichte diskutieren die Teilnehmer, was alles passieren könnte. Solche Diskussionen lassen sich auflösen, indem die Geschichte konkretisiert wird und Annahmen ergänzt werden: “Nehmen wir an, es sind genügend Sitzplätze nebeneinander frei. Was passiert als Nächstes?”. So verzetteln sich die Teilnehmer nicht in Sonderfällen.
Je nach Anzahl der Teilnehmer, verfügbarer Raumausstattung und der Anzahl an Domain Stories können unterschiedliche Werkzeuge zur Visualisierung eingesetzt werden. Flipcharts und Marker sind in den meisten Besprechungsräumen vorhanden. Leider sind Flipcharts am schlechtesten geeignet, weil Änderungen damit schwierig sind. Und weil man so oft missversteht, was eigentlich gemeint wurde, muss man Domain Stories häufig ändern. Deshalb hat sich als bisher gängigste Offlinevariante eine Kombination aus Whiteboard und Klebezetteln entwickelt (Abb. 9). Diese eignet sich auch sehr gut für kooperatives Domain Storytelling ohne dedizierten Moderator.
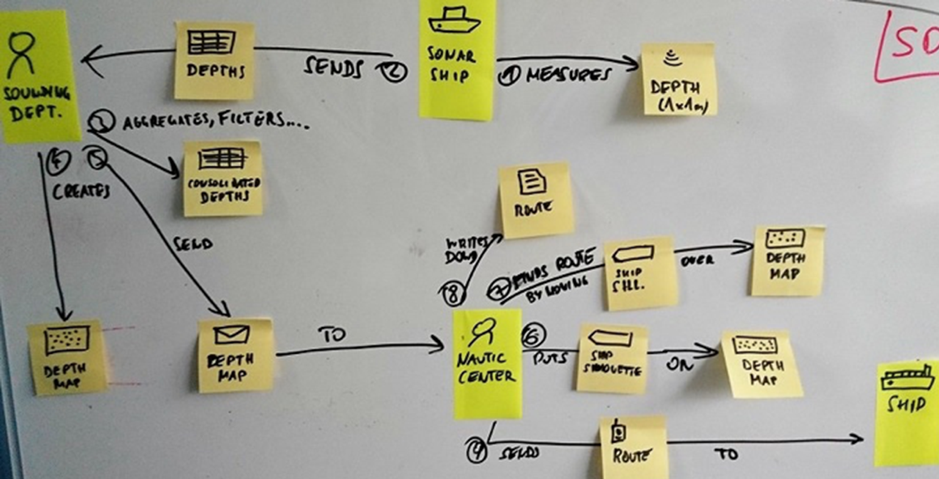
Abb. 9: Offlinevariante mit einer Kombination aus Whiteboard und Klebezetteln
Auch computergestützt gibt es einige Möglichkeiten, etwa mit Tablet und Stift oder auf Smartboards wie dem Surface Hub (Abb. 10). Generische Modellierungs- und Zeichenwerkzeuge eignen sich zwar, um Domain Stories nach einem Workshop zu digitalisieren, aber für den Einsatz in den Workshops selbst fühlen sich solche Werkzeuge oft zu sperrig an. Aus dieser Unzufriedenheit heraus entstand der Domain Story Modeler, ein Modellierungswerkzeug, das im Browser läuft. Einfach online ausprobieren [2] oder herunterladen [3]. Die Bilder für das einführende Kinobeispiel haben wir mit dem Modeler erstellt.
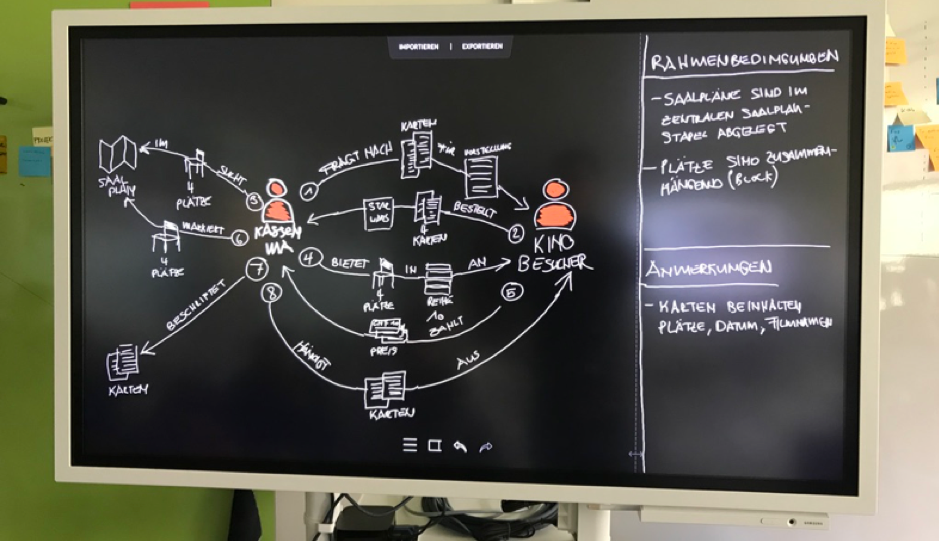
Abb. 10: Computergestützt stehen Tablet und Stift oder Smartboards wie das Surface Hub zur Verfügung.
Jedes Werkzeug hat seine Stärken und Schwächen. Egal, welches man verwendet – es ist wichtig, dass die Domain Story jederzeit für alle sichtbar ist. Nur so funktioniert Domain Storytelling als Methode für aktives Zuhören.
Am Ende geht es nicht um die Schönheit der visualisierten Domain Story, nicht um das perfekte Werkzeug und nicht um syntaktische Korrektheit. In den Workshops steht der gemeinsame Erkenntnisgewinn über dem Erstellen von Dokumentationen. Die abfotografierten oder digital erstellten Domain Stories dienen als Gedächtnisstütze für die Teilnehmer eines Workshops. Sie können die Teilnahme am Workshop aber nicht ersetzen.
Von Domain Stories zum Code
Wer nur einen Hammer als Werkzeug hat, sieht die Welt voller Nägel. In Entwicklungsprojekten reicht selten nur ein Modellierungsansatz aus. Wir starten zum Beispiel manchmal mit einem Big-picture-Event-Storming (siehe vorhergehender Artikel). Wenn wir dabei auf eine Häufung von Ereignissen stoßen, die von kooperativer Arbeit geprägt sind, nutzen wir im zweiten Schritt Domain Storytelling für eine tiefere Analyse.
Um eine Domäne zu verstehen und mit Fachexperten darüber zu sprechen, reicht es in der Regel aus, 80 Prozent der Fälle abzudecken: die wichtigsten, häufigsten, schwierigsten und aufwendigsten Varianten eines Geschäftsprozesses.
Aus diesem Verständnis heraus entstehen, oft parallel zur Softwareentwicklung, weitere Dokumente. Beispielsweise eignen sich Domain Stories, um Soll-Prozesse zu entwerfen. In unserem Kinobeispiel würden Hans und Anna visualisieren, wie der Verkaufsprozess an der Abendkasse in Zukunft abläuft. Sie werden dabei feststellen, dass die Kartenverkäufer einen digitalen Saalplan brauchen werden, der auch die per App verkauften Sitzplätze anzeigt (Abb. 11).
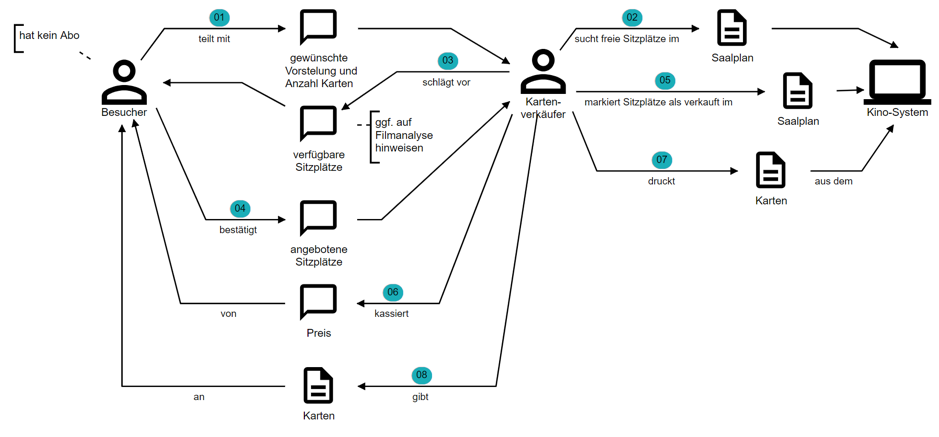
Abb. 11: Ein digitaler Saalplan zeigt auch per App verkaufte Karten an.
Aus solchen Domain Stories lassen sich leicht funktionale Anforderungen ableiten. Ein Beispiel: Will eine Besucherin unseres Kinos vor Ort Karten kaufen, sucht der Kartenverkäufer nach dem passenden Saalplan für die Vorstellung und bietet die freien Plätze an (Aktivitäten 2 und 3 in der Domain Story). Dazu kann man folgende Anforderung an das Kinosystem formulieren: “Als Kartenverkäufer will ich die freien Plätze für eine Vorstellung ermitteln, damit ich sie einem Besucher anbieten kann.”
Domain Storytelling und Domain-Driven Design
Domain Storytelling passt ideal zu Domain-Driven Design und unterstützt die drei Säulen des Domain-Driven Design (Kasten: „ Die drei Säulen des Domain-Driven Design“).
Die drei Säulen des Domain-Driven Design
Collaborative modeling: Im Domain-Driven Design tauchen Entwickler tief in die Domäne ein. Gemeinschaftliches Modellieren hilft allen Beteiligten, ein gemeinsames Verständnis der Domäne zu entwickeln. Domain Storytelling eignet sich als Ergänzung oder Alternative zu anderen Techniken des gemeinschaftlichen Modellierens wie Event Storming und Szenarien.
Strategic design: Je mehr Details man über eine Domäne lernt und modelliert, desto komplexer und mehrdeutiger werden die Modelle. Im Domain-Driven Design behalten wir Überblick und Konsistenz, indem wir die Domäne in Bounded Contexts aufteilen. Jeder Bounded Context hat sein eigenes Modell der Domäne und schlussendlich seine eigene Fachsprache. Domain Stories helfen dabei, fachlich sinnvolle Grenzen zwischen Kontexten zu ziehen.
Modeling in code: Das Modell der Domäne soll sich nicht nur in Dokumenten und den Köpfen aller Beteiligten wiederfinden, sondern auch im Code. Domain-Driven Design beschreibt Muster, wie sich verschiedene Konzepte einer Domäne in Code abbilden lassen. Domain Stories geben Hinweise darauf, wie diese Abbildung zu erfolgen hat. Beispielsweise sind die Work Objects gute Kandidaten für Entities und Aggregates (zwei Entwurfsmuster des Domain-Driven Design).
Überspannt werden diese drei Säulen vom Konzept der Ubiquitous Language. Diese haben wir als Fachsprache innerhalb eines Bounded Contexts bezeichnet. Diese Fachsprache soll allgegenwärtig (engl. ubiquitous) sein – vom Whiteboard bis hinein in den Code. Domain Storytelling hilft dabei, die Worte zu finden, die die Ubiquitous Language formen. Diese Worte werden wir später auch im Code wiederfinden.
Zum Schluss: Domain Storytelling lernen und selbst machen
Domain Storytelling ist eine einfache Technik. Um sie aber auch in größeren Gruppen sicher anwenden zu können, braucht man als Moderator etwas Erfahrung. Die bekommt man nur durch Übung. Wir empfehlen daher, erstmal klein anzufangen. Probieren Sie Domain Storytelling allein, mit Stift und Papier oder online mit dem Modeler. Wenn Sie die Notation verinnerlicht haben, schnappen Sie sich eine Kollegin oder einen Kollegen, um die Rolle des Fachexperten zu übernehmen. Üben Sie, wie Domain Storytelling im Dialog funktioniert. Danach sind Sie bereit für Workshops mit mehreren Teilnehmern.
Mehr zu Domain Storytelling finden Sie auf: http://domainstorytelling.org.
Cheat-Sheet: Die neuen JEPs im JDK 12

Unser Cheat-Sheet definiert für Sie, wie die neuen Features in Java 12 funktionieren. Von JEP 189 „Shenandoah“ bis JEP 346 „Promptly Return Unused Committed Memory from G1“ fassen wir für Sie zusammen, was sich genau ändern wird!
Links & Literatur
[1] Google Material Icons: https://material.io/icons/
[2] Domain Story Modeler ausprobieren: wps.de/modeler
[3] Domain Story Modeler auf GitHub: https://github.com/WPS/domain-story-modeler
The post Domain-Driven Design: Wie Domain Storytelling Fachexperten und Entwickler zusammenbringt appeared first on JAX.
]]>The post Was Sie bei der Einführung von APIs wissen sollten appeared first on JAX.
]]>Arne Limburg: Das hat mehrere Aspekte. Da ist zum Einen der technologische Aspekt. Moderne REST-APIs sind viel schlanker als frühere Lösungen wie SOAP oder XML-RPC und das sowohl im Design als auch bei der Datenmenge, die über die Leitung geht.
Dann gibt es natürlich den architektonischen Aspekt. Man hat mittlerweile erkannt, dass Architekturen, die auf einem ESB basieren, nicht so leicht zu warten und weiterzuentwickeln sind, als wenn sich die Services direkt unterhalten. Damit das gelingt, benötigt man aber gute APIs, die auch stabil bleiben. Da spielt das Thema Abwärtskompatibilität und Versionierung eine wichtige Rolle.
Und last but not least haben viele Unternehmen erkannt, dass sich mit gut definierten Public APIs auch Geld verdienen lässt. Unternehmen erschließen sich neue Vertriebskanäle, in dem sie APIs anbieten, über die z.B. Mobile Clients angebunden werden können (Stichwort: Multi-Channel-Strategie). Die Clients müssen dann nicht immer vom Unternehmen selbst gebaut werden. Es gibt auch interessante Konstellationen, in denen Drittanbieter an dem Unternehmensumsatz partizipieren können.
W-JAX: Deine Session auf der W-JAX heißt „Abwärtskompatible APIs – Strategien für den Projektalltag.“ Dabei gehst du darauf ein, wie man Schnittstellen sinnvoll weiterentwickelt, wenn sich beispielsweise die Anforderungen verändert haben. Warum genügt es nicht einfach, eine Versionierung für APIs einzuführen?
Arne Limburg: Es geht vor allem um die Pflege alter Versionen. Wenn ich ein Public API betreibe, kann ich nicht einfach eine Version 2 des API zur Verfügung stellen und Version 1 abschalten. Damit erzeuge ich hohen Aufwand bei meinen Clients, die dann zeitgleich updaten müssten. Auf Dauer macht das kein externer Client-Anbieter mit.
Die Erfahrung zeigt aber, dass die Pflege alter Versionen serverseitig sehr aufwendig ist, wenn man es nicht richtig angeht. Es geht also darum, einen Weg zu finden, serverseitig alte Versionen einfach pflegen zu können und gleichzeitig den Clients leichte Wege zu eröffnen, auf die neueste Version zu aktualisieren.
W-JAX: Kannst du einmal einen Tipp geben, wie man Abwärtskompatibilität von APIs sicherstellen kann, ohne sich im Support alter Versionen zu verlieren?
Arne Limburg: In aller Ausführlichkeit erkläre ich das natürlich in meinem Talk auf der W-JAX. Kurz gesagt, geht es darum, einerseits gewisse Anforderungen an den Client zu stellen (Stichwort: Tolerant Reader Pattern) aber andererseits auf dem Server auch dafür zu sorgen, dass die API kompatibel bleibt, in dem innerhalb einer Version nur Attribute hinzukommen, aber niemals welche entfernt werden. Beim Versionssprung ist es wichtig, dass das Mapping zwischen alter und neuer Version nicht zu aufwendig ist.
W-JAX: In den meisten Fällen haben Unternehmen noch Legacy-Systeme am Laufen, die bei der Einführung von APIs integriert werden müssen. Welche technologischen Herausforderungen gilt es dabei zu meistern?
Arne Limburg: Hier gibt es zwei Arten von Legacy-Systemen. Für die einen ist das Unternehmen im Besitz des Source Codes und hat auch das Know-How, um die Systeme weiterzuentwickeln. Hier empfehlen wir immer, ein sauberes RESTful API für das Legacy-System zu realisieren, um es in die „neue Welt“ einzubinden. Häufig ist das gar nicht so schwer.
Sollte sich das nicht realisieren lassen, empfehlen wir einen Anti-Corruption-Layer, der dann die saubere Schnittstelle zur Verfügung stellt und eigentlich nichts anderes macht als zwischen Legacy und neuer Welt hin- und herzumappen. Das kann dann z.B. auch ein Caching beinhalten, wenn das Legacy-System nicht auf eine so hohe Anzahl von Requests ausgelegt ist oder wenn es sogar nur im Batch-Betrieb läuft.
W-JAX: Bei der Einführung von APIs bleibt es aber ja nicht bei den technologischen Herausforderungen. Weshalb hat das auch Konsequenzen auf die gesamte Organisation eines Unternehmens?
Arne Limburg: In vielen Unternehmen ist es nach wie vor so, dass die Entwicklung sehr Projekt-getrieben ist. Die Einführung eines neuen Features ist ein eigenes Projekt, für das es ein separates Budget gibt und häufig auch noch ein Plichten- und Lastenheft.
Moderne APIs müssen allerdings als Produkt betrieben werden, das kontinuierlich weiterentwickelt wird und auf diese Weise benötigte Features zur Verfügung stellt. Die Art und Weise, wie neue Themen in die IT eingebracht werden, muss sich daher häufig komplett ändern.
W-JAX: Wie sollte man ein API-basiertes Projekt deiner Erfahrung nach angehen? Es gibt da ja verschiedenste Ansätze: Startet man technologisch, oder muss man zuerst das Unternehmen umstrukturieren? Braucht es zunächst ein ausgefeiltes Konzept zum API Management, oder ist der MVP-Ansatz hier besser: erstmal klein starten, Feedback einholen, weiterentwickeln?
Arne Limburg: Das Vorgehen, erst einmal klein anzufangen, um Erfahrung zu sammeln, ist auf jeden Fall ein Vorgehen, das sich bewährt hat. Dennoch sollte man sich beim Design einer API nicht von der Technologie treiben lassen. Es geht ja nicht primär darum, wie ich den Server schnell realisieren kann, sondern darum, eine API so aufzubauen, dass viele unbekannte Clients sie leicht nutzen können und gerne nutzen. Mein Ansatz ist deshalb immer der sogenannte Contract-First-Ansatz, wobei der Name etwas irreführend ist, weil er nicht das Ziel widerspiegelt. Eigentlich müsste man den Ansatz Client-First nennen. Gute APIs sind in der Regel die, bei denen das Design mit der Überlegung ausgeführt wurde: Was benötigt der Client?
W-JAX: Vielen Dank für dieses Interview!
Sessions von Arne Limburg auf der W-JAX 2018:
● Abwärtskompatible APIs – Strategien für den Projektalltag
● Reactive Enterprise Java
Cheat-Sheet: Die neuen JEPs im JDK 12
Unser Cheat-Sheet definiert für Sie, wie die neuen Features in Java 12 funktionieren. Von JEP 189 „Shenandoah“ bis JEP 346 „Promptly Return Unused Committed Memory from G1“ fassen wir für Sie zusammen, was sich genau ändern wird!
The post Was Sie bei der Einführung von APIs wissen sollten appeared first on JAX.
]]>The post Einmal als Container verpacken? – Java im Zeitalter von Kubernetes appeared first on JAX.
]]>Die Java Virtual Machine (JVM) ist über die Jahre zu einer einzigartigen Laufzeitumgebung gereift, die insbesondere mit Serveranwendungen mit einer überragenden Performanz besticht. Dabei ist die JVM hochgradig optimiert für langlaufende und exklusive Serveranwendungen, die lange das vorrangige Betriebsmodell für Java-basierte Backend-Anwendungen war. Diese Optimierungen wurden vorrangig auf Kosten der Start-up-Zeit und des Hauptspeicherverbrauchs realisiert. Nachdem Microservices- und Container-basierte Betriebsmodelle in den letzten Jahren in den Vordergrund rücken, sind es heute vor allem viele potenziell kurzlebige Prozesse, die auf Plattformen wie Kubernetes elastisch skaliert werden.
Lesen Sie für weitere Erläuterungen zum Thema die beiden Textkästen „ Kurz & Knapp – Microservices mit Docker“ sowie „ Kurz & Knapp – Kubernetes“.
Kurz & Knapp – Microservices mit Docker
Vor nicht allzu langer Zeit führten viele von uns den Kampf gegen diese großen, monströsen Monolithen, die das Übel der gesamten IT-Welt in sich zu vereinen schienen. Riesige Entwicklerteams, lange Releasezyklen, irrsinniger Synchronisationsaufwand vor jedem Update, Monsterrollbacks bei fehlgeschlagenen Rollouts, all diese Merkmale klassischer Monolithen haben zu einiger Frustration bei uns Entwicklern geführt.
Das war die Geburtsstunde der Microservices, bei denen Geschäftslogik in kleine Portionen in dedizierte Services gekapselt wird und sich so von separaten, überschaubaren Teams entwickeln lässt. Die Vorteile dieses Ansatzes liegen auf der Hand: Überschaubare Codebasis, keine Kompromisse bei der Auswahl des Technologiestacks, individuelle und unabhängige Releasezyklen und kleinere, fokussierte Teams.
Der Wechsel auf eine verteilte Anwendung im Microservices-Stil hat jedoch auch ihren Preis: APIs müssen abgestimmt werden, Services können jederzeit wegbrechen, Backpressure-Effekte bei vielen abhängigen Services und natürlich die erhöhte Komplexität bei der Verwaltung vieler Services sind wohl die wichtigsten Herausforderungen einer Microservices-basierten Architektur.
Dennoch scheint es, dass die gesamte IT-Welt auf den Microservices-Zug aufgesprungen ist. Natürlich wird, wie immer, das Pendel bald zurückschlagen und wir werden auf die harte Tour lernen müssen, dass Microservices nicht alle Probleme dieser Welt lösen. Neben der Problematik, dass wir uns nun um verteilte Systeme kümmern müssen, ist es, wie schon erwähnt, vor allem die schiere Menge der Services, die den Betrieb erschwert. Die Komplexität eines Monolithen löst sich nicht einfach durch einen Architekturwechsel in Nichts auf.
Zufällig oder nicht, parallel zur dieser Architekturrevolution hat sich auch ein Betriebsmodell herauskristallisiert, das wie Deckel auf Topf zu Microservices passt. Gemeint ist der Betrieb von Applikationen in uniformen Containern, der dank Dockers überragender User Experience nun auch für Normalsterbliche auf einfache Weise benutzbar geworden ist.
Nun können Entwickler (Dev) einfach einen Microservice in einen Container stecken, egal mit welcher Technologie er entwickelt wurde. Wie immer sind bei der Bestückung mit Java-Anwendungen jedoch ein paar Besonderheiten zu beachten, auf die wir im Folgenden detailliert eingehen werden.
Die Administratoren (Ops) können dann wiederum solche Container betreiben, ohne sich im Detail damit zu beschäftigen, welche Technologie genau darin enthalten ist. Diese Eigenschaft, die Linux-Container tatsächlich mit realen Frachtcontainern aus der Schiffahrt teilen, liefert eine ausgezeichnete technische Schnittstelle für die Kommunikation zwischen Dev und Ops, sodass die Containerisierung ein integraler Bestandteil der DevOps-Bewegung geworden ist.
Kurz & Knapp – Kubernetes
Wer eine ganze Flotte an Containern betreiben muss, braucht die Unterstützung einer Orchestrierungsplattform für Container. Genau das ist die Aufgabe von Kubernetes, das sich mittlerweile als De-facto-Standard auf dem Markt etabliert hat.
Das Open-Source-Projekt Kubernetes wurde 2014 von Google gestartet und hat als Ziel, der Allgemeinheit die Erfahrungen zur Verfügung zu stellen, die Google mit der eigenen internen Containerplattform Borg gewonnen hat.
Einige Kerneigenschaften von Kubernetes sind:
• Die optimierte Verteilung von Containern auf einen Cluster von Linux-Maschinen (Nodes)
• Horizontale Skalierung, auch automatisch
• Selbstheilung
• Service Discovery, damit sich Microservices gegenseitig leicht finden können
• Support für verschieden Updatestrategien
• Verteilte Volumes zum Persistieren von Daten
• Router und Loadbalancer zum Zugriff auf Dienste von außerhalb des Clusters
Insbesondere die Eigenschaft der sogenannten Selbstheilung ist es wert, etwas näher betrachtet zu werden. Dazu muss man wissen, dass Kubernetes ein deklaratives Framework ist, bei dem man beschreibt, wie ein Zielzustand aussehen soll. Das steht im Gegensatz zu einem imperativen Framework, bei dem die einzelnen Schritte beschrieben werden, die dann letztendlich zu dem gewünschten Zustand führen. Die Beschreibung des Zielzustands hat zum Vorteil, dass Kubernetes den aktuellen Zustand periodisch mit dem Zielzustand abgleichen kann. Weicht der aktuelle vom gewünschten Zustand ab, führt Kubernetes Aktionen durch, um die Vorgabe wieder zu erreichen. Diesen Prozess nennt man Reconciliation – eine der wichtigsten Eigenschaften von Kubernetes.
Wie aber wird dieser Zielzustand beschrieben? Das geschieht mithilfe sogenannter Resource-Objekte. Diese Objekte, die sich im JSON- oder YAML-Format beschreiben lassen, werden über ein generisches REST API am Kubernetes-API-Server verwaltet. Dieses API kennt die klassischen CRUD-Operationen (Create, Retrieve, Update, Delete). Alternativ besteht auch die Möglichkeit, sich via WebSockets für Resource-Events zu registrieren.
Die grundlegende Resource ist hierbei der Pod, der eine Verallgemeinerung eines Containers darstellt. Ein Pod kann entweder einen oder auch mehrere Container enthalten und ist das Kubernetes-Atom. Container, die in einem Pod zusammengefasst sind, haben den gleichen Lebenszyklus, d. h., sie leben und sterben gemeinsam. Container innerhalb eines Pods können sich außerdem gegenseitig sehen und teilen sich den Netzwerkraum, sodass die Prozesse in den Containern einander über localhost erreichen können. Zusätzlich können Pod-Container sich auch Volumes teilen, sodass auch darüber Dateien ausgetauscht werden können.
Jeder Pod hat eine eigene, flüchtige IP-Adresse innerhalb des Kubernetes-privaten Netzwerks. Auf diese IP-Adresse kann von außerhalb nicht zugegriffen werden, was auch tatsächlich keinen Sinn ergeben würde, da ein Pod bei einem Neustart eine neue IP-Adresse zugewiesen bekommt.
Services ermöglichen es, mit einer stabilen Adresse auf die Container eines Pods über das Netzwerk zuzugreifen. Dabei kann man sich einen Service wie einen Reverse Proxy oder Load Balancer vorstellen, der vor den Pods steht. Ein Service ist zugleich ein virtuelles Konstrukt ohne Lebenszyklus und wird beispielsweise über eine reine Netzwerkkonfiguration realisiert. Ein Microservice spricht mit einem anderen Microservice nur über Services. Jeder Service hat dabei einen Namen, über den er über einen internen DNS-Server gefunden werden kann.
Da Services zwar eine permanente, aber auch nur intern zugängliche IP-Adresse besitzen, bedarf es einer weiteren Ressource: Mit Ingressobjekten kann der Zugriff von außerhalb des Kubernetes-Clusters auf Services realisiert werden. Dabei kann man sich ein Ingressobjekt als eine Art Konfiguration eines dynamisch konfigurierbaren Load Balancer vorstellen.
Wie eingangs erwähnt, verfügt Kubernetes über selbstheilende Eigenschaften. Das bedeutet, dass ein Pod, der sich ungewollt verabschiedet, automatisch wieder neu gestartet wird. Wie aber funktioniert das genau? Pods haben ein sogenanntes ReplicaSet als Babysitter. Typischerweise wird ein Pod nämlich nicht direkt vom Benutzer über das Kubernetes API erzeugt, sondern mithilfe eines ReplicaSet. Dieses ReplicaSet ist wiederum eine Ressource, die eine Pod-Beschreibung enthält und spezifiziert, wie viele Kopien dieses Pod erzeugt werden sollen. Im Hintergrund werkelt nun ein sogenannter Controller, der periodisch überprüft, ob die konfigurierte Anzahl an Pods tatsächlich läuft. Falls das nicht der Fall ist, werden entweder Pods beendet oder aber neue aus der mitgelieferten Pod-Beschreibung erzeugt.
Neben diesen gerade vorgestellten vier Ressourcentypen gibt es noch eine Vielzahl weiterer Arten, die verschiedene Konzepte oder Patterns repräsentieren. Die Grundidee bleibt aber stets die gleiche: Eine Ressource beschreibt ein Konzept und kann über das REST API verwaltet werden. Die Menge der Ressourcen nennt man auch die Data Plane. Mit der sogenannten Control Plane, die aus einer Vielzahl von Controllern besteht, werden diese Ressourcen ausgewertet und überwacht. Es ist Aufgabe der Control Plane, einen gewünschten Zielzustand herzustellen, wenn der aktuelle Zustand von diesem abweicht.
Aufgrund dieser Vorgeschichte ist Java aktuell als Cloud-Laufzeitumgebung klar im Nachteil gegenüber Sprachen wie Golang oder auch interpretierten Sprachen wie etwa Python, die deutlich zügiger starten und bei vergleichbarer Funktionalität bis zu zehnmal weniger Arbeitsspeicher benötigen.
Zum Glück gibt es Initiativen wie GraalVM [1] von Oracle, die hier aufzuholen versuchen. In unserem Zusammenhang wollen wir uns aber insbesondere the Substrate VM näher ansehen. Diese spezielle VM verwendet das so genannte Verfahren „Ahead-of-Time Compilation“ (AOT), um vorab Java-Bytecode in native Programme zu kompilieren. Obwohl es insbesondere Limitierungen in Bezug auf dynamische Eigenschaften wie Reflection oder dynamisches Classloading gibt, klappt das in vielen Fällen schon erfreulich gut. Frameworks wie Spring arbeiten eifrig daran, kompatibel zu Substrate VM zu werden [2].
Bis sich diese neuartigen JVMs in Produktion einsetzen lassen, wird es noch einige Zeit dauern. Die produktiv am häufigsten eingesetzte Java VM sind immer noch die auf OpenJDK 8 basierenden Distributionen. Um diese erfolgreich in Containern betreiben zu können, müssen einige Details beachtet werden, insbesondere was die Speicher- und Threadkonfiguration betrifft.
Java 8 verwendet bei der Berechnung von Defaultwerten für den Heap-Speicher oder die Anzahl der internen Threads als Basis den insgesamt vorhandenden Hauptspeicher bzw. die Anzahl der zur Verfügung stehenden CPU Cores. Kubernetes und Docker können die den Containern zur Verfügung stehenden Ressourcen begrenzen. Das ist eine wichtige Eigenschaft, die es Orchestrierungsplattformen wie Kubernetes ermöglicht, die Resourcen optimal zu verteilen.
Nun ist es aber leider so, dass ein Java-Prozess, der innerhalb eines Containers gestartet wird, dennoch immer den gesamten Hauptspeicher und die gesamte Anzahl der Cores eines Hosts sieht, ganz unabhängig von den gesetzten Containergrenzen. Das führt dazu, dass beispielsweise der Defaultwert für den maximal verwendbaren Hauptspeicher viel zu groß gewählt wird, sodass die von außen eingestellte, harte Begrenzung erreicht wird, ohne das die JVM z. B. mit einer Garbage Collection wieder Speicher freigeben kann. Das Ergebnis sind Out-of-Memory-(OOM-)Fehler, die dazu führen, dass der Container hart beendet wird. Das gleiche gilt ebenfalls für die Anzahl der zur Verfügung stehenden Cores: Wenn beispielsweise auf einer Machine mit 64 Cores ein Java-Container gestartet wird, der auf zwei Cores begrenzt ist (z. B. mit der Docker Option –cpus), dann wird die Java VM dennoch 64 Garbage-Collector-Threads starten, für jeden Core einen. Jeder dieser Threads benötigt wiederum standardmäßig 1 MB Speicher, sodass hier 62 MB extra verbraten werden, was zu dem kuriosen Effekt führen kann, dass eine Applikation auf dem Desktop funktioniert, nicht jedoch, wenn es in einem Cluster mit gut ausgestatteten Knoten wie GKE läuft. Auch andere Applikationen wie Java EE Server benutzen die Anzahl der Cores, die von Runtime.getRuntime().getAvailableProcessors() fälschlicherweise zurückgeliefert wird. So startet z. B. Tomcat für jeden sichtbaren Core einen eigenen Listener Thread, um HTTP-Anfragen zu beantworten.
Die von Java getroffene Annahme bei der Berechnung der Defaultwerte, sämtliche Ressourcen eines Hosts alleine zur Verfügung zu haben, ist generell infrage zu stellen. In einer containerisierten Laufzeitumgebung ist sie tatsächlich fatal.
Zum Glück gibt es seit JDK 8u131+ (und JDK 9) die Option XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap, die die JVM dazu veranlasst, tatsächlich die via cgroups gesetzten Speichergrenzen zu honorieren. Mit Java 10 werden die cgroups-Limits dann automatisch übernommen, was auch die für die CPU-Anzahl gilt.
Unabhängig von diesen Verbesserungen ist es dennoch zu empfehlen, die Werte für den maximalen Heap-Speicher und Threadkonfigurationen, die sich auf die Anzahl der Cores stützen, explizit zu setzen. Dabei hilft z. B. ein Java-Start-up-Skript wie run-java.sh [3], das unabhängig von der verwendeten Java-Version sinnvolle Defaultwerte setzen kann. Die fabric8 Java Basisimages [4] enthalten bereits dieses Skript und können direkt als Grundlage für containerisierte Java-Anwendungen verwendet werden.
Nach den eher technischen Besonderheiten, die beim Betrieb von Java in Containern im Allgemeinen zu beachten sind, stellt sich natürlich die Frage, wie man Java am besten in Container packen kann. Ein Java-Container-Image unterscheidet sich zunächst einmal nicht besonders von den Images anderer Applikationen: Es ist ein Image, das eine JVM enthält und das einen bytecompilierten Java-Code ausführt.
Es gibt jedoch viele verschiedene Wege, wie diese Java-Images gebaut werden können. Neben dem klassischen Ansatz mit docker build und einem Dockerfile gibt es weitere Variationen, die zum Teil auch gleich dabei helfen, Kubernetes-Resource-Deskriptoren zu erzeugen.
Lesen Sie auch: Grundkurs Microservices: Warum Frameworks nicht genug sind
Container packen mit Maven
Für die vorherrschenden Java-Buildsysteme Maven und Gradle existieren verschiedene Plug-ins, die das Bauen von Java-Container-Images in den Buildprozess integrieren können. Mit dem docker-maven-plugin [5] lassen sich die Images auf verschiedene Weise konfigurieren. Neben der empfohlenen Konfiguration mit einem Dockerfile existiert auch eine eigene XML-Syntax, die mit einer Maven Assembly zur Definition der Containerdaten arbeitet. Maven-Artefakte können direkt im Dockerfile referenziert werden, und für die einfachen Fälle bedarf es neben dem Dockerfile auch keiner weiteren Konfiguration. Zusätzlich zum Bauen von Docker-Images erlaubt das docker-maven-plugin auch das Starten von Containern, was beispielsweise für integrierte Integrationtests recht nützlich ist.
Das fabric8-maven-plugin [6], das auf dem docker-maven-plugin basiert, geht indes noch einen Schritt weiter. Die Idee dieses Plug-ins besteht darin, dass zwar lokal gebaut, jedoch die Anwendung direkt in einem Kuberntes-Cluster auch während der Entwicklung deployt wird. Durch Introspektion ist es diesem Plug-in möglich, gänzlich ohne Konfiguration auszukommen, sofern ein gängiger Technologiestack wie Spring Boot, Vert.x, Thorntail, Java EE WAR, generelle Java Fat Jars oder Karaf verwendet wird. Anhand der vorhandenen Konfiguration kann das fabric8-maven-plugin eigenständig Docker-Images mit vorausgewählten Basisimages erzeugen.
Darüber hinaus hilft dieses Plug-in bei der Erstellung der Kubernetes-Deployment-Deskriptoren. Im Zero-Konfigurationsmodus werden Annahmen über die Applikation getroffen. Standardmäßig werden ein Deployment und ein Service-Objekt erzeugt, dass das gebaute Docker-Image referenziert. Die Konfiguration kann aber auch über sogenannte Fragmente weitläufig angepasst werden. Spezielle Maven Goals wie fabric8:debug und fabric8:watch helfen beim Debugging und automatischen Redeployment der zu entwickelnden Anwendung im Cluster.
Im Artikel „Von Null auf Kubernetes“ (in der aktuellen Ausgabe des Java Magazins) wird dieses Plug-in anhand eines Beispiels ausführlich vorgestellt.
Eine weitere interessante Build-Integration mit Maven und Gradle bietet Jib [7]. Ziel von Jib ist es ebenfalls, das Bauen von Docker Images in den regulären Buildprozess zu integrieren. Dabei stehen neben dem eigentlich Bauen des Images zwei Eigenschaften im Vordergrund: Geschwindigkeit und Reproduzierbarkeit.
Geschwindigkeit wird durch das Aufteilen der Applikation in verschiedene Schichten realisiert – normalerweise muss bei Codeänderungen nur eine davon gebaut werden. Das klappt allerdings nur für bestimmte Klassen von Anwendungen.
Falls sich der Inhalt einer dieser Schichten nicht ändert, wird sie nicht neu gebaut. Somit können die Images reproduzierbar wieder erzeugt werden, da Jib Zeitstempel und andere buildspezifische Daten herausfiltert.
Jib arbeitet mit einem sogenannten Daemonless Build, bei dem es keines Docker Daemon bedarf. Dabei werden alle Imageschichten und Metadaten lokal im Docker- oder OCI-Format erzeugt. Das Ganze passiert direkt aus dem Java-Code des Plug-ins heraus, ohne eine externes Tool zu verwenden.
Eine Bedingung für die effektive Nutzung von Jib ist, dass das Projekt eine spezielle Struktur für die Paketierung als sogenannte Flat Classpath App mit einer Main-Klasse, Abhängigkeiten in Form von JAR-Dateien und Resource-Dateien wie Properties, die aus dem Classpath gelesen werden. Das Gegenstück dazu sind Fat Jars, die all diese Artefakte in einem einzigen JAR vereinigen. Spring Boot hat das Fat-Jar-Format als Paketierung übrigens populär gemacht. Jib dagegen stellt sich auf den Standpunkt, dass das Docker Image selbst die eigentlich Paketierung repräsentiert, sodass am Ende wiederum nur ein einzelnes Artefakt (in diesem Fall das Image) gemanagt werden muss.
Flat Classpath Apps haben so einige Nachteile, aber immerhin den einen großen Vorteil, dass sie erlauben, die verschiedenen Artefakte in verschiedene Schichten des Docker-Images zu organisieren. Dabei werden die am wenigsten veränderlichen (wie z. B. die Abhängigkeiten) in eine tiefere Schicht des Layerstacks gelegt, so dass dieser nicht neu gebaut werden muss, sofern sich an den Abhängigkeiten nichts ändert. Und genau das macht Jib: Es steckt alle Jars, von denen die Anwendung abhängt, in eine Schicht, alle Resource-Dateien in eine andere, und die eigentlichen Applikationsklassen in eine dritte. Die drei Schichten werden lokal gecacht. Somit ist ein erneutes Bauen der Images, bei denen sich nur der Applikationscode ändert, viel schneller möglich, als wenn jedes Mal ein einzelnes Fat Jar gebaut werden müsste, das natürlich auch nach jedem Bauen anders aussehen würde.
Damit ist Jib sehr schnell für inkrementelle Builds von Flat Classpath Apps, da Artefakte mit unterschiedlicher Volatilität in unterschiedlichen Schichten gepuffert werden. Dass zudem kein Docker Daemon erforderlich ist, reduziert die Anforderungen an das Buildsystem, erhöht aber andererseits auch die Sicherheit, da das Bauen des Images keine Root-Berechtigungen mehr benötigt.
Der Nachteil besteht aber darin, dass Jib tatsächlich nur für die angesprochenen Flat Classpath Apps Sinn ergibt. Spring-Boot-, Thorntail- und Java-EE-Anwender schauen also erst einmal in die Röhre, da diese auf Fat Jars oder WAR als Paketierungsformat setzen. Für Spring Boot gibt es mit dem Spring Boot Thin Launcher [8] eine alternative Paketierung, ebenso wie die Hollow Jars [9] für Thorntail. Diese Technologien wären prinzipiell auch für einen Einsatz mit Jib geeignet, bislang fehlt jedoch eine entsprechende Unterstützung. Außerdem ist der Start-up der Anwendung hart kodiert mit einem einfachen Aufruf von Java. Es gibt keine Möglichkeit, ein optimiertes Start-up-Skript wie das angesprochene run-java-sh einzubinden. Bei der Verwendung von Jib ist auch die Verwendung von XML-Konfiguration Pflicht, da keine Dockerfiles unterstützt werden.
Wenn also das Projekt passt (flat classpath), dann sollte man sich Jib unbedingt anschauen, ansonsten sind sicher die anderen Buildintegrationen besser geeignet.
Cloud-native Java-Patterns
Um die Vorzüge von Kubernetes voll auszuschöpfen, bedarf es allerdings mehr als einfach nur Java-Anwendungen in Container zu packen. Dazu müssen die Möglichkeiten, die die Infrastruktur bereitstellt, bei der Programmierung direkt miteinbezogen werden.
Es haben sich eine ganze Reihe von Mustern herausgebildet, die Best Practices für die Programmierung und den Betrieb von Anwendungen auf Kubernetes einfangen. Dabei ist auch zu betonen, dass Kubernetes selbst eine Manifestierung langjähriger Erfahrungen und Muster des orchestrierten Containerbetriebs darstellt.
In den folgenden Abschnitten werden wir einige dieser Muster vorstellen. Darüber hinaus seien die weiterführenden Publikationen [10], [11] nahegelegt, die die folgenden und auch noch weitere Patterns im Detail beleuchten.
Service, wo bist du?
Wie am Anfang kurz skizziert, eignen sich insbesondere Microservices für den Betrieb mit Kubernetes. Es liegt in der Natur von Microservices, dass sie zwar für sich genommen klein sind, dafür aber bei nichttrivialen Anwendungsfällen in großer Anzahl vorliegen, die mehrheitlich voneinander abhängen. Daher müssen Microservices in der Lage sein, sich auf einfache Weise gegenseitig zu finden. Der Mechanismus dazu nennt sich Service Discovery und kann auf viele verschiedene Weisen realisiert werden. In Kubernetes wird die Service Discovery über einen internen DNS-Server bereitgestellt. Jeder Service trägt einen Namen und hat eine fixe interne IP-Adresse. Die Zuordnung dieses Namens zu der IP-Adresse kann über eine DNS-Anfrage aufgelöst werden. D. h., dass ein Microservice order-service, der auf einen Microservice inventory-service zugreifen möchte, einfach inventory-service direkt im Zugriffs-URL wie z. B. http://inventory-service/items verwendet. Der DNS-Eintrag der Services ist ein SRV-Eintrag, der auch die Portnummer enthält. Wenn also diese Portnummer nicht über eine Konvention festgelegt ist (z. B. immer Port 80 für alle Services), dann kann man diesen auch über eine DNS-Anfrage erhalten. Das kann direkt mit einer JNDI-Anfrage [12] erfolgen, was in der Praxis aber etwas hakelig ist; einfacher ist die Verwendung einer dezidierten Library wie spotify/dns-java [13] wier in Listing 1.
Listing 1
import com.spotify.dns.*;
DnsSrvResolver resolver = DnsSrvResolvers.newBuilder().build();
List<LookupResult> nodes = resolver.resolve("redis");
for (LookupResult node : nodes) {
System.out.println(node.host() + ":" + node.port());
}
Konfiguration von Kubernetes leicht gemacht
Jede Anwendung muss auch konfiguriert werden. Typischerweise sind es einfache Dateien, die dazu während der Laufzeit eingelesen und ausgewertet werden. Dieses Prinzip gilt auch für Kubernetes, bei dem typischerwese ConfigMap-Objekte für die Konfiguration verwendet werden.
Diese ConfigMaps lassen sich auf zwei Arten verwenden: Einerseits können diese Key-Value-Paare als Umgebungsvariablen beim Starten eines Pods gesetzt werden. Andererseits können sie auch als Volumes gemountet werden, wobei der Key zum Dateinamen wird und der Value zum Inhalt des Files. Falls sich ConfigMaps im Nachhinein ändern, wird die Änderung direkt in den gemounteten Dateien reflektiert. Wenn die Anwendung einen Hot-Reloading-Mechanismus für ihre Konfigurationsdateien besitzt, können die Änderungen ohne Neustart direkt übernommen werden. Das gilt natürlich nicht für Umgebunsgvariablen, die nur beim Start eines Prozesses gesetzt werden können.
Einen bedeutenden Nachteil haben ConfigMaps jedoch: Für große Konfigurationsdateien sind sie nicht gut geeignet, da der Wert eines ConfigMap-Eintrags maximal 1 MB groß sein darf. Außerdem ist die Verwaltung solcher ConfigMaps für große Konfigurationsdateien recht aufwendig. Das gilt umso mehr, wenn Konfigurationen für verschiedene Umgebungen (z. B. Entwicklung, Staging, Produktion) verwaltet werden sollen. Diese umgebungsspezifischen Konfigurationen unterscheiden sich jedoch nur geringfügig voneinander, wie z. B. bei den Verbindungsparametern einer Datenbank. Für diesen Fall eignen sich die Configuration-Template- und Immutable-Configuration-Muster, wie sie in dem Buch “Kubernetes Patterns” [11] beschrieben sind.
Bei dem Configuration-Template-Pattern wird ein Kubernetes-Init-Container benutzt, der vor den eigentlich Pods startet. Dieser Init-Container enthält ein Template der eigentlichen Konfigurationsdatei, die entsprechende Platzhalter für die unterschiedlichen, umgebungsspezifischen Parameter enthält. Die Werte dieser Parameter werden in einer ConfigMap gespeichert, die wesentlich kleiner als die eigentliche Konfigurationsdatei ist. Der Init-Container verwendet das Konfigurationstemplate, setzt beim Starten die Parameter aus der ConfigMap ein und erzeugt die finale Konfigurationsdatei, die wiederum vom Applikationscontainer verwendet wird. Während der Init-Container für alle Umgebungen gleich ist, enthalten die ConfigMaps umgebungsspezifische Werte. Bei einer Änderung der Konfiguration, die für alle Umgebungen gleich ist, muss somit nur einmal der Init-Container mit dem aktualisierten Template ausgetauscht werden. Das hat gegenüber einer reinen ConfigMap-basierten Konfiguration deutliche Vorteile bezüglich der Wartbarkeit.
Eine weitere Alternative stellt die Konfiguration direkt mit dedizierten Konfigurationsimages für die einzelnen Umgebungen (“mmutable Configuration) dar. Diese Konfigurationsimages können direkt mithilfe von Docker-Buildparametern parameterisiert werden, sodass sich auch der Wartungsaufwand in Grenzen hält. Auch hier spielt ein Init-Container eine wichtige Rolle. Dieser verwendet das Konfigurationsimage und kopiert beim Starten die volle Konfigurationsdatei in ein Volume, sodass die Anwendung diese direkt auswerten kann.
Der große Vorteil dieses Patterns liegt darin, dass die Konfigurationsimages versioniert sind und sich über eine Docker Registry auch verteilen lassen. Jede Änderung der Konfiguration bedarf eines neues Image, sodass sich die Historie der Konfigurationänderungen über die Imageversionierung lückenlos verfolgen lässt.
Bedürfnisse erklären
Damit Kubernetes bestimmen kann, wie Container optimal im Cluster verteilt werden können, muss Kubernetes wissen, welche Anforderungen die Applikation hat. Da sind zum einen Laufzeitabhängigkeiten, ohne die die Applikation nicht starten kann. Das kann beispielsweise der Bedarf nach einem permanenten Speicher sein, der durch Persistent Volumes (PV) bereitgestellt wird. Mithilfe eines Persistent Volume Claim (PVC) kann die Applikation die Größe des angeforderten Plattenspeichers spezifizieren. Es muss also ein Volume in ausreichender Größe zur Verfügung stehen, ansonsten kann der Pod nicht starten.
Ähnliches gilt für die Abhängigkeiten zu anderen Kubernetes-Resource-Objekten wie ConfigMaps oder Secrets. Auch hier kann der Pod nur starten, wenn die referenzierten Ressourcen zur Verfügung stehen.
Die Definition dieser Containerabhängigkeiten ist recht einfach und Teil der Applikationsarchitektur. Etwas mehr Aufwand bedarf die Bestimmung der Ressourcenanforderungen wie Hauptspeicher, CPU oder Netzwerkbandbreite. Kubernetes unterscheidet hier zwischen komprimierbaren (CPU, Netzwerk) und nicht komprimierbaren Ressourcen (Speicher), da komprimierbare Ressourcen bei Bedarf gedrosselt werden können, während das für nicht komprimierbare ausgeschlossen ist. Bei Überschreiten z. B von Speichergrenzen muss der Pod gestoppt werden, da Kubernetes keine generische Möglichkeit hat, den Verbrauch von außen her zu reduzieren.
Die Ressourcenanforderungen eines Pods können über die beiden Parameter request und limit für die enthaltenen Container spezifiziert werden (Listing 2).
Listing 2
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
limits:
cpu: 300m
memory: 200Mi
requests:
cpu: 200m
memory: 100Mi
Dabei gibt request an, wieviele Ressourcen mindestens zur Verfügung stehen müssen, um die Container eines Pods zu starten. Findet Kubernetes keinen Clusterknoten, der diese Mindestanforderung von spezifiziertem Speicher oder CPU aller Container eines Pods zur Verfügung stellen kann, dann startet der Pod nicht. Der andere Parameter limit dagegen stellt die obere Grenze dar, bis zu der die Ressourcen maximal wachsen können. Wird dieser Wert von einem Container überschritten, wird entweder gedrosselt oder der ganz Pod gestoppt. Kubernetes wird typischerweise bei der Verteilung der Pods nur die request-Werte in Betracht ziehen, d. h., es wird ein Overcommitment der Ressourcen zugunsten einer effektiven Auslastung in Kauf genommen. Damit kann Kubernetes in die Situation geraten, dass es Pods abschießen muss. Um zu bestimmen, welche Pods den Knoten verlassen müssen, wendet Kubernetes bestimmte Quality-of-Service-(QoS-)Regeln an:
- Best-Effort: Wenn keine request– oder limit-Werte für alle Container eines Pods gesetzt sind, sind das die ersten Pods, die gestoppt werden.
- Burstable: request und limit sind spezifiziert, aber unterschiedlich. Diese Pods haben kleinere Ressourcengarantien, und damit bessere Chancen, einen Platz im Cluster zu finden. Sie können jedoch bis zum limit wachsen. Pods dieser QoS-Klasse sind die nächsten, die heruntergefahren werden.
- Guaranteed: request und limit sind beide spezifiziert und gleich groß. Damit wird garantiert, dass die Pods in ihrem Ressourcenverbrauch nicht weiter wachsen werden. D. h., sie können zwar nur schwer initial deployt werden (wenn z. B. request recht hoch ist), werden aber nur dann gestoppt, wenn keine Pods der QoS Klassen Burstable oder Best-Effort mehr auf dem Knoten sind.
Warum ist das für uns Java-Entwickler so wichtig? Aufgrund der QoS-Klassen, aber auch aus Gründen des Kapazitätsmanagements, ist es wichtig, alle Container mit Ressourcenlimits zu konfigurieren, um eine möglichst reibungslose Verteilung der Anwendungscontainer zu ermöglichen. Oft muss etwas mit den konkreten Grenzwerten experimentiert werden, da nicht von vornherein klar ist, wie der Ressourcenverbrauch sein wird. Auf jeden Fall aber sollten der JVM analoge Begrenzungen für den initialen und maximalen Heapspeicher mit -Xms und –Xmx mitgegeben werden, die zu den Ressourcenlimits passen. Dabei ist zu beachten, dass der Heap-Speicher nur einen Bruchteil des gesamten Speichers einer JVM ausmacht. Erfahrungen haben gezeigt, dass der sogenannte Non-Heap Speicher 60 Prozent oder mehr des gesamten Speicherbereichs sein kann. Auch hier ist wieder Experimentieren angesagt. Das bereits erwähnte Start-up-Skript run-java.sh hilft hier bei einem initialen Set-up mit sinnvollen Defaultwerten.
Service Mesh
Eines der wichtigste Kubernetes-Designmuster ist das Sidecar-Pattern mit den Spezialisierungen Ambassador (oder Proxy) und Adapter. Bei einem Sidecar gibt es in einem Pod einen Hauptcontainer, der um ein oder mehrere Sidecar-Container erweitert wird. Diese Sidecars fügen der eigentlichen Applikation neue Funktionalität hinzu. Ein einfaches Beispiel wäre ein HTTP-Server wie Nginx als Hauptanwendung, der HTML-Seiten von einem Volume aus liefert. Ein Sidecar-Container könnte dann diese Seiten periodisch mit einem Github Repository abgleichen, sodass Änderung auf GitHub automatisch von dem laufenden HTTP-Server übernommen werden. Damit kann dem HTTP Service eine neue Funktionalität hinzugefügt werden, ohne dabei den Applikationscontainer anzupassen.
Insbesondere für Querschnittsfunktionalitäten wie Circuit Breaking, Security, Load Balancing oder Tracing ist dieses Muster sehr interessant. Der Sidecar-Container kapselt dabei die Zugriffe auf bzw. von der Außenwelt und kann sich transparent in die Netzwerkkommunikation einschalten. Diese Technik wird insbesondere gerne in einem Service Mesh eingesetzt. Dabei ist ein Service Mesh die Gesamtheit aller Dienste, die eine Anwendung ausmachen. Das bekannteste Tool zur Kontrolle eines solchen Service Mesh für Kubernetes ist sicherlich Istio [14], das Envoy [15] als Proxy-Komponente nutzt und folgende orthogonale Infrastrukturaspekte transparent bereitstellt:
- Load Balancing zwischen Services
- Circuit Breaking
- Feingranulare API Policies für Zugriffskontrolle, Rate-Limits und Quotas
- Service-Monitoring und Tracing
- Erweitertes Routing zwischen den Services
Das Schöne an einer Service-Mesh-Unterstützung durch die Plattform für Entwickler von verteilten Microservices ist, dass Infrastrukturaspekte klar von der Geschäftslogik getrennt werden. Im Gegensatz zum direkten Einsatz der Tools aus dem Netflix-OSS-Stack wie Hystrix oder Ribbon, wird diese Funktionalität hier transparent von Istio bereitgestellt, sodass wir uns als Anwendungsentwickler nicht mehr mit Circuit Breaking oder clientseitiger Lastverteilung beschäftigen müssen.
Was bringt die Zukunft?
Tatsächlich sind Kubernetes-Aufsätze wie Istio Bestandteile des nächsten Evolutionschritts im Kubernetes-Kosmos. Das kürzlich vorgestellte Knative [16] baut auf Istio auf und erweitert Kubernetes unter anderem um einen Source-zu-Container-Entwicklungsworkflow und, vielleicht noch wichtiger, einen Baukasten für Serverless-Plattformen auf Kubernetes.
Knative build [17] umfasst Komponenten zum Bauen von Images innerhalb eines Kubernetes-Clusters. Dieses Subsystem ist an Googles Cloud Build (früher: Google Container Builder) angelehnt und verfolgt ein vergleichbares Konfigurationskonzept. Der eigentliche Java Build ähnelt dem von OpenShifts S2I-(Source-to-Image-)Mechanismus, bei dem der Java-Sourcecode innerhalb des Clusters mit einem Build-Tool wie Maven kompiliert wird. Der Unterschied zu S2I besteht darin, das Knative build Docker multi-stage Builds benutzt, während S2I einen eigenen Lifecycle nutzt. Beide Ansätze haben aber jeweils das Problem, dass für Java alle Abhängigkeiten bei jedem Build erneut von einem Maven Repository geladen werden müssen. Es gibt Möglichkeiten, lokale oder nahegelegene Caches zu nutzen, aber das bedarf eines nicht zu unterschätzenden Extraufwands.
Knative serving [18] dagegen ist ein Projekt, das die Implementierung eines Severless Frameworks wesentlich vereinfachen wird. Dazu bietet es eine Möglichkeit, eine Anwendung komplett auf 0 Pods automatisch herunterzuskalieren und bei Eintreffen eines Request wieder aufzuwecken. Das wird durch einen Load Balancer realisiert, der permanent läuft und Anfragen entgegennehmen kann. Viele Softwarehersteller wie Pivotal oder Red Hat waren neben Google bei der Entstehung von Knative beteiligt und sind bereits dabei, Knative in ihre Produkte zu integrieren.
Nachdem wir zunächst die Containerrevolution mit Docker hatten und nun sich alle auf Kubernetes als den gemeinsamen Nenner für die Containerorchestrierung geeinigt haben, ist für die nahe Zukunft zu erwarten, dass Knative- oder Service-Mesh-Support im Allgemeinen die nächste Stufe auf unserem Weg zu Cloud-nativen Java-Anwendungen sein wird.
Cheat-Sheet: Die neuen JEPs im JDK 12
Unser Cheat-Sheet definiert für Sie, wie die neuen Features in Java 12 funktionieren. Von JEP 189 „Shenandoah“ bis JEP 346 „Promptly Return Unused Committed Memory from G1“ fassen wir für Sie zusammen, was sich genau ändern wird!
Links & Literatur
[1]: https://www.graalvm.org/
[2]: https://jira.spring.io/browse/SPR-16991
[3]: https://github.com/fabric8io-images/run-java-sh
[4]: https://github.com/fabric8io-images/java
[5]: https://github.com/fabric8io/docker-maven-plugin
[6]: https://github.com/fabric8io/fabric8-maven-plugin
[7]: https://github.com/GoogleContainerTools/jib
[8]: https://github.com/dsyer/spring-boot-thin-launcher
[9]: http://docs.wildfly-swarm.io/2.0.0.Final/#hollow-jar
[10]: https://azure.microsoft.com/en-us/resources/designing-distributed-systems/en-us/
[11]: https://leanpub.com/k8spatterns
[12]: https://stackoverflow.com/questions/6473320/get-dns-srv-record-using-jndi
[13]: https://github.com/spotify/dns-java
[14]: https://istio.io/
[15]: https://www.envoyproxy.io/
[16]: https://cloud.google.com/knative/
[17]: https://github.com/knative/build
[18]: https://github.com/knative/serving
The post Einmal als Container verpacken? – Java im Zeitalter von Kubernetes appeared first on JAX.
]]>The post Microservices sind kein Allheilmittel! appeared first on JAX.
]]>Ralf D. Müller: Beide Aspekte der Architektur – Stabilität und Flexibilität – müssen wie immer ausgewogen vorhanden sein und bauen aufeinander auf. Erst wenn gewisse Standards existieren und die Vorgehensweise, Schnittstellen etc. dokumentiert sind, lässt sich eine Architektur auch gut ändern, ohne die Stabilität zu riskieren. Deshalb ist es ja auch so wichtig, dass die Architektur gut kommuniziert und die Pfade zur Umsetzung der architekturellen Aspekte ausgetrampelt werden.
Nur wenn jeder im Team weiß, auf was es architekturell ankommt, entsteht die benötigte Stabilität, um später flexibel auf geänderte Anforderungen reagieren zu können. Das arc42-Template von Gernot Starke und Peter Hruschka hilft hier bei der Strukturierung der Dokumentation.
W-JAX: Wie schafft man es, den richtigen Mix aus Stabilität und Flexibilität zu finden? Hast du da vielleicht einen Tipp aus deinen langjährigen Erfahrungen?
Ralf D. Müller: Jedes Projekt ist anders und bringt unterschiedliche Anforderungen bezüglich Stabilität und Flexibilität mit. Deswegen ist es wichtig, einen Blick auf die Requirements zu werfen und nicht einfach eine interessante Architektur eines anderen Projekts zu übernehmen. Die Requirements geben meist vor, welcher Teil der Architektur flexibel und welcher stabil sein muss.
Soll z.B. ein White-Label Produkt erstellt werden, dann ist das Design sicherlich flexibler zu halten als bei einer Anwendung zur internen Verwendung. Aber die beiden Attribute müssen sich auch nicht widersprechen: Erst die Stabilität in den Schnittstellen zwischen wohldefinierten Modulen ermöglicht die Flexibilität zur Änderung einzelner Module.
Lesen Sie auch: Grundkurs Microservices: Warum Frameworks nicht genug sind
W-JAX: Im Zuge der DevOps-Bewegung erweitert sich das Bild des Software-Architekten noch um eine weitere Facette: Es geht nämlich nicht nur um Anwendungsentwicklung, sondern immer mehr auch darum, wie sich Anwendungen in einer Continuous-Delivery-Landschaft einbetten. „You build it, you run it“ heißt da das Stichwort. Wie hat die DevOps-Bewegung die Rolle des Software-Architekten verändert? Was musst du als Architekt heute anders machen, als früher, als man die Anwendungen noch einfach über den Zaun hin zum Ops-Team geworfen hat?
Ralf D. Müller: Hat man das früher gemacht – Anwendungen einfach über den Zaun hin zum Ops-Team geworfen? Der Betrieb der Software war schon immer ein wichtiger Aspekt der Architektur. Eine Applikation wird meist länger betrieben, als entwickelt. Somit ist der Aspekt des Betriebs für den Erfolg der Software mindestens genauso wichtig wie z.B. der Aspekt des Clean Code.
Aus meiner Sicht hat sich in diesem Bereich die wichtigste Änderung nicht direkt durch DevOps ergeben, sondern durch die iterativen Entwicklungszyklen eines agilen Projekts. Es gibt nicht mehr das Upfront-Design der Architektur, sondern man kann ein Projekt nun über mehrere Release-Zyklen begleiten. Dadurch sieht der Architekt vor allem, wie die Architektur die Qualitätskriterien des Projekts auch tatsächlich implementiert und kann die Architektur entsprechend anpassen.
W-JAX: Ein weiterer Trend ist aktuell, das Design einer Software stark an den fachlichen Domänen auszurichten. Neben DDD als Theorie erobern gerade Microservices-Architekturen die Praxis. Neben den technologischen Aspekten, die Domänen-fokussierte Anwendungen mit sich bringen, geht es hier zentral auch darum, die beteiligten Leute erst einmal in ein Boot zu holen: Fachexperten, Entwickler und natürlich auch die Geschäftsleitung und Anwender bzw. Kunden. Ist man da als Software-Architekt nicht eigentlich zu 80% Projektmanager? Wie hältst du das persönlich: Wie stark nimmst du die Rolle des Projektmanagers ein, wie viel konzentrierst du dich auf Technologien?
Ralf D. Müller: Es stimmt schon, dass Software-Architektur streckenweise mehr mit Management als mit Technologie zu tun hat. Aber wie bei allem hängt es sehr stark vom eigentlichen Projekt und des Typs „Architekt“ ab, den man verkörpert. Mich selbst würde ich weniger als Projekt-, sondern mehr als Architekturmanager sehen. Die Architektur, die in meinem Kopf ist, muss irgendwie raus in die Umsetzung. Das geschieht durch Dokumentation, Kommunikation und auch Management.
W-JAX: Auf der W-JAX hältst du einen Talk namens „Docs-as-Code“. Wo liegt der große Unterschied zwischen dem Docs-as-Code-Ansatz, den ihr beschreibt, und der traditionellen Art und Weise, Software zu dokumentieren?
Ralf D. Müller: Der Unterschied ist recht groß und vielfältig. Ich denke, jeder kennt die klassische, mit einer Textverarbeitung erstellte Dokumentation, die getrennt vom Code verwaltet wird. Dokumentation gehört aber, wie Tests auch, zum Code und sollte mit diesem verwaltet werden. Dadurch ist immer klar, wo die aktuelle Version liegt.
Sobald die Dokumentation zusammen mit dem Code verwaltet wird, können auch weitere Aspekte der Softwareentwicklung auf die Dokumentation übertragen werden. So kann z.B. das Aktualisieren von Diagrammen automatisiert im Build umgesetzt und die Dokumentation sogar automatisiert getestet werden. Wird eine Änderung am Code vorgenommen, so gehört es mittlerweile zur Definition of Done, auch die Tests anzupassen. Mit Docs-as-Code wird im gleichen Schritt auch die Dokumentation gepflegt, weil ein Pull-Request sonst nicht als vollständig im Sinne der DoD angesehen wird.
W-JAX: Welchen Trend findest du im Bereich der Software-Architektur momentan besonders spannend – und warum?
Ralf D. Müller: Ich beobachte momentan, wie der Ansatz der Microservices reift. Zum Einen setzt sich die Erkenntnis durch, dass auch Microservices nicht die Lösung für jedes Problem sind und man abwägen muss. Aber auch die Art der Implementierung von Microservices auf der JVM entwickelt sich weiter. So steht mit micronaut.io mittlerweile ein Framework zur Verfügung, welches zielgerichtet auf Microservices hin entwickelt wurde und nicht als Full-Stack Framework entstand. Auch der Serverless-Ansatz ist in diesem Zusammenhang spannend. Solche Entwicklungen sorgen dafür, dass die Arbeit als Software-Architekt immer spannend bleiben wird.
Vielen Dank für dieses Interview!
Erfahren Sie mehr über Software Architecture auf der W-JAX 2018:
● Docs-as-Code: Anatomie einer realen Systemdokumentation
● Wie werde ich ein erfolgreicher Softwarearchitekt?
Cheat-Sheet: Die neuen JEPs im JDK 12
Unser Cheat-Sheet definiert für Sie, wie die neuen Features in Java 12 funktionieren. Von JEP 189 „Shenandoah“ bis JEP 346 „Promptly Return Unused Committed Memory from G1“ fassen wir für Sie zusammen, was sich genau ändern wird!
The post Microservices sind kein Allheilmittel! appeared first on JAX.
]]>The post Wie werde ich ein erfolgreicher Software-Architekt? appeared first on JAX.
]]>Eberhard Wolff: Stabilität und Standards sind keine Ziele, sondern Mittel, um ein wartbares System zu erstellen. Wenn die Software einheitlich gestaltet ist, können Entwickler sich leichter einarbeiten und die Systeme einfacher ändern. Also ist dieses Vorgehen nur dazu da, um Änderbarkeit zu erreichen. Aber dieser Ansatz funktioniert nur theoretisch.
In der Praxis verlieren große Systeme mit der Zeit ihre Struktur und ihre Einheitlichkeit. So werden sie immer schwerer wartbar, was die Langlebigkeit begrenzt. Daher setzen aktuelle Ansätze darauf, Komponenten ersetzbar zu machen, um so der mangelnden Langlebigkeit zu entgehen. Das bieten Microservices. Sie können ersetzt werden, und zum Ersetzen können auch neue Technologien genutzt werden. Ebenso ist es möglich, Microservices mit unterschiedlichen Technologien zu implementieren und so mit der Vielfalt besser umzugehen.
W-JAX: Wie schafft man es, den richtigen Mix aus Stabilität und Flexibilität zu finden? Hast du da vielleicht einen Tipp aus deinen langjährigen Erfahrungen?
Eberhard Wolff: Meiner Meinung nach liegt das Problem auf einer anderen Ebene: Stabilität und Flexibilität sind nur unterschiedliche Wege, um das Ziel Wartbarkeit zu erreichen. Meistens treffe ich in Projekten auf das Problem, dass die Ziele des Projektes unklar sind oder nicht in der Architektur abgebildet worden sind.
Sicher ist Wartbarkeit wichtig, damit man auch in der Zukunft noch das System anpassen kann. Aber wenn das System gar nicht in Produktion geht, weil es Compliance-Richtlinien nicht einhält, die notwendige Performance nicht erreicht oder die Vorgaben im Betrieb nicht erfüllt, hilft die Wartbarkeit nichts. Und wenn das System in den Betrieb geht, aber kein sinnvolles Geschäftsziel unterstützt, ist das System ebenfalls sinnlos.
Architektur bedeutet, eine technische Lösung für ein Problem zu finden. Das wiederum bedeutet, das Problem zu kennen. Zu oft wird einfach nur Wartbarkeit angestrebt – ohne die wirklichen Probleme überhaupt zu lösen oder zu analysieren.
Lesen Sie auch: Grundkurs Microservices: Warum Frameworks nicht genug sind
W-JAX: Im Zuge der DevOps-Bewegung erweitert sich das Bild des Software-Architekten noch um eine weitere Facette: Es geht nämlich nicht nur um Anwendungsentwicklung, sondern immer mehr auch darum, wie sich Anwendungen in einer Continuous-Delivery-Landschaft einbetten. „You build it, you run it“ heißt da das Stichwort. Wie hat die DevOps-Bewegung die Rolle des Software-Architekten verändert? Was musst du als Architekt heute anders machen, als früher, als man die Anwendungen noch einfach über den Zaun hin zum Ops-Team geworfen hat?
Eberhard Wolff: Eigentlich geht es immer noch um dasselbe: Ein System ist für Anwender nur nützlich, wenn es in Produktion ist. Das ist mittlerweile durch Continuous Delivery und DevOps offensichtlich. Daher sollte der Architekt auch diesen Aspekt betrachten. Das klassische Ziel der einfachen Änderbarkeit kann durch Continuous Delivery ebenfalls besser erreicht werden: Software, die schneller und einfacher in Produktion gebracht werden kann, ist einfacher änderbar, weil Änderungen schneller dahin gebracht werden, wo es zählt: In die Hände der Nutzer und zwar abgesichert durch Tests.
Auf der anderen Seite ist die einfache Betreibbarkeit einer Anwendung eine Voraussetzung für eine möglichst einfache Continuous-Delivery-Pipeline. Das kann die Auswahl der Technologien einschränken oder dazu führen, dass Ops-Anforderungen wie Monitoring oder Logging schon frühzeitig betrachtet werden. Das verringert das Risiko und macht allen – Betrieb und Entwicklung – das Leben einfacher.
W-JAX: Ein weiterer Trend ist aktuell, das Design einer Software stark an den fachlichen Domänen auszurichten. Neben DDD als Theorie erobern gerade Microservices-Architekturen die Praxis. Neben den technologischen Aspekten, die Domänen-fokussierte Anwendungen mit sich bringen, geht es hier zentral auch darum, die beteiligten Leute erst einmal in ein Boot zu holen: Fachexperten, Entwickler und natürlich auch die Geschäftsleitung und Anwender bzw. Kunden. Ist man da als Software-Architekt nicht eigentlich zu 80% Projektmanager? Wie hältst du das persönlich: Wie stark nimmst du die Rolle des Projektmanagers ein, wie viel konzentrierst du dich auf Technologien?
Eberhard Wolff: Fachliche Anforderungen zu verstehen ist zentral, um die richtigen Probleme zu lösen. Außerdem ist Architektur eigentlich die Strukturierung der Fachlichkeit. Das geht nur mit fachlichem Wissen und dem Austausch mit fachlichen Experten. Das ist aber kein Projektmanagement und auch nichts Neues. Domain-driven Design ist auch schon fast 15 Jahre alt. Am Ende sollte der Architekt wie alle anderen auch seinen Teil dazu beitragen, dass das Projekt erfolgreich ist. Dazu ist die Fachlichkeit und ihre Strukturierung meist wichtiger als die Technik.
W-JAX: Auf der W-JAX hältst du einen Talk namens „Wie werde ich ein erfolgreicher Softwarearchitekt?“ Dabei gehst du auf Voraussetzungen für einen guten Softwarearchitekten ein, auf die man zunächst vielleicht nicht gleich kommt. Kannst du da einmal ein Beispiel nennen?
Eberhard Wolff: Softwarearchitekten arbeiten zwar mit technischen Herausforderungen, aber zentral ist die gemeinsame Arbeit an den zu lösenden Problemen. Daher geht es in dem Vortrag vor allem darum, wie Architekten ihre Rolle leben sollten, ihr Wissen so einbringen können, dass es auch wirklich umgesetzt wird, und wie man auch das Wissen der anderen Team-Mitglieder nutzbar macht. Aber es gibt natürlich auch ein paar ganz praktische Tipps.
W-JAX: Welchen Trend findest du im Bereich der Software-Architektur momentan besonders spannend – und warum?
Eberhard Wolff: Der nächste Trend sollte sein, sich mit den Zielen und Herausforderungen des jeweiligen Projekts auseinanderzusetzen und dafür passende technische Lösungen zu finden. Andere Trends können sicher helfen, um neue Lösungsmöglichkeiten kennen zu lernen. Es ist gut, wenn man sie unvoreingenommen für die passenden Szenarien nutzt. Aber ich sehe zu oft Architekturen, die dem letzten Trend entsprechen, aber keiner kann sagen, welche Ziele damit wie erreicht werden sollen. Das finde ich schade, denn die Aufgabe eines Architekten ist eben, eine technische Lösung zum Erreichen der Ziele des Projekts zu finden.
Erfahren Sie mehr über Software Architecture auf der W-JAX 2018:
● Integration Patterns for Microservices
● Wie werde ich ein erfolgreicher Softwarearchitekt?
Cheat-Sheet: Die neuen JEPs im JDK 12
Unser Cheat-Sheet definiert für Sie, wie die neuen Features in Java 12 funktionieren. Von JEP 189 „Shenandoah“ bis JEP 346 „Promptly Return Unused Committed Memory from G1“ fassen wir für Sie zusammen, was sich genau ändern wird!
The post Wie werde ich ein erfolgreicher Software-Architekt? appeared first on JAX.
]]>The post Warum Sie ohne Java nicht leben können! appeared first on JAX.
]]>Neben den zahlreichen Frameworks für Enterprise-Anwendungen wie Spring, JSF oder GWT, hat das 23 jährige Dasein von Java zu einer starken Rückendeckung durch IDE’s und Build Tools sowie einer enormen Userbase geführt. Auch ermöglicht die kompilierte Ausgabe von Bytecode eine Kombination mit neuen Sprachen! [1]
Falls Sie immer noch nicht überzeugt sein sollten, dass Java eine rosige Zukunft vor sich hat, wird unsere Infografik Ihren Standpunkt ändern. Wir betrachten die unterschiedlichen Typen die es in der Java-Enterprise-Welt gibt und zeigen, was die Frauen und Herren im Digitalen so treiben.

Cheat-Sheet: Die neuen JEPs im JDK 12
Unser Cheat-Sheet definiert für Sie, wie die neuen Features in Java 12 funktionieren. Von JEP 189 „Shenandoah“ bis JEP 346 „Promptly Return Unused Committed Memory from G1“ fassen wir für Sie zusammen, was sich genau ändern wird!
Links & Literatur
[1] Java ist nicht tot – netter Versuch! Aber Java ist relevanter denn je: https://jaxenter.de/java-nicht-tot-56781
Erfahren Sie mehr über Core Java & JVM Languages auf der W-JAX 2018:
● Das machen wir nebenbei – Concurrency mit CompletableFuture
● Java 9 ist tot, lang lebe Java 11
The post Warum Sie ohne Java nicht leben können! appeared first on JAX.
]]>The post Java Annotation Processing: Das könnte auch ein Computer erledigen appeared first on JAX.
]]>von Gunnar Hilling
Bevor Sie jetzt die Hände über dem Kopf zusammenschlagen: Es geht nicht um das ungeliebte Annotation Processing Tool (apt), das mit Java 5 eingeführt und mit Java 8 endgültig wieder entsorgt wurde, sondern um das Annotation Processing API. Diese mit Java 6 eingeführte Schnittstelle ermöglicht, den eigentlichen Compilevorgang zu beeinflussen und dabei optional auch neuen Code zu erzeugen.
Drum prüfe …
Der erste Schritt ist, Annotations auf die korrekte Verwendung zu prüfen: Bei der Definition einer Annotation ist es notwendig, die Codeelemente anzugeben, die annotiert werden dürfen. Zum Beispiel soll die Annotation GenerateModel dazu dienen, später aus einer Klasse heraus ein statisches Metamodell zu erzeugen. Deshalb haben wir den Zieltyp TYPE gewählt. Dieser verbietet aber nicht, die Annotation fehlerhaft auf andere Annotations anzuwenden.
@Target(ElementType.TYPE)
public @interface GenerateModel {
}
… wer Java Annotations bindet
Dieses Problem dürfte bekannt sein. Besonders, wenn eine Annotation im Rahmen einer Bibliothek per Reflection zur Laufzeit verwendet wird, ist es wichtig sicherzustellen, dass sie auch korrekt verwendet wurde. Ansonsten drohen Laufzeitfehler oder die Annotations werden schlimmstenfalls ignoriert. Für genau diesen Anwendungsfall ist die Annotation-Processing-Bibliothek maßgeschneidert. Listing 1 zeigt dazu einen Processor, der die oben definierte Annotation verarbeitet, aber noch keine Prüfungen ausführt. Durch die Annotation SupportedAnnotationTypes weiß der Compiler, für welche Annotations der Processor aufgerufen werden soll. Die eigentliche Arbeit findet dann in der Methode process statt. Über den Rückgabewert false zeigt sie an, dass die Annotation nicht exklusiv durch diesen Processor verarbeitet werden soll.
Listing 1: Erste Fassung des „MetamodelVerifier“
@SupportedAnnotationTypes({"de.hilling.lang.metamodel.GenerateModel"})
public class MetamodelVerifier extends AbstractProcessor {
@Override
public boolean process(Set<? extends TypeElement> annotations,
RoundEnvironment roundEnv) {
return false;
}
}
Der Quellcode des endgültigen Projekts liegt bei GitHub und darf gerne als Vorlage für eigene Projekte verwendet werden [1]. Zum Bauen braucht es lediglich ein JDK und Maven. Das Projekt enthält neben dem Maven-Aggregator ein Schnittstellenprojekt (API), den eigentlichen Processor und ein separates Integration-tests-Projekt. Der Processor wird nur von Projekten benötigt, die auch wirklich Code erzeugen.
Gewöhnungssache
Jetzt könnte der geneigte Entwickler meinen, dass er nur noch per Reflection die leere Methode mit Leben füllen muss. Ganz so einfach ist es nicht. Wir befinden uns ja noch in der Ausführung des Compilers und damit muss nicht jeder Typ bereits als übersetzte Java-Klasse vorliegen. Daher wurde das Package java.lang.model entwickelt. Es dient dazu, noch nicht übersetzten Code darzustellen. Zu java.lang.model gehören die Schnittstellen TypeMirror und Element. TypeMirror bildet einen deklarierten Typ ab, Element einen Teil des Programms, etwa eine Klasse, eine Methode oder ein Package. Beide bilden neben den Klassen auch Elemente ab, die über Reflection grundsätzlich nicht zugänglich sind –wie Javadocs oder Type-Parameter – und ansonsten der Runtime Type Erasure zum Opfer fallen würden.
Verschaffen Sie sich den Zugang zur Java-Welt mit unserem kostenlosen Newsletter!
Zur Prüfung liefert das RoundEnvironment alle Elemente, die mit GenerateModel annotiert sind. Diese werden anschließend in verifyNotAnAnnotation() geprüft. Die Prüfung ist in diesem Fall einfach, da lediglich ausgeschlossen werden muss, dass es sich beim annotierten Element selbst um eine Annotation handelt.
Listing 2: Prüfung der Annotation
@Override
public boolean process(Set<? extends TypeElement> annotations,
RoundEnvironment roundEnv) {
roundEnv.getElementsAnnotatedWith(GenerateModel.class)
.forEach(this::verifyNotAnAnnotation);
return false;
}
private void verifyNotAnAnnotation(Element element) {
if (element.getKind() == ElementKind.ANNOTATION_TYPE) {
compilerErrorMessage(element);
}
}
getKind() liefert hierbei die Art des Sourcecode-Elements. In der Methode compilerErrorMessage() wird schließlich der Fehler ausgegeben:
processingEnv.getMessager().printMessage(Diagnostic.Kind.ERROR, ERROR_MESSAGE, element, annotation);
Durch die Ausgabe der Nachricht mit Diagnostic.Kind.Error ist der Compile-Vorgang automatisch fehlgeschlagen. Eine Exception darf der Prozessor nicht auswerfen, schließlich sollen auch bei einem fehlgeschlagenen Compilerlauf so viele Fehler wie möglich erfasst werden können. Durch die Argumente element und annotation kann der Compiler eine präzise Rückmeldung über den Fehler liefern.
Test, Test …
Spätestens an dieser Stelle sollte sich die Frage stellen, wie man einen solchen Processor testen kann, denn es gehört offensichtlich zu den zu testenden Fällen, dass es zu einem Compilefehler kommt. Dieser Fall wird durch den CI-Prozess üblicherweise als Fehler angesehen. Zum Glück gibt es hierzu eine Bibliothek, die das Testen erleichtert, nämlich Googles Compile Testing [2]. Innerhalb eines normalen JUnit-Tests setzt man zunächst einen Java-Compiler mit den gewünschten Processors auf:
@Before
public void setUpCompiler() {
compiler = javac().withProcessors(new MetamodelVerifier(),new MetamodelGenerator());
}
Anschließend kann mit diesem Compiler Code übersetzt werden, der nicht im direkten Source-Pfad liegt oder sonst ohne Prozessor übersetzt wird. Daher wird der eigentliche Compilevorgang während der CI-Läufe nicht auf einen Fehler stoßen. Nach der Übersetzung kann auf Fehler geprüft und der generierte Code mit Referenzklassen strukturell verglichen werden (Listing 3).
Listing 3: Compile Testing
@Test
public void failOnIllegalAnnotation() {
final JavaFileObject illegalSource = source(IllegallyUsedAnnotation.class);
Compilation compilation = compiler.compile(illegalSource);
assertAbout(compilations()).that(compilation)
.hadErrorContaining(MetamodelVerifier.ERROR_MESSAGE)
.inFile(illegalSource)
.onLine(3)
.atColumn(1);
assertThat(compilation.status()).isEqualTo(Compilation.Status.FAILURE);
}
private JavaFileObject source(Class<?> clazz) {
return JavaFileObjects.forResource(clazz.getCanonicalName()
.replace('.', '/') + ".java");
}
Die Assertions stammen hier aus der von Compile Testing benötigten Bibliothek google.commons.truth. Sie eignen sich gerade, um Compilefehler präzise und gut verständlich auszudrücken. Jetzt fehlt nur noch die eigentliche Arbeit: das Erzeugen der Metamodel-Klassen.
… bis alles übersetzt werden kann
Da mehrere Processors kombiniert werden können, ist es möglich, dass ein Processor die von einem anderen generierten Quellen verarbeiten muss. Außerdem soll es möglich sein, im Quellcode Klassen zu verwenden, die aus diesem erst noch generiert werden müssen. Um das umzusetzen, führt der Compiler mehrere Durchläufe über die Quellen aus. In jedem Durchlauf werden jeweils alle Annotation Processors aufgerufen, bis kein neuer von einem Processor zu verarbeitender Code mehr erzeugt wurde. Anschließend findet eine finale Runde statt, die dadurch angezeigt wird, dass RoundEnvironment.processingOver() true liefert.
Damit dies funktioniert, sollte ein Processor, wenn seine Ausgabe von anderen Processors weiterverarbeitet werden können soll, in jeder Runde alles erzeugen, was generiert werden kann. Fehlen noch Quellen, so sollte das ignoriert werden, bis die letzte Runde eingeläutet wird. Erst jetzt sollten Fehler aufgrund fehlender Quellen erzeugt werden. Für „Spielprojekte“ kann diese Anforderung natürlich ignoriert werden, aber um einen Processor Production Ready zu machen, sollte dieser auf jeden Fall auf Kompatibilität mit anderen Processors und Generierung in mehreren Runden getestet werden. Im Beispielprojekt wird kein annotierter Code erzeugt, der als Input für andere Generatoren dienen könnte, daher entfallen diese Tests hier.
Modellbau
Zur Vereinfachung wird aus den Quellen zunächst ein Modell für die Attribute erzeugt. Die Klasse ClassModel enthält hierzu eine Map, die jedem Attributnamen eine Beschreibung zuordnet. Außerdem werden die Namen aller Attribute in der korrekten Reihenfolge in einer Liste gehalten. Dies ist eine sinnvolle Information im generierten Metamodel, da die Reihenfolge der per Reflection abgefragten Methoden und Variablen nicht mit der im Quellcode übereinstimmen muss. Das ist häufig ärgerlich, zum Beispiel, wenn aus einer Klasse eine Oberfläche generiert werden soll und dann zusätzliche Annotations notwendig werden, nur um die Reihenfolge der Variablen oder Methoden nachvollziehen zu können.
Für jeden gefundenen annotierten Typ wird aus dem Processor heraus eine neue ClassHandler-Instanz aufgerufen:
private void generateMetamodel(Element element) {
TypeElement typeElement = (TypeElement) element;
final ClassModel classModel = new ClassHandler(typeElement,
processingEnv).invoke();
writeMetaClass(typeElement, classModel);
}
Der ClassHandler erstellt ein ClassModel, aus dem anschließend die Metaklasse generiert wird. Die Implementierung von ClassHandler (Listing 4) verwendet dabei das Stream API, um aus allen Kindelementen der Klasse zunächst die Methoden zu filtern. Anschließend wird für jede Methode geprüft, ob es sich um einen Getter oder Setter handelt und das ClassModel entsprechend angepasst.
Listing 4: “ClassHandler”
private final TypeElement type;
private final ClassModel classModel;
ClassHandler(TypeElement element, ProcessingEnvironment processingEnvironment) {
this.classModel = new ClassModel(processingEnvironment);
this.type = element;
}
ClassModel invoke() {
type.getEnclosedElements().stream()
.filter(element -> element.getKind() == ElementKind.METHOD)
.map(element -> (ExecutableElement) element)
.forEach(this::collectAccessorInfo);
return classModel;
}
private void collectAccessorInfo(ExecutableElement methodRef) {
if (Utils.isGetter(methodRef)) {
String attributeName = Utils.attributeNameForAccessor(methodRef);
AttributeInfo info = classModel.getInfo(attributeName);
info.setType(methodRef.getReturnType());
} else if (Utils.isSetter(methodRef)) {
String attributeName = Utils.attributeNameForAccessor(methodRef);
classModel.getInfo(attributeName).setWritable(true);
}
}
Nun ist die schwerste Arbeit geschafft und man kann sich zurücklehnen, um möglichst entspannt darüber zu sinnieren, wie man jetzt am einfachsten aus den verfügbaren Informationen den gewünschten Code erzeugt. Ein naheliegender Ansatz besteht natürlich darin, straight forward mithilfe von StringBuilder und vielleicht einer Template-Engine dem Problem zu Leibe zu rücken. Daraus ergeben sich jedoch einige Nachteile. Es ist schwer zu gewährleisten, dass der erzeugte Code syntaktisch und semantisch korrekt ist. Noch schwerer ist es, Code zu erzeugen, der den üblichen Gepflogenheiten entspricht und damit lesbar bleibt. Lesbarer Code sollte ein wichtiges Ziel bei der Generierung sein. Zum einen ist es während der Entwicklung einfacher, eventuelle Fehler zu erkennen, zum anderen ist es für die Anwender des Werkzeugs beim Debugging natürlich viel angenehmer, lesbaren Quellcode vorgesetzt zu bekommen [3].
Poesie
Glücklicherweise gibt es auch hierzu inzwischen eine mächtige und dennoch einfach zu verwendende Bibliothek [4]. JavaPoet erzeugt flexibel lesbaren Code und kann zudem die Model-Klassen aus java.lang.model verarbeiten. Außerdem kümmert es sich um die korrekte Erstellung von Importanweisungen und Einrückungen. Die Elemente einer Klasse können über einen Builder erstellt werden. Eine hello, world!-Klasse wird durch den Code in Listing 5 erzeugt.
Listing 5: Hello, World!
TypeSpec.Builder typeBuilder = TypeSpec.classBuilder(CLASS_NAME)
.addModifiers(Modifier.PUBLIC, Modifier.ABSTRACT);
MethodSpec.Builder main = MethodSpec.methodBuilder("main")
.addParameter(String[].class, "args")
.addModifiers(Modifier.PUBLIC, Modifier.STATIC)
.addStatement("$T.out.println($S)", System.class, "hello, world!")
.returns(void.class);
typeBuilder.addMethod(main.build());
JavaFile.builder(PACKAGE_NAME, typeBuilder.build())
.indent(" ")
.build()
.writeTo(System.out);
Lesen Sie auch: Java 9: neuer, toller, bunter?
JavaPoet zeichnet sich einerseits durch einfache Benutzbarkeit aus, da es nicht direkt einen Syntaxbaum abbildet, sondern die Möglichkeit bietet, Code auch frei zu erzeugen. Andererseits gibt es mit den Buildern genug Möglichkeiten, die Grobstruktur des Codes auszudrücken. Speziell die Erzeugung von Statements wird durch die bibliothekseigenen Formatierer sehr vereinfacht. Die Zeichenkette $T.out.println($S) erwartet für die Expansionen einen Typ und eine Zeichenkette. Für den übergebenen Typ werden automatisch Imports erzeugt und der Typ wie gewünscht im Quellcode formatiert: System.class.println(“hello, world”). Neben den beiden genannten sind die wichtigsten Umwandlungen $L für Literale ohne Escaping wie bei Strings und das $N für die Verwendung von Variablen für Bezeichner im Quelltext.
Für die genaue Verwendung von JavaPoet im Beispielprojekt möchte ich auf die Projektquellen bei GitHub verweisen. Die Generierung lässt sich natürlich wieder hervorragend einfach mit Compile Testing prüfen. Da das Projekt relativ einfach ist, habe ich die Tests in MetamodelGeneratorTest als Integrationstests für den gesamten Generator ausgeführt. Bei komplexeren Projekten ist es natürlich sinnvoll, zum Beispiel nur die Codegenerierung aus einem gegebenen festen Model zu testen. Ich habe mich im Beispiel dazu entschlossen, den zu erwartenden Code direkt im Testpfad des Maven-Projektes abzulegen. Dies erleichtert Anpassungen in der IDE für die Tests.
Der Core Java & JVM Languages Track auf der JAX 2020
Der Core Java & JVM Languages Track auf der JAX 2020
Paket für Sie!
Wie ist ein solcher Processor in ein eigenes Projekt einzubinden? Dies funktioniert über die ServiceLoader-Funktionalität von Java. Hierzu wird eine Datei javax.annotation.processing.Processor unter META-INF/services im processor.jar gespeichert:
de.hilling.lang.metamodel.MetamodelVerifier de.hilling.lang.metamodel.MetamodelGenerator
Der Compiler erkennt die Ressource und aktiviert die angegebenen Processors. Daher ist es auch sinnvoll, das API separat verwenden zu können. Es kann dann als transitive Abhängigkeit deklariert werden, während der Processor ja lediglich für die Generierung benötigt wird. Durch das separate integration-tests-Projekt kann auch das Packaging mit getestet werden. Nebenbei dient es natürlich auch als Dokumentation mit Beispielen zur Verwendung.
Wie weiter?
Ich hoffe, ich konnte zeigen, dass man mit vertretbarem Aufwand und ohne Teilnahme an einer Compilerbauvorlesung nützliche Compilererweiterungen mit dem Annotation Processor realisieren kann. Außerdem ist es inzwischen einfach möglich, diese sinnvoll zu testen, was die Entwicklung sehr erleichtert. Ebenso ist die Codegenerierung mit den dargestellten Methoden effizient realisierbar und erzeugt gut lesbaren Code.
Neben der Erstellung eigener Prozessoren finden sich im Netz auch viele fertige Projekte, die den Annotation Processor nutzen. Hierzu möchte ich speziell das Immutables-Projekt [5] empfehlen, das es ermöglicht, einfach verwendbare Immutable Value Objects automatisch zu generieren. Um den Horizont etwas zu erweitern, bietet sich zum Beispiel ein Blick auf Derive4J [6] an, das es unter anderem erlaubt, die Erstellung von DSLs in Java deutlich zu vereinfachen.
Links & Literatur
[1] Quellcode des MetamodelVerifier: https://github.com/guhilling/java-metamodel-generator.git
[2] Compile Tester von Google: https://github.com/google/compile-testing/
[3] Unterhaltsame Beispiele, wie man es nicht machen sollte: https://www.ioccc.org
[4] JavaPoet: https://github.com/square/javapoet/
[5] Immutables-Projekt: http://immutables.github.io
[6] Derive4J: https://github.com/derive4j/derive4j/
Erfahren Sie mehr über Core Java & JVM Languages auf der JAX 2020:
● AdoptOpenJDK – Was ist das eigentlich?
● JVM fine tuning in a Docker Container
The post Java Annotation Processing: Das könnte auch ein Computer erledigen appeared first on JAX.
]]>The post Grundkurs Microservices: Warum Frameworks nicht genug sind appeared first on JAX.
]]>Microservices sind nicht einheitlich definiert. Eine Definition bieten die Independent Systems Architecture (ISA) Principles [1]. Sie bestehen aus neun Prinzipien, denen eine gute Microservices-Architektur genügen muss. Das erste Prinzip besagt, dass Microservices Module sind. Microservices sind nur eine Möglichkeit, ein System zu modularisieren. Alternativen sind Packages, JAR-Dateien oder Maven-Projekte. Für Microservices gilt dasselbe wie für andere Arten von Modulen: So sollen sie beispielsweise lose gekoppelt sein.
Das zweite Prinzip besagt, dass die Module als Container umgesetzt werden. Das bietet mehrere Vorteile: So kann jeder Microservice unabhängig von den anderen neu deployt werden. Bei einem Absturz eines Microservice laufen die anderen Microservices weiter. Bei einem Deployment-Monolith hingegen würde ein Speicherleck die gesamte Anwendung zum Absturz bringen. So erhöhen Microservices die Entkopplung. Klassische Module entkoppeln nur die Entwicklung. Microservices entkoppeln auch andere Aspekte wie Deployment oder Ausfälle.
Ebenso sollen die Microservices Resilience bieten. Wenn ein Microservice ausfällt, müssen die anderen Microservices weiterhin laufen. Sonst ist die Entkopplung bezüglich Ausfällen nicht erreicht. Das System wäre außerdem nicht sonderlich stabil, da der Ausfall eines beliebigen Microservice zu einer Fehlerkaskade führen und das gesamte System zum Ausfall bringen kann. Bei der hohen Anzahl an Microservices ist das ein untragbares Risiko.
Mikro- und Makroarchitektur von Microservices
Die ISA-Prinzipien unterscheiden zwischen Mikro- und Makroarchitektur. Mikroarchitektur bezeichnet Entscheidungen, die auf der Ebene jedes Microservice anders getroffen werden können. Die Makroarchitektur beeinflusst hingegen alle Microservices. Sie muss langfristig stabil sein, denn Änderungen sind schwer umsetzbar. Schließlich beeinflussen sie alle Microservices. Außerdem soll die Makroarchitektur minimal sein, damit die unabhängige Entwicklung der Microservices möglichst wenig eingeschränkt wird.
Aus den ISA-Prinzipien lässt sich ableiten, dass Microservices lose gekoppelt sein sollen und Resilience unterstützen müssen. Das sind wichtige Faktoren bei der Auswahl passender Technologien. Die Aufteilung in Mikro- und Makroarchitektur hat ebenfalls Auswirkungen auf die Technologieauswahl. Das Framework und die Programmiersprache, mit denen ein Microservice umgesetzt wird, kann Teil der Mikroarchitektur sein. Schließlich ist es ein wesentlicher Vorteil von Microservices, dass jeder Microservice mit einer anderen Technologie umgesetzt werden kann. Wenn die Makroarchitektur langfristig stabil sein soll, ist es kaum sinnvoll, eine Programmiersprache oder ein Framework festzuschreiben.
Lesen Sie auch: Microservices mit Java EE: Realistisch und pragmatisch
Wer heute mit Java 9 und Spring Boot 2.0 entwickelt, kann sicher sein, dass der Stack in ein paar Jahren veraltet sein wird. Bei langlaufenden Projekten gilt daher: Wenn alle Microservices dieselben Technologien nutzen sollen, muss man entweder die Technologien veralten lassen oder man migriert alle Microservices gleichzeitig auf die aktuelle Technologie, was risikoreich und aufwendig ist. Nur wenn man unterschiedliche Technologien zulässt, kann man jeden Microservice einzeln modernisieren. Technologiefreiheit erlaubt Teams außerdem, das beste Werkzeug für die jeweilige Herausforderung zu wählen. Dennoch müssen bestimmte Technologien auf Ebene der Makroarchitektur festgeschrieben werden, etwa Technologien für die Kommunikation. Sie beeinflussen alle Microservices und sind daher auch nicht leicht zu ändern.
Microservices: UI-Integration
Ein Microservice kann auch ein UI enthalten. Zum Beispiel kann der Microservice eine HTML-Seite anzeigen. Die Integration eines anderen Microservice kann einfach ein Link sein. Ein konkretes Beispiel zeigt die Crimson Assurance, die als Demo mit einer ausführlichen Anleitung zum Download bereitsteht [2], aber auch online ausprobiert werden kann [3]. Das System ist ein Prototyp für eine Anwendung zur Unterstützung von Versicherungsmitarbeitern. Man kann Versicherte aufrufen und für ihre Autos Schäden erfassen. Das Erfassen des Schadens findet in einem anderen Microservice statt als die Auswahl und Anzeige des Kunden. Die Integration erfolgt über einen Link.
Eine solche Integration hat einige Vorteile: Die Kopplung ist sehr lose, nur das Format der URL muss festgelegt sein und der andere Service kann seine Webseite beliebig aufbauen. Auch für Resilience ist gesorgt: Wenn der verlinkte Microservice ausfällt, kann der Link immer noch angezeigt werden.
Nachdem der Nutzer einen Schaden eingegeben hat, wird er zur Hauptanwendung zurückgeschickt. Das Formular zur Registrierung des Schadens liegt im Schaden-Microservice. Nachdem das Formular abgeschickt ist, wird der Nutzer auf die Seite der Hauptanwendung mit Hilfe eines HTTP-Redirects zurückgeführt. Auch hier ist die Kopplung sehr lose und die Resilience recht gut umgesetzt.
Client-seitige Transklusion
Schließlich kann der Nutzer die Postbox aus dem Postbox-Microservice in die Webseite der Hauptanwendung einblenden. Man spricht von Transklusion. Auf der HTML-Seite ist ein Link mit einigen zusätzlichen Attributen enthalten. JavaScript-Code liest diese Attribute aus und ersetzt den Link durch einen Überblick aus dem Postbox-Microservice, wenn der Nutzer auf den Link klickt. Steht der Postbox-Microservice nicht zur Verfügung, zeigt der Code eine Fehlermeldung an.
Selbst wenn der JavaScript-Code gar nicht funktioniert, weil er nicht geladen werden konnte oder mit dem Browser des Benutzers inkompatibel ist, wird dennoch der Link angezeigt. Resilience ist also sichergestellt. Bei der Entkopplung ist es schwieriger: Damit die Postbox eingeblendet werden kann, muss das Layout zur Hauptanwendung passen. Ähnlich wie bei einer Schnittstellenabstimmung in einem klassischen System muss auch hier sichergestellt sein, dass die beiden Systeme zueinander passen.
Ein Vorteil dieser Integrationen ist, dass sie technologisch einfach ist. Die Integration nutzt fundamentale Konzepte von HTML und HTTP sowie ein wenig JavaScript-Code. Sie lässt sich mit beliebigen Backend-Technologien verwenden. Crimson Assurance besteht dementsprechend auch aus Spring Boot und Node.js Microservices.
Serverseitige Transklusion
Die Transklusion kann auch auf dem Server stattfinden. Das stellt sicher, dass keine Bestandteile der Seite nachgeladen werden müssen. Das kann beispielsweise für die Navigationsleiste sinnvoll sein. Für serverseitige Transklusion gibt es Standards wie SSI [4] oder ESI [5]. Ein Microservice liefert dann HTML aus, in dem SSI- bzw. ESI-Tags enthalten sind. Webserver interpretieren SSI-Tags während Webcaches ESI implementieren. Der Webserver oder Webcache lädt entsprechend den Tags HTML-Schnipsel anderer Microservices nach.
Das Beispiel [4] nutzt den Webcache Varnish (Abb. 1) und sollte dank einer ausführlichen Dokumentation sehr einfach zu starten sein. Diesen Cache kann eine Website nutzen, um Zugriffe auf die Backend-Services zu vermeiden und sie aus dem Webcache zu bedienen. Mit ESI kann der Cache sogar Webseiten mit dynamischen Anteilen cachen. Die dynamischen Anteile kommen aus dem Backend und werden mit ESI in die gecachten statischen Seiten integriert. Das Beispiel nutzt diesen Ansatz, um eine Navigationsleiste zu integrieren. Alle Bestandteile werden 30 Sekunden im Cache gehalten.
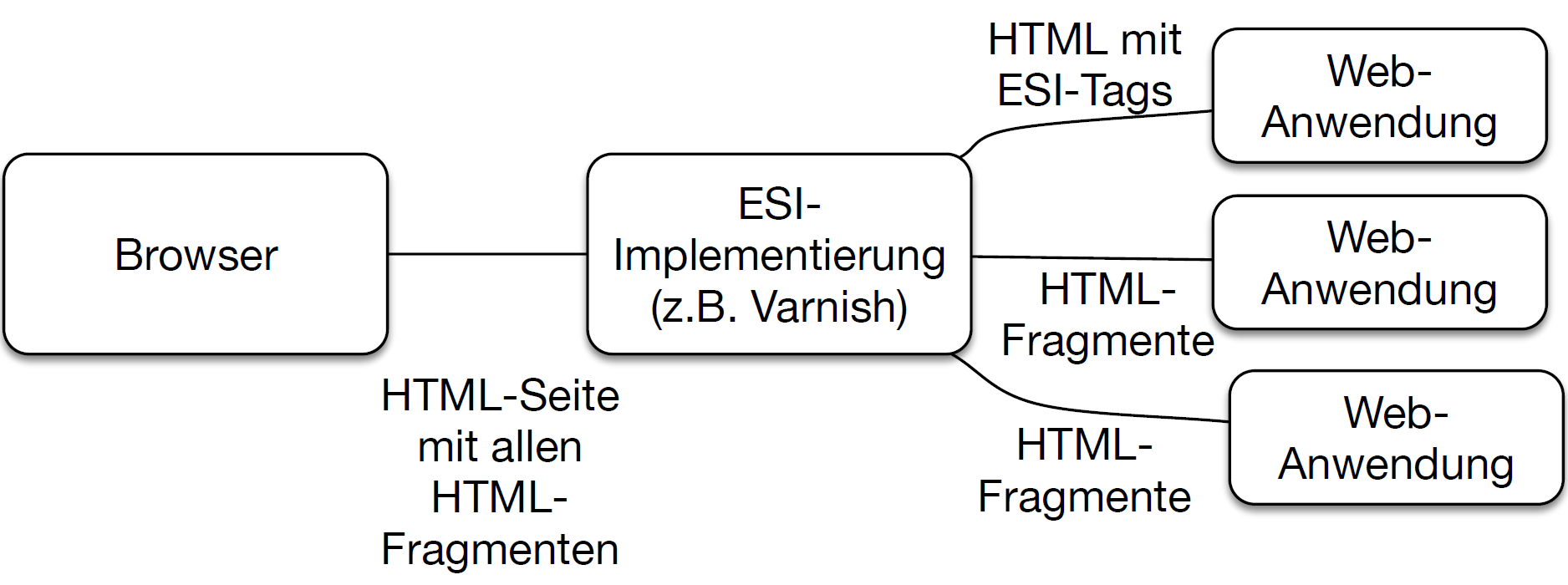
Abb. 1: Transklusion mit ESI und Varnish
Bezüglich der Kopplung gilt Ähnliches wie bei der clientseitigen Transklusion: Das Layout der Webinhalte muss so aufeinander abgestimmt sein, dass sie in einer Webseite kombiniert werden können. Bezüglich Resilience hilft der Cache ebenfalls: Wenn die Backends nicht verfügbar sind, werden die Daten 15 Minuten im Cache gehalten. So können Lesezugriffe weiterhin bearbeitet werden.
UI-Integration: Fazit
UI-Integration unterstützt lose Kopplung und Resilience. Technisch ist sie sehr einfach: Links, Redirects und ca. 60 Zeilen JavaScript können ausreichen. Oft trifft man auf das Vorurteil, dass ein UI, das von mehreren Microservices gemeinsam dargestellt wird, kein einheitliches Look and Feel haben kann. Aber auch bei einem Deployment-Monolith kann eine Webseite völlig anders aussehen als alle anderen Webseiten. Der einzige Weg zum einheitlichen Look and Feel ist ein Style Guide. Außerdem sind gemeinsame Assets hilfreich. Das setzt das Crimson-Assurance-Beispiel mit einem Assetprojekt um, während das ESI-Beispiel die Assets von einem Microservice ausliefern lässt.
Der Microservices & Architecture Track auf der JAX 2019
Der Microservices & Architecture Track auf der JAX 2019
Asynchrone Microservices
Eine weitere Möglichkeit zur Kopplung von Microservices ist asynchrone Kommunikation. Das bedeutet: Wenn ein Microservice gerade einen Request bearbeitet, darf er keinen anderen Microservice aufrufen und auf eine Antwort warten. Er darf also einen anderen Microservice nur dann aufrufen, wenn er nicht auf eine Antwort wartet. Beispielsweise kann ein Microservice gerade einen Request für eine Bestellung bearbeiten. Als Teil der Logik kann der Microservice einen anderen Microservice aufrufen, der eine Rechnung schreiben soll. Allerdings darf er nicht auf eine Antwort warten, sondern muss weiterarbeiten. Wenn der Empfänger gerade nicht verfügbar ist, wird die Nachricht später übermittelt. Die Rechnung würde also später geschrieben und Resilience wäre gewährleistet.
Der Microservice kann auch andere Microservices aufrufen und auf eine Antwort warten. Allerdings nur, wenn der Microservice selbst nicht gerade einen Request behandelt. So kann der Service beispielsweise regelmäßig neue Kundendaten abfragen, auf die Daten warten und sie replizieren. Bei einem Ausfall des Microservice findet keine Replikation statt. Also veralten die Daten, aber das System funktioniert weiterhin und Resilience ist gewährleistet.
Asynchrone Kommunikation mit Message-oriented Middleware
Eine Message-oriented Middleware (MOM) kann eine Infrastruktur bereitstellen, um asynchrone Nachrichten zu verschicken. Eine MOM kann die Zustellung von Nachrichten mit einer hohen Sicherheit garantieren. Dazu muss sie allerdings die Nachrichten dauerhaft speichern. Schließlich kann nur so sichergestellt werden, dass die Nachricht auch dann zugestellt wird, wenn der Empfänger gerade ausgefallen ist.
MOM und Kafka
In der Java-Welt ist JMS (Java Message Service) [6] oft das Mittel der Wahl für asynchrone Kommunikation. Aber gerade im Microservices-Umfeld wird Kafka [7] zunehmend wichtiger. Während andere MOMs Nachrichten meist nur eine gewisse Zeit vorhalten, kann Kafka die Nachrichten beliebig lange speichern. Also kann ein Empfänger sich alle Nachrichten noch einmal zustellen lassen. Auch für die Nutzung von Kafka für Microservices-Systeme gibt es eine einfache Beispielanwendung, bei der aus einer Bestellung eine Rechnung und eine Lieferung werden sollen [8].
Asynchrones REST
Natürlich wäre es denkbar, statt Kafka eine andere MOM zu nutzen. Da alle Kommunikation zwischen den Microservices über die MOM gehen, muss es mit einer hohen Last zurechtkommen und hochverfügbar sein. Das ist an sich kein Problem: Schließlich gibt es schon lange MOM-Installationen, die unternehmenskritisch sind. Dennoch kann es anspruchsvoll sein, die MOM entsprechend zu tunen.
Es wäre schön, wenn es eine Möglichkeit für asynchrone Kommunikation gäbe, die ohne MOM auskommt. Genau das ist mit REST möglich. Ein Microservice holt sich per HTTP GET von einem anderen Microservice die Events ab. Dieses Vorgehen scheint nicht besonders effizient zu sein, denn die Services kommunizieren recht häufig miteinander und in den meisten Fällen gibt es keine neuen Events. Das kann durch HTTP Caching gelöst werden: Der Client schickt beim HTTP Request den Zeitstempel der letzten ihm bereits bekannten Änderung mit. Wenn es keine neuen Events gibt, antwortet der Server mit einem HTTP-Status 304 (Not Modified). Nur wenn es neue Nachrichten gibt, werden tatsächlich Daten mitgeschickt. Um keine überflüssigen Events zu übertragen, kann die Schnittstelle Optionen anbieten, um nur einige Events zu übertragen. So lässt sich die Kommunikation sehr effizient gestalten.
Wenn der Server sowieso die alten Events abgespeichert hat, dann kann er diese Events an der Schnittstelle anbieten, ohne dass dazu eine weitere Speicherung wie bei Kafka notwendig wäre. Das Beispiel [9] nutzt Atom, um die Events dem Client zur Verfügung zu stellen.
Dieses Datenformat wird sonst genutzt, um Abonnenten Blogs oder Podcasts zur Verfügung zu stellen.Im Gegensatz zu Kafka und den meisten anderen MOMs kann asynchrones REST Events nicht an nur einen Empfänger schicken. Jeder Empfänger bekommt alle neue Events und kann sie bearbeiten. So könnte eine Bestellung von mehreren Empfängern bearbeitet werden, sodass mehrere Rechnungen oder Lieferungen ausgelöst werden. Das Beispiel löst das Problem und schaut zunächst in der Datenbank nach, ob die Bestellung schon bearbeitet worden ist. Nur wenn das nicht der Fall ist, bearbeitet der Client die Bestellung; die Clients synchronisieren sich also über die Datenbank. Bezüglich Skalierung hat dieses Vorgehen Nachteile: Nur ein Client bearbeitet ein Event, aber alle anderen überprüfen, ob das Event schon bearbeitet worden ist und führen dabei eine Datenbankoperation aus.
Die Implementierung muss nicht nur für REST, sondern auch für Kafka mit doppelt übertragenen Events zurechtkommen. Wenn ein Event vom Empfänger nicht quittiert wird, geht die MOM davon aus, dass das Event nicht erfolgreich bearbeitet worden ist und überträgt es erneut. Es kann aber sein, dass der Empfänger das Event erfolgreich bearbeitet hat und nur den Empfang nicht quittiert hat. Für diesen Fall muss der Client überprüfen, ob das Event bereits bearbeitet worden ist.
Synchrone Kommunikation bei Microservices
Viele Microservices-Projekte nutzen synchrone Kommunikation mit REST, obwohl das viele Nachteile hat. Bei synchroner Kommunikation kann ein Microservice gerade an einem Request arbeiten und währenddessen einen anderen Microservice aufrufen, um beispielsweise die Kundendaten auszulesen. Wenn der Kundendatenservice gerade ausgefallen ist, muss der Aufrufer eine alternative Strategie umsetzten. Das kann eine fachliche Fragestellung sein: Nimmt man die Bestellung an, wenn man gerade die Zahlungsfähigkeit des Kunden nicht überprüfen kann? Es ist also viel schwieriger, Resilience sicherzustellen.
Bibliotheken wie Hystrix [10] können nur einen Teil der Resilience-Herausforderungen lösen: So kann ein Timeout vermeiden, dass Microservices zu lange auf andere Microservices warten und dadurch ausfallen. Hystrix ist in Java geschrieben und schränkt daher die Technologieauswahl ein. Eine Alternative ist Istio Proxy [11]. Dieser Proxy sichert den Netzwerkverkehr ab und hängt nicht von einer Programmiersprache ab. Einen Microservice mit einem durch das Netz erreichbaren Service gegen Probleme zum Beispiel beim Netzwerkzugriff abzusichern erscheint absurd, aber der Proxy kann auf derselben Hardware laufen und durch das Loopback-Device angesprochen werden.
Bei der Kopplung gilt dasselbe wie bei asynchroner Kommunikation: Für die Unabhängigkeit ist es wichtig, wer APIs und Datenstrukturen definiert und wie viele Microservices von Änderungen beeinflusst werden. Das ist unabhängig davon, ob die Kommunikation synchron oder asynchron ist.Synchrone Microservices müssen diese Herausforderungen lösen:
- Serviceinstanzen sind über eine IP-Adresse und einen Port erreichbar. Um einen Service zu finden, müssen diese Informationen anhand eines Servicenames ermittelt werden (Service Discovery).
- Von jedem Microservice kann es mehrere Instanzen geben. Die Last muss zwischen den Instanzen aufgeteilt werden (Load Balancing).
- Schließlich sollen die Microservices von außen wie ein einziges System wirken. Das Routing muss also einen Request an das System an den zuständigen Microservice weiterleiten.
Der Service Discovery kommt eine entscheidende Rolle zu, denn sie kann die Basis für die Lösung der anderen Herausforderungen sein.
Quarkus-Spickzettel

Quarkus – das Supersonic Subatomic Java Framework. Wollen Sie zeitgemäße Anwendungen mit Quarkus entwickeln? In unserem brandaktuellen Quarkus-Spickzettel finden Sie alles, was Sie zum Loslegen brauchen.
Consul
Consul [12] bietet eine Lösung für Service Discovery. Im Beispiel [13] benötigt die Registrierung eines Microservices nur die Spring Cloud Annotation @EnableDiscoveryClient, einige Einstellungen in der application.properties-Konfigurationsdatei und eine Abhängigkeit zur Bibliothek spring-cloud-starter-consul-discovery. Für das Load Balancing nutzt das Beispiel die Ribbon Library von Netflix. Sie liest alle Instanzen eines Microservice aus Consul aus. Jeder Aufruf geht an eine andere Instanz. So findet das Load Balancing vollständig auf dem Client statt. Ein zentraler Load Balancer, der sonst ein Bottleneck und ein Single Point of Failure wäre, wird vermieden.
Für das Routing von Aufrufen von außen auf den richtigen Microservice nutzt das Beispiel einen Apache-Webserver. Der muss aber so konfiguriert werden, dass er alle Microservices-Instanzen kennt. Consul Template [14] biete dafür eine Lösung: Es erstellt aus einem Template eine Konfigurationsdatei mit Einträgen aus der Consul Service Discovery. Der Apache-Webserver wird so als Reverse Proxy und Load Balancer konfiguriert. Bei einer Änderung in Consul erstellt Consul Template eine neue Version der Konfigurationsdatei und startet den Apache-Webserver neu. Der Webserver weiß nichts von Consul oder Service Discovery, sondern liest einfach nur Informationen aus der Konfigurationsdatei aus.
Lesen Sie auch: Jenkins in der Praxis – Verteilung eines Deployment-Servers
Dieser Aufbau führt aber zu Abhängigkeiten in den Spring-Boot-Projekten zu Consul, um die Registrierung in Consul umzusetzen und das Load Balancing zu implementieren. Das erfordert zwar keinen besonders großen Aufwand, aber die Abhängigkeiten machen es schwierig, Microservices mit einer anderen Technologie in das System einzuführen. Statt Ribbon und den Spring-Cloud-Funktionalitäten für die Registrierung in Consul müsste eine andere Bibliothek genutzt werden.
Für die Registrierung kann aber auch eine Lösung gewählt werden, die ohne Code oder Codeabhängigkeiten auskommt: Registrator [15] kann einen Docker-Container in einer Service Discovery wie Consul registrieren, wenn der Container gestartet wird. So wird der Code unabhängig von Consul. Schließlich kann der Zugriff auf Consul über DNS (Domain Name System) stattfinden, das im Internet auch für die Auflösung von Hostnamen zu IP-Adressen genutzt wird. Die DNS-Anfragen unterstützen auch Load Balancing, so dass die Abhängigkeit zu Ribbon ebenfalls verschwindet. Das Beispiel [16] wird so im Code vollständig unabhängig von Consul. Daher ist es auch kein Problem, einen Microservice in das System zu integrieren, der in einer anderen Programmiersprach oder mit anderen Frameworks implementiert ist.
Kubernetes
Kubernetes [17] ist eine Plattform, die es erlaubt, Docker-Container in einem Cluster ablaufen zu lassen. Kubernetes löst auch die typischen Herausforderungen für synchrone Microservices. Für Service Discovery bietet eine Kubernetes-Installation DNS an. Wenn ein Microservice in Kubernetes gestartet wird, wird er automatisch im DNS registriert. Load Balancing findet auf der Ebene von IP statt: Der Microservice ist unter einer IP-Adresse erreichbar, hinter der sich alle Instanzen verbergen. Im Gegensatz zum DNS-basierten Load Balancing kann dieses Vorgehen sicherstellen, dass DNS-Caches kein Problem sind.
Ein Caching von DNS-Ergebnissen kann nämlich dazu führen, dass die Last nicht zwischen allen Instanzen gleichmäßig verteilt wird, weil einige System veraltete Daten gecacht haben. Für das Routing der Zugriffen von außen bietet Kubernetes Node Ports. Der Kubernetes-Cluster besteht aus verschiedenen Servern bzw. Nodes. Auf jedem Node steht der Microservice unter seinem Node Port zur Verfügung, den ein externer Service nun nutzen kann. Kubernetes kann auch einen Load Balancer konfigurieren, um den Zugriff von außen auf die Microservices zu erlauben. Das Beispiel [18] setzt genau ein solches Vorgehen mit Kubernetes um.
Fazit
Microservices bieten Technologiefreiheit bei der Implementierung der einzelnen Microservices. Daher teilen die ISA-Prinzipien die Architekturentscheidungen in die globale Makro- und die nur einen einzelnen Microservices betreffende Mikroebene auf. Die Entscheidung für eine Programmiersprache oder ein Microservice-Framework kann ein Teil der Mikroarchitektur sein und ist sehr einfach zu revidieren: Man implementiert den nächsten Microservice mit einer anderen Programmiersprache und einem anderen Framework. Technologien zur Kommunikation hingegen sind auf der Makroebene angesiedelt. Eine Entscheidung für eine solche Technologie ist schwieriger zu revidieren, weil sie alle Microservices beeinflussen kann.
Für die Kommunikation gibt es zahlreiche Optionen (Abb. 2):
- UI-Integration bietet eine technologisch wenig aufwendige Alternative, die zu einer guten Resilience und Entkopplung führt.
- Ähnliches gilt für asynchrone Kommunikation. Wenn ein Service ausfällt, werden Nachrichten später übertragen, was zu Dateninkonsistenzen führen kann. Aber die anderen Microservices sind auf jeden Fall weiter nutzbar.
- Bei synchroner Kommunikation muss das System dagegen damit umgehen können, wenn ein Service ausgefallen ist.
Abb. 2: Die Integrationsmöglichkeiten im Überblick
Die verschiedenen hier gezeigten Alternativen stellen Optionen für die Makroarchitektur dar. In jedem Projekt muss diese Entscheidungen selbst getroffen werden. Es gibt bei den hier präsentierten Ansätzen auch viele Variationsmöglichkeiten. Gerade diese Abwägung und Auswahl ist ein Kern der Architekturarbeit.
Neben den hier näher erläuterten Beispielen gibt es eine weitere Demo [19] für typische Microservices-Technologien. Die hier gezeigten Ideen stehen auch im Mittelpunkt der kostenlosen Broschüre „Microservices Rezepte“[20] und des „Microservices Praxisbuchs“ [21]. Die kostenlose Broschüre „Microservices Überblick“ [22] und das Microservices-Buch [23] behandeln zwar auch Technologien, stellen aber die Architektur in den Mittelpunkt.
Links & Literatur
[1] Independent Systems Architecture (ISA) Principles: http://isa-principles.org/
[2] Crimson Assurance Demo: https://github.com/ewolff/crimson-assurance-demo
[3] Crimson Assurance: http://crimson-portal.herokuapp.com/
[4] SCS-ESI: https://github.com/ewolff/SCS-ESI
[5] Transklusion: https://git.io/vhl9q
[6] JMS: https://jcp.org/aboutJava/communityprocess/final/jsr914/index.html
[7] Kafka: https://kafka.apache.org/
[8] Microservice-Kafka: https://github.com/ewolff/microservice-kafka
[9] Microservcie-Atom: https://github.com/ewolff/microservice-atom
[10] Hystrix: https://github.com/Netflix/Hystrix
[11] Istio: https://istio.io/
[12] Consul: https://www.consul.io/
[13] Mircoservice-Consul: https://github.com/ewolff/microservice-consul
[14] Consul-Template: https://github.com/hashicorp/consul-template
[15] Registrator: https://github.com/gliderlabs/registrator
[16] Microservice-Consul-DNS: https://github.com/ewolff/microservice-consul-dns
[17] Kubernetes: https://kubernetes.io/
[18] Microservice-Kubernetes: https://github.com/ewolff/microservice-kubernetes
[19] Microservices-Demos: https://ewolff.com/microservices-demos.html
[20] Microservices Rezepte: https://microservices-praxisbuch.de/rezepte.html
[21] Microservices Praxisbuch: https://microservices-praxisbuch.de/
[22] Microservice Überblick https://microservices-buch.de/ueberblick.html
[23] Wolff, Eberhard: Microservices. https://microservices-buch.de/
Erfahren Sie mehr über Microservices & Architecture auf der W-JAX 2019:
● Microservices-Workshop: Idee, Architektur, Umsetzung und Betrieb
● Aus der Rubrik „Spaß mit Microservices“: Transaktionen
The post Grundkurs Microservices: Warum Frameworks nicht genug sind appeared first on JAX.
]]>The post Jenkins Tutorial: So baut man einen Jenkins-Cluster appeared first on JAX.
]]>von Jörg Jackisch
Sobald wir mit mehreren Teams arbeiten und mehrere Projekte abwickeln und bereitstellen, müssen wir an die Skalierung von Jenkins denken. Dies lässt sich aber mit einer Standardinstallation von Jenkins nur sehr schwer umsetzen, wenn überhaupt. Denn die einzelnen Build-Prozesse auf dem überforderten Jenkins-Server nehmen immer mehr Zeit in Anspruch, was bei der produktiven Zeit der Entwickler und Tester verloren geht. Bei weiter steigender Last auf dem Server wird dieser außerdem zunehmend instabil und fällt öfter aus. Der Frust sowohl bei den Entwickler- als auch Testteams und Teamleitern bis hin zu den Managern ist dann groß. Dieser Frust durch instabile Infrastrukturkomponenten schlägt sich schließlich auch in der Produktivität und Qualität des gesamten Projekts nieder. Das wollen wir natürlich mit allen Mitteln vermeiden. Also muss Skalierung her.
Jenkins skalieren – wie geht das?
Jenkins lässt sich sowohl horizontal als auch vertikal skalieren. In der vertikalen Skalierung kann man den Server mit mehr Hardwareressourcen ausstatten, damit die Jenkins-Applikation performanter ist. Dazu gibt es mehrere Möglichkeiten. Die einfachste ist, die Anzahl der Prozessoren und den Arbeitsspeicher zu erweitern. Auch die I/O-Performance kann man verbessern, indem man bei den Speichermedien zu SSD wechselt und die unterschiedlichen Komponenten mit Fibre Channel verbindet, wenn das Serversystem es zulässt. Bei der vertikalen Skalierung stößt man aber häufig auf technische Grenzen. Hinzu kommt, dass auch die eingesetzten Werkzeuge und Programme, die innerhalb von Jenkins genutzt werden, Multithreading unterstützen müssen, sonst bringt Skalierbarkeit im vertikalen Sektor nicht den gewünschten Effekt. Außerdem bringt das Aufrüsten der Serverhardware keine Ausfallsicherheit mit.
Lesen Sie auch: Grundkurs Microservices: Warum Frameworks nicht genug sind
Da die vertikale Skalierung an Grenzen stößt und man damit keine nachhaltige und langfristige Steigerung erzielen kann, sollte man rechtzeitig die horizontale Skalierbarkeit prüfen und umsetzen. Die horizontale Skalierung beschreibt dabei das Clustering der Anwendung. Jenkins setzt dabei auf eine Master-Agent-(Slave-)Skalierung. Ziel ist es, die Anwendung auf viele Server zu verteilen. Dabei gibt es zwei Alternativen: Zum einen spricht man von einem High-Performance-Computing-(HPC-)Cluster, das dazu dient, die Rechenkapazität zu erhöhen. Zum anderen gibt es High-Available-(HA-)Cluster, die größeren Wert auf die Ausfallsicherheit des Systems legen. Man unterscheidet grundsätzlich zwischen Hardware- und Software-Clustern. In beiden Kategorien gibt es unterschiedliche Methoden der Umsetzung.
Das Jenkins-Cluster in der Theorie
Bei der Einführung eines Jenkins-Clusters beginnt man mit der Einrichtung und Installation der Stand-alone-Variante von Jenkins. Er bildet die Basis des Clusters, verwaltet die gesamte Build-Umgebung und führt über seinen eigenen Executor die Build-Prozesse aus. Der erste Schritt ist es, den Jenkins-Server vertikal zu skalieren, zusätzlich passt man die JRE an. Damit wird man vorübergehend wieder eine stabile Infrastruktur erreichen.
Verschaffen Sie sich den Zugang zur Java-Welt mit unserem kostenlosen Newsletter!
In der Regel ist es allerdings nicht zu empfehlen, die Stand-alone-Variante in einer großen und produktiven Umgebung einzusetzen. Das sollte nur der erste Schritt bei der Einführung von Jenkins sein, denn hier kommt ein großes Sicherheitsrisiko hinzu. Eine Webapplikation führt die Prozesse mit dem Benutzer aus, mit dem der Jenkins-Server gestartet wurde. Meistens ist das ein Benutzer, der erhöhte Rechte besitzt. Das bedeutet, dass der Benutzer der Webapplikation Zugriff auf alle Ressourcen besitzt. Wenn ein Angreifer also Schadcode einschleusen kann, hat er Zugriff auf private oder geheime Daten.
Um vom einzelnen Server zu einer verteilten Lösung zu kommen, bietet Jenkins die Möglichkeit, mehrere sogenannte Worker-Prozesse auf unterschiedliche Server zu verteilen. Dabei bleibt der erste einzelne Server der Master und die weiteren dienen als sogenannte Agents. Dieses Prinzip nennt man Master/Agent Clustering. Dabei verwaltet der Masterserver die komplette Umgebung. Er verteilt einerseits die Deployment-Jobs, andererseits überwacht er, ob die jeweiligen Agents noch verfügbar sind. Der Master dient lediglich dazu, Informationen zu sammeln, Prozesse zu verwalten und letztendlich als grafische Oberfläche des gesamten Schwarms. Die Agents oder Worker sind Server, die nur vom Master Build-Prozesse entgegennehmen und bearbeiten.
Die Master/Agent-Methode gehört zu den HPC-Cluster-Methoden. Die Verteilung der Build-Jobs wird dabei auf alle vorhandenen Worker-Prozesse ausgelagert. Die Verteilung der Jobs lässt sich allerdings auch so konfigurieren, dass bestimmte Abläufe und Prozesse nur auf bestimmten Agents ausgeführt werden.
Damit der Master mit seinen Agents kommunizieren und nachvollziehen kann, ob sie noch verfügbar sind, kann man drei unterschiedliche bidirektionale Kommunikationsmethoden verwenden: Kommunikation per SSH (Secure Shell), JNLP-TCP (JNLP, Java Native Launch Protocol) oder JNLP-HTTP (Java Webstart). Falls es über keinen der vorhandenen Konnektoren möglich ist, eine Verbindung zwischen den Agents und dem Master aufzubauen, kann man auch ein eigenes Skript entwickeln. Als Programmiersprachen für eigene Konnektoren eignen sich vor allem Groovy oder Grails, doch auch Implementierungen mit der Programmiersprache Python sind gängig.
Bei der Methode mit dem SSH-Konnektor fungiert jeder Agent als SSH-Server und der Jenkins-Master ist der SSH-Client; in der Regel via Port 22 mithilfe eines SSH-Schlüssels, der auf dem Agent erstellt wird. Man kann die Verbindung aber auch ohne Schlüssel aufbauen. Dann wird sich der Server wie bei einer gewöhnlichen SSH-Kommunikation mit einem Benutzernamen und einem Passwort anmelden. Es ist empfehlenswert, den Benutzer zu nehmen, mit dem auch der Jenkins-Master läuft. Agents, die auf Microsoft Windows basieren, lassen sich mithilfe des Programms Cygwin verbinden. Cygwin [1] ist eine Sammlung von Open-Source-Werkzeugen, die unter Windows Funktionalitäten eines Linux-Systems bereitstellen.
Jenkins bietet mit dem JNLP-HTTP- und dem JNLP-TCP-Konnektor zwei Varianten, mit denen man mithilfe der Java-internen Protokolle Master und Agent miteinander kommunizieren lassen kann. Um JNLP zu verwenden, arbeitet Jenkins mit der Java-Web-Start-Technologie. Das ist wahrscheinlich die einfachste Art und Weise, Agent und Master zu verknüpfen, da man auf dem Agent lediglich die Java-Applikation des Masters ausführen muss und so bereits die Verbindung aufgebaut hat.
Der Software Architecture Track auf der JAX 2020
Der Software Architecture Track auf der JAX 2020
Das Jenkins-Cluster in der Praxis
Nach der ganzen Theorie erstellen wir jetzt ganz praktisch mit Docker einen Jenkins-Schwarm. Bei diesem Beispielszenario verbinden wir auf unterschiedliche Art und Weise vier Agents mit einem Masterserver. Es gibt also insgesamt fünf Server. Der Masterserver basiert auf einem Debian Linux, ebenso wie drei der Agents. Zusätzlich wird ein Server hinzugenommen, auf dem Windows läuft. Auf dem Masterknoten des Jenkins-Schwarms läuft das Jenkins Backend. Eine solch heterogene Verteilung bringt den Vorteil, dass man bestimmte Schritte innerhalb des Deployment-Prozesses auf einem bestimmten Betriebssystem ausführen kann. Als Beispiel dienen hier automatisierte Browsertests: Ich möchte meine Java-EE-Applikation sowohl auf einem Windows-Betriebssystem mit Microsoft Edge als auch auf einem Linux-Betriebssystem mit Mozilla Firefox testen.
Basierend auf einem Debian Linux oder einer ähnlichen Linux-Distribution muss man folgende Befehle ausführen, um eine lauffähige Jenkins-Umgebung zu erstellen:
$> apt-get update && apt-get upgrade
Mit apt-get update wird der Paketmanager APT anhand seiner Konfiguration aktualisiert und mit dem Kommando apt-get upgrade das Betriebssystem. Das sollte man stets vor einer Installation einer neuen Software durchführen. Mit dem Befehl $> apt-get install default-jre wget wird die JRE mit all ihren Abhängigkeiten installiert. Hinzu kommt auch das Programm Wget, mit dem Jenkins zur sources-list-Datei von APT hinzugefügt wird. Zum Hinzufügen der Sources für APT benutzt man die Zeilen aus der Dokumentation von Jenkins [2]:
$> wget -q -O - https://pkg.jenkins.io/debian/jenkins-ci.org.key | apt-key add - $> sh -c 'echo deb http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list' $> apt-get update $> apt-get install jenkins
Letztendlich wird mit dem letzten Kommando der Jenkins-Server installiert. Mit Docker kann man diese Installation abkürzen und virtualisiert den Server innerhalb eines Containers. Das Image, das dabei benutzt wird, befindet sich online im Docker Hub. Mit einem Befehl wird ein Container mit Linux erzeugt, auf dem ein Jenkins-Deployment-Server läuft:
$> docker run --name=Master –link=slave3:2222 -d -ti -p 8080:8080 -p 50000:50000 jenkins:latest /bin/bash
Mit den Parametern –p werden die Ports 8080 und 50000 vom Container auf dieselben Ports auf dem Host gemappt. Docker lädt dabei jeden Image-Layer des Docker-Files von Jenkins einzeln herunter und richtet eine lauffähige Umgebung ein. Dabei wird die Bash auf dem Server gestartet, und man kann sich mit dem Befehl docker attach und der Container-ID mit der Bash des Servers verbinden. Zum Starten des Servers führt man den Befehl zum Starten von Jenkins aus: $> java -jar /usr/share/jenkins/jenkins.war &.
Nachdem der Jenkins-Masterserver gestartet ist, kann man in der Docker-Toolbox mit der Tastenkombination STRG + P + Q den Server wieder detachen.
Egal mit welcher Variante der Masterserver eingerichtet wurde, navigiert man im Browser seiner Wahl auf die jeweilige IP-Adresse des Servers. Bei Docker ist das die IP-Adresse des Docker Containers, auf dem der Jenkins-Server läuft, jeweils mit dem Port 8080. Unter http://IP_ADRESSE:8080/ wird jetzt der Set-up-Screen von Jenkins dargestellt. Dort muss man das initiale Passwort eingeben, das bei der Installation angezeigt wurde.
Falls man es übersehen hat, findet man es unter /var/jenkins_home/secrets/initialAdminPassword auf dem Server. Nach dem Set-up kann man sich beim Masterserver anmelden. Zu diesem Zeitpunkt hat man einen Stand-alone-Server eingerichtet, auf dem man die jeweiligen Projekte konfigurieren und einrichten kann.
Zum Erstellen der Slaveserver benutzt man wieder ein Docker Image, das ein Standard-Debian-Betriebssystem bereitstellt. Zum Starten der Server wird folgender Befehl ausgeführt:
docker run -ti --name=Slave1 -d debian:latest /bin/bash docker run -ti --name=Slave2 -d debian:latest /bin/bash docker run -ti --name=Slave3 –hostname=slave3 -p 2222:22 -d debian:latest /bin/bash
Dieser Befehl lädt das aktuelle Debian Image aus dem Docker Hub herunter und startet es als Daemon im Hintergrund (-d = detached). Mit dem Befehl docker ps –format “table {{.ID}}\t{{.Image}}\t{{.Names}}” sollten jetzt alle vier Linux-Server sichtbar sein.
Um die Linux Agents mit dem Masterserver zu verbinden, werden zuerst zwei der Linux-Server per JNLP verbunden. Einer wird per SSH die Verbindung mit dem Masterserver aufbauen. Im Jenkins-Master richtet man für die zwei weiteren Linux-Server jeweils einen weiteren Agent bzw. Knoten ein und lädt dann die Datei slave.jar auf den jeweiligen Slaveserver herunter. Die Knoten sollten sogenannte permanente Knoten sein, und als Startmethode wählt man LAUNCH AGENT VIA JAVA WEB START. Nach der Einrichtung der Agents wird dieser Befehl angezeigt:
Java -jar slave.jar -jnlpURL URL_DES_JENKINS_SERVERS -secret SECRET
Als Parameter für die slave.jar werden die Verbindungsparameter benötigt. Der erste ist –jnlpURL, er teilt der slave.jar mit, wo sich der Server befindet. Der zweite ist ein Secret zur Verbindung (-secret). Den kompletten Befehl, um den Agent zum Master zu verbinden, sieht man, wenn man im Jenkins Backend durch die Punkte JENKINS VERWALTEN | KNOTEN VERWALTEN | SLAVE1 navigiert. Das Gleiche gilt für den zweiten Agent: JENKINS VERWALTEN | KNOTEN VERWALTEN | SLAVE2.
Der dritte Linux-Server kommuniziert per SSH mit dem Masterserver. Dazu geht man wieder mit dem Befehl docker attach in die Bash des Slaves und lädt als Erstes die slave.jar-Datei herunter. Ich benutze dafür Wget und verschiebe die Datei danach in das /bin-Verzeichnis. Zusätzlich muss man hier einen SSH-Server installieren, unter Debian Linux mit dem Befehl apt-get install openssh-server. Im nächsten Schritt legt man einen neuen Benutzer an und gibt ihm ein Passwort.
$> groupadd jenkins $> useradd -g jenkins -d /home/jenkins -s /bin/bash jenkins $> passwd jenkins
Nun erzeugt man einen SSH-Schlüssel, hinterlegt ihn auf dem Jenkins-Server und testet von ihm aus den Log-in.
Im Backend des Masterservers wird auch der dritte Knoten angelegt. Als Startmethode wird hier allerdings LAUNCH AGENT VIA EXECUTION OF COMMAND ON THE MASTER ausgewählt. Nach dieser Auswahl öffnet sich ein neues Konfigurationsfeld, in das man das Startkommando eintragen kann:
ssh -p 2222 [email protected] java -jar /bin/slave.jar
Alternativ bietet Jenkins auch die Startmethode STARTE SLAVE ÜBER SSH. Dort kann man den Hostnamen, Port, Benutzernamen und das Passwort eingeben. Der Jenkins-Server wird sich dann per SSH-Client auf den Server verbinden und ihn als Slave starten. In der Übersicht unter JENKINS VERWALTEN | KNOTEN sollten nun alle Agents dargestellt werden und online sein.
Zur Installation des Windows-Servers empfiehlt es sich, eine virtuelle Maschine zu benutzen. Dann folgt man den Installationsanweisungen des Set-ups von Microsoft. Man sollte allerdings bei der Auswahl der Version darauf achten, was man tatsächlich auf diesem Server ausführen möchte. In diesem Szenario empfiehlt sich Windows in der Clientversion 10, da man dort den Browser Edge zur Verfügung hat. Somit kann man seine Applikation auf Edge testen. Da man keine Serverversion des Betriebssystems benutzt, kann man auch weitere Versionen des Internet Explorers installieren.
Lesen Sie auch: Das Beste aus beiden Welten – Objektfunktionale Programmierung mit Vavr
Unter Windows benutzt man nahezu immer den Verbindungsaufbau per JNLP-HTTP, da dies eine sehr einfache Variante ist, Slaves mit dem Java Web Start zum Jenkins-Masterserver hinzuzufügen. Um den Windows-Server zum Schwarm als Agent hinzuzufügen, verbindet man sich per Remote Desktop zum Windows-Server. Auf diesem benutzt man einen Browser und navigiert zum Jenkins-Master. Nachdem man sich dort eingeloggt hat, klickt man in der Jenkins-Oberfläche auf den Menüpunkt JENKINS VERWALTEN | KNOTEN VERWALTEN und wählt den Menüpunkt NEUER KNOTEN, um einen neuen Agent hinzuzufügen. Im nächsten Fenster füllt man das Textfeld mit dem Namen seines Knotens aus, hier MS Windows Server, und wählt PERMANENT AGENT. Nach der Bestätigung kommt man zur Konfiguration des Knotens.
Das wichtigste Feld bei diesem Formular ist die Startmethode. Dort wählt man in unserem Beispiel LAUNCH AGENT VIA JAVA WEB START. Nach dem Speichern dieses Formulars kommt man zurück zur Übersicht der Knoten. Dort ist nun unser angelegter Windows-Knoten verfügbar, der allerdings mit einem roten Kreuz markiert ist, was bedeutet, dass der Agent nicht verbunden ist. Mit einem Klick auf den Agent kommt man zur Übersichtsseite, wo man mit Klick auf den Java-Webstart-Launch-Knopf die JNLP-Verdingung herstellen kann. Dazu wird eine slave-agent.jnlp-Datei heruntergeladen, die gestartet werden muss, und schon ist der Agent verbunden.
Quarkus-Spickzettel
Quarkus – das Supersonic Subatomic Java Framework. Wollen Sie zeitgemäße Anwendungen mit Quarkus entwickeln? In unserem brandaktuellen Quarkus-Spickzettel finden Sie alles, was Sie zum Loslegen brauchen.
Fazit
Zu Beginn eines Projekts sollte die Planung für den Deployment-Prozess und die Skalierung in der Architekturplanung enthalten sein. Man sieht, wie schnell und einfach man mit Docker einen Jenkins-Schwarm erstellen kann. Läuft der Cluster in einer produktiven Umgebung, kann langfristig und nachhaltig eine qualitativ hochwertige Software garantiert werden.
Links & Literatur
[1] Cygwin: https://www.cygwin.com
[2] Jenkins: https://wiki.jenkins-ci.org/display/JENKINS/Installing+Jenkins+on+Ubuntu
Erfahren Sie mehr über Continuous Delivery auf der JAX 2020:
● Datenbanken in Docker und Kubernetes? Ja, klar!
● Cloud Native Developer Experience: Von Code-Gen bis Git Commit ohne CI/CD Pipeline
The post Jenkins Tutorial: So baut man einen Jenkins-Cluster appeared first on JAX.
]]>