
Nehmen wir ein ganz konkretes Beispiel. Eine Spring-Boot-Webapplikation startet den eingebetteten Application Server üblicherweise mit dem Port 8080. Es ist jedoch nicht unüblich, dass der Port geändert werden muss – beispielsweise, weil bereits eine andere Applikation auf Port 8080 lauscht. Bei Spring Boot ist es sehr einfach, den Port zu ändern, indem man die server.port Property auf den Wert 7081 setzt. Damit sehen wir bereits ein wichtiges Element der Spring-Boot-Konfiguration: Die Konfiguration basiert auf Properties – einfachen Key-Value-Paaren.
Artikelserie
Teil 1: Auto Configuration begreifen und selbst erstellen
Teil 2: Externalized Configuration
Spring Boot bietet eine Vielzahl verschiedener Möglichkeiten, wo die Property angegeben werden kann. Beispielsweise können Umgebungsvariablen, Kommandozeilenparameter, Properties-Dateien und YAML-Dateien genutzt werden. Aber auch Quellen wie z. B. JNDI oder der Servlet Context sind möglich.
Experimentieren wir mit den wichtigsten Möglichkeiten, eine Konfiguration vorzunehmen. Als Basis für die Experimente dient die Spring-Boot-Applikation aus Listing 1. Das vollständige Codebeispiel findet sich im GitHub Repository.
Listing 1
@SpringBootApplication
public class SpringEnvironmentExplorationApplication {
public static void main(String[] args) {
final ConfigurableApplicationContext context =
SpringApplication.run(SpringEnvironmentExplorationApplication.class, args);
PrintUtil.printCaption("Spring Environment Exploration");
final ConfigurableEnvironment environment = context.getEnvironment();
PrintUtil.printKeyValue("server.port", environment.getProperty("server.port"));
// print all currently activated profiles
PrintUtil.printKeyValue("active profiles:", environment.getActiveProfiles());
// print all property sources
final String[] sources = environment.getPropertySources()
.stream()
.map(Object::toString)
.toArray(String[]::new);
PrintUtil.printKeyValue("property sources:", sources);
// close the spring application
System.out.println("-----------------------------");
System.exit(SpringApplication.exit(context));
}
}
Die genaue Funktionsweise des Beispiels ist für die folgende Betrachtung zweitrangig. Wichtig ist, dass wir den gesuchten Wert über environment.getProperty(“server.port”) auslesen werden. Zudem wird diese Klasse wie jede typische Spring-Boot-Anwendung gestartet. Spring Boot kapselt das Wissen über die Konfiguration einer Anwendung im sogenannten Environment, über das wir auch Zugriff auf alle Spring Boot zur Verfügung stehenden Properties erhalten.
Für die folgenden Beispiele betrachten wir immer den Output der Anwendung, wie in Abbildung 1 zu sehen – speziell die Zeile mit dem Wert für die Property server.port.
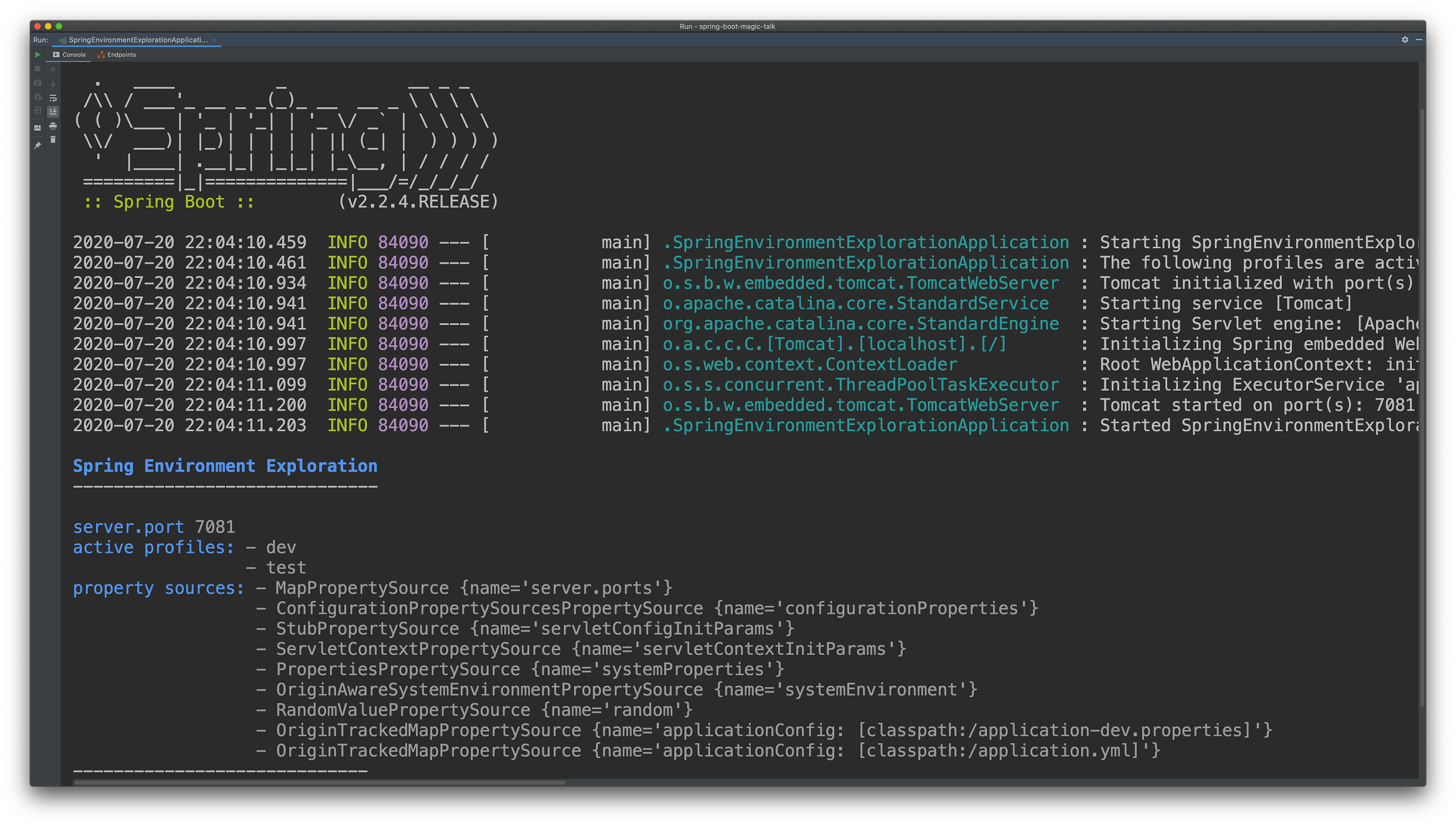
Konfiguration über die Kommandozeile
Für die Konfiguration über die Kommandozeile (oder beispielsweise in Shellskripten oder Dockerfiles) gibt es drei Möglichkeiten:
- als klassische System Property -Dserver.port=7081
- von Spring Boot interpretierter Anwendungsparameter –server.port=7081
- als Umgebungsvariable
Bei den Umgebungsvariablen wird eine besondere Form des Spring Boot „Relaxed Binding“ angewendet. Das Prinzip ist recht einfach: Buchstaben werden in Großbuchstaben umgewandelt, Punkte durch ein Underscore ersetzt und Bindestriche entfernt. Damit ergibt sich für unser Beispiel die Umgebungsvariable SERVER_PORT. Starten wir die Anwendung aus Listing 1 mit –server.port=7081, sehen wir in der Ausgabe, dass diese Konfiguration übernommen wurde.
Konfigurationsdateien
Neben den genannten Möglichkeiten über die Kommandozeile bietet Spring Boot die Möglichkeit, Konfigurationsdateien zu verwenden. Die meisten sind hierbei bereits über die application.properties gestolpert, denn bei einer über start.spring.io erstellten Anwendung wird diese automatisch generiert. Einstellungen wie beispielsweise server.port lassen sich in der application.properties setzen. Neben den Properties-Dateien gibt es die Möglichkeit, Konfigurationsdateien im YAML-Format zu verwenden. Spring Boot führt dabei eine Konvertierung von YAML zu Properties durch (Kasten: „YAML zu Properties Mapping“).
Beim Anwendungsstart sucht Spring Boot an zwei unterschiedlichen Stellen nach den application.properties (respektive application.yaml). Zum einen direkt im Klassenpfad der Anwendung selbst. Daher generiert start.spring.io eine application.properties im resources-Verzeichnis. Zusätzlich zu den Konfigurationen im Klassenpfad sucht Spring Boot in einem config/-Verzeichnis unterhalb des aktuellen Ausführungsverzeichnisses.
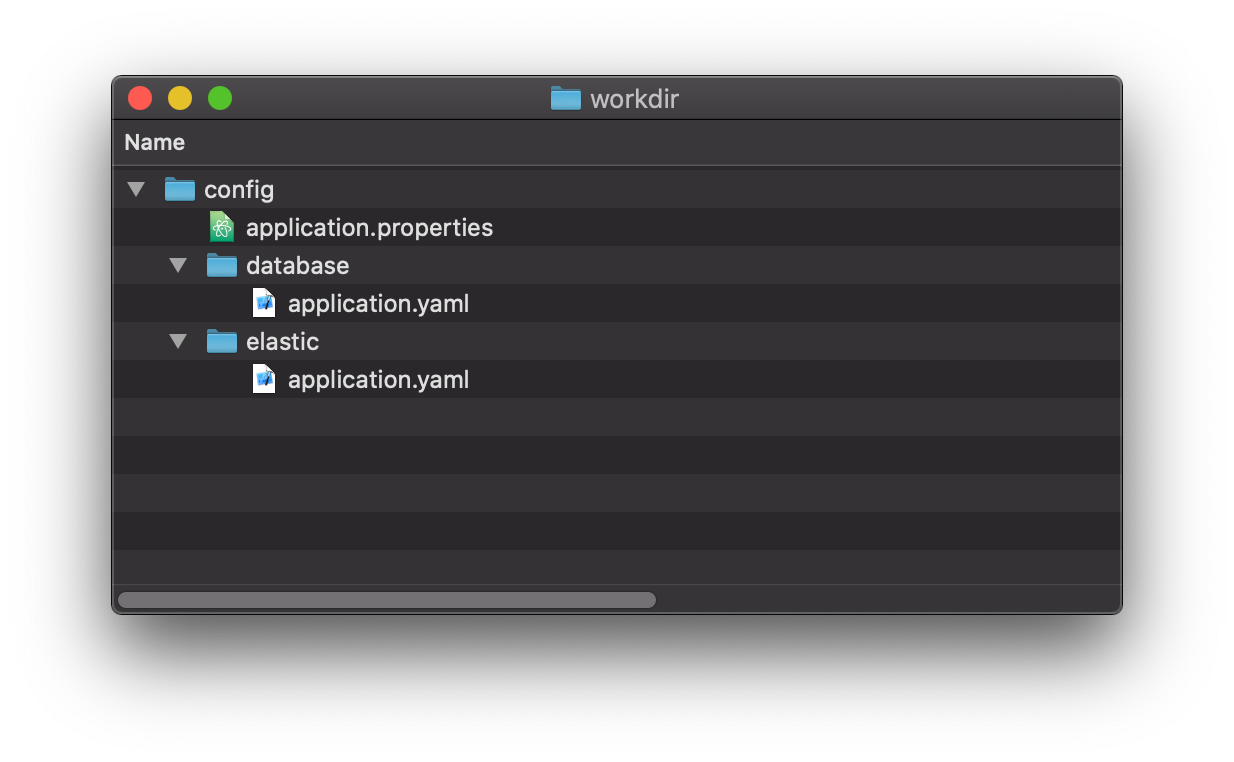
Spring Boot 2.3 beschränkt sich zudem nicht auf das config/-Verzeichnis, sondern beachtet auch dessen Unterverzeichnisse. Das erlaubt es, die Anwendungskonfiguration zu modularisieren, beispielsweise um Kubernetes ConfigMaps einfacher verwenden zu können. Hat man eine Anwendung, die sowohl eine Datenbank- als auch eine ElasticSearch-Verbindung benötigt, könnte man die Konfiguration entsprechend aufteilen. Abbildung 2 zeigt eine exemplarische Struktur für diesen Anwendungsfall. Ein Mischen von Properties und YAML-Dateien ist dabei problemlos möglich. Versuchen Sie es selbst, indem Sie server.port in verschiedenen Konfigurationsdateien setzen.
YAML zu Properties Mapping
Spring Boot führt die Konvertierung von YAML zu Properties mittels der Logik des Spring Frameworks durch [4]. Konkret wird der YamlPropertySourceLoader verwendet, der die strukturierten und hierarchischen YAML-Daten in eine Liste aus Key-Value-Paaren konvertiert. Beispielsweise werden aus dem Input
application: name: Test Application url: https://test.example.com server: port: 4711
die folgenden Properties erzeugt:
application.name=Test Application application.url: https://test.example.com server.port: 4711
Neben den reinen hierarchischen Daten können in YAML auch Listen ausgedrückt werden. Hierbei wird das Beispiel
application:
servers:
- test.example.com
- qa.example.com
in eine Liste von Properties konvertiert, die einen [index] enthalten:
application.servers[0]=test.example.com application.servers[1]=qa.example.com
Profile
Wir haben gesehen, wie Konfigurationswerte einfach bereitgestellt werden können. Was ist jedoch, wenn sich die Konfiguration einer Anwendung zwischen Entwicklung und Betrieb unterscheidet? Typischerweise sollte kein Entwickler während der Entwicklung direkt auf die Produktionsdatenbank zugreifen, sondern eine dedizierte Entwicklungsinstanz einer Datenbank verwenden. Genau an dieser Stelle (neben weiteren) können die Profile helfen.
Betrachten wir ein einfaches Beispiel: Während der Integrationstests soll unsere Anwendung über den Port 9080 erreichbar sein, in der Produktionsumgebung jedoch unter 7080. In beiden Fällen müssen wir die Konfigurationsoption server.port verwenden. Nun könnte man für die Entwicklung und Produktion jeweils unterschiedliche Anwendungsparameter (–server.port=7080) verwenden. Unterscheidet sich die Konfiguration zwischen verschiedenen Umgebungen nur geringfügig, ist das ein gangbarer Weg. Bei mehr als einer Konfigurationsoption wird das jedoch schnell sehr unübersichtlich. Idealerweise sollte man diese verschiedenen Varianten jeweils gruppieren können. Genau dafür eignen sich Profile.
Ein Profil ist in erster Linie ein Name, der frei gewählt werden kann. Bleiben wir bei unserem vorherigen Beispiel, könnten wir zwei Profile definieren: test und production. Um nun mit jedem Profil die richtige Konfiguration zu assoziieren, können wir jeweils eine Konfigurationsdatei definieren: application-test.properties und application-production.properties. Damit definieren wir für das Profil test den Wert server.port=9080 und für production den Wert server.port=7080. Mittels der spring.profiles.active Property teilt man Spring Boot mit, welche Profile aktiv sein sollen. Auch diese Property ist eine Environment-Property, die damit sowohl als Anwendungsparameter –spring.profiles.active, Umgebungsvariable SPRING_PROFILES_ACTIVE oder Property in der application.properties angegeben wird.
Bemerkenswert ist der Plural in der Property spring.profiles.active. Es ist möglich, mehr als nur ein aktives Profil zu definieren. Möchte man beispielsweise die Profile test und embedded-database gemeinsam aktivieren, genügt es, beide mit einem Komma getrennt aufzulisten: spring.profiles.active=test,embedded-database.
Ladereihenfolge
Wir haben gesehen, dass Spring Boot Konfigurationsdateien in verschiedenen Varianten und für verschiedene Profile laden kann. Nun stellt sich die Frage, in welcher Reihenfolge sie betrachtet werden. Hat man ein aktiviertes Profil test, wird nicht nur die application-test.properties, sondern auch die application.properties geladen. Die Präzedenz der Konfigurationsdateien ist hierbei wichtig. Konfigurationsdateien für ein Profil gelten als „spezifischer“ und überschreiben daher die allgemeinere Konfiguration einer application.properties. Jedoch überschreibt die Profilkonfiguration nicht generell eine existierende application.properties, sondern nur die explizit definierten Werte. Ganz allgemein betrachtet Spring Boot Konfigurationsdateien in folgender Reihenfolge:
- profilspezifische Konfigurationen außerhalb des Klassenpfads, beispielsweise config/application-test.properties
- allgemeine Konfigurationen außerhalb des Klassenpfads, z. B. config/application.properties
- profilspezifische Konfiguration innerhalb des Klassenpfads
- allgemeine Konfiguration innerhalb des Klassenpfads
Dabei gilt, dass der erste Treffer für einen Konfigurationswert alle anderen überschreibt. Das ermöglicht es, die Anwendung sehr einfach zur Laufzeit zu konfigurieren, da die Konfigurationen außerhalb des Klassenpfads die höhere Präzedenz haben.
Ein konkretes Beispiel
Nachdem wir nun die Grundlagen des Environments – Profile und Properties – betrachtet haben, wenden wir diese nun in einem konkreten Beispiel an. Im ersten Teil dieser Serie betrachteten wir die Spring Boot Auto Configuration anhand einer eigenen Auto Configuration für den SSHD des Apache-MINA-Projekts. Der Code für dieses Beispiel ist hier zu finden.
Die entstandene Auto Configuration konfigurierte automatisch den SSHD und integrierte automatisch eine konfigurierte ShellFactory. Wer die Codebeispiele aufmerksam verfolgt hat, dem ist aufgefallen, dass der Port und andere Konfigurationen statisch vergeben wurden. Das ist für ein einfaches Projekt, bei dem sich Konfigurationen nicht ändern müssen, ausreichend. Allerdings ist es gerade bei einem Port wahrscheinlich, dass er über die Lebenszeit einer Anwendung konfiguriert werden muss. Es ist nicht praktikabel, in jeder sich ergebenden Situation den Code zu ändern, denn speziell eine Auto Configuration wird üblicherweise als Library zur Verfügung gestellt, und diese sollte dann möglichst einfach anpassbar sein, ohne den Code der Library zu ändern.
Nehmen wir genau dieses Beispiel und betrachten verschiedene Möglichkeiten, die Auto Configuration zu beeinflussen. Die folgenden Beispiele beziehen sich auf unsere erstellte Auto Configuration, die Prinzipien lassen sich jedoch auf jede beliebige Spring Boot @Configuration anwenden.
Konfigurationswerte laden
Wie wir gesehen haben, handelt es sich bei der Konfiguration für Spring-(Boot-)Anwendungen um Properties, also einfache Key-Value-Paare. Darauf könnten wir über das Environment programmatisch zugreifen und unseren Anwendungscode entsprechend aufbauen. Das Environment lässt sich wie jede andere Bean injizieren. Listing 2 zeigt exemplarisch, wie der Wert für die Property mina.sshd.port aus dem Environment mittels der Methode getProperty() ausgelesen werden kann. Dabei wird der Wert, sofern vorhanden und kompatibel, in einen Integer konvertiert, was mit dem zweiten Parameter ausgedrückt wird. Kann der Wert der Property nicht in einen Integer konvertiert werden, wirft getProperty() eine entsprechende Exception. Ist die Property nicht definiert, liefert getProperty() lediglich null. Ist eine Property zwingend notwendig, kann auch direkt auf die Methode getRequiredProperty() zurückgegriffen werden, die eine Exception wirft, sollte die Property nicht definiert sein.
Listing 2
@Bean
public SshServer sshServer(Environment environment) {
final Integer port =
environment.getProperty("mina.sshd.port", Integer.class);
// ...
server.setPort(port);
// ...
}
Konfiguration injizieren
Dieses Vorgehen ist für einfache Anwendungsfälle ausreichend, wird jedoch bei steigender Zahl von Properties immer unübersichtlicher. Hier bietet Spring die @Value-Annotation, mit der sich Expressions schreiben lassen, deren Ergebnis beispielsweise einem Feld zugewiesen wird (Listing 3).
Listing 3
@Value("${mina.sshd.port}")
int port;
@Bean
public SshServer sshServer() {
// ...
server.setPort(port);
//...
}
In diesem Beispiel wird der Wert für die Property mina.sshd.port automatisch durch Spring an das Feld port gebunden. Dabei erledigt Spring mehrere Dinge zeitgleich: Zum einen wird geprüft, ob die Property überhaupt gesetzt wurde. Ist das nicht der Fall, erhalten wir eine Exception. Zudem wird die Konvertierung des Typs vorgenommen. Schlägt sie fehl, erhalten wir ebenfalls eine Exception. Die @Value-Annotation bietet noch weitere mächtige Möglichkeiten in Form von SpEL Expressions. Eine Betrachtung von SpEL würde den Rahmen dieses Artikels sprengen, es ist jedoch empfehlenswert, die Dokumentation zu lesen. Die @Value-Annotation erlaubt auch die Komposition von Annotationen. So können wir auf dieser Basis eine @SshdPort-Annotation erstellen (Listing 4).
Listing 4
/**
* Annotation at the field or method/constructor
* parameter level that injects the port of the SSHD.
*/
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD, ElementType.METHOD,
ElementType.PARAMETER, ElementType.ANNOTATION_TYPE})
@Value("${mina.sshd.port}")
public @interface SshdPort {
}
Soll nun der Port des SSHD erfragt werden, kann das einfach mittels einer Deklaration wie @SshdPort int port; bewerkstelligt werden. Das ist keineswegs ungewöhnlich und findet auch innerhalb von Spring Boot selbst Anwendung (mit der @LocalServerPort-Annotation).
Mit @Value haben wir einen einfachen Weg, um Properties wie beispielsweise Ports oder Ähnliches einfach verwendbar zu machen. Was ist jedoch mit komplizierteren Konfigurationen? Möchten wir beispielsweise eine Liste von Benutzern konfigurieren, die sich mit dem SSHD verbinden dürfen (sowie deren zugehörige Passwörter), gelangen wir schnell an die Grenzen der @Value-Annotation. Hier bietet Spring Boot das Konzept der Type-Safe Configuration, das wir eingehender betrachten wollen.
Type-Safe Configuration
Häufig gibt es nicht nur eine einzige Konfigurationsoption, meist müssen mehrere, teilweise in Verbindung stehende Konfigurationsoptionen angeboten werden. Betrachten wir unsere SSHD Auto Configuration, stellen wir schnell fest, dass wir mehrere Konfigurationsoptionen anbieten müssen:
- Port
- Session Idle Timeout
- Host Keys
- Benutzer
Diese Konfigurationsoptionen über @Value einzubinden, ist möglich, aber relativ aufwendig. Spring Boot bietet die Möglichkeit, diese Konfigurationsoptionen in Klassen zu gruppieren, die Werte automatisch zu konvertieren und in die jeweiligen Felder zu injizieren.
Das Kernelement einer Type-Safe Configuration ist ein POJO, das mit @ConfigurationProperties() annotiert ist. Diese Annotation instruiert Spring Boot, die Klasse im Application Context verfügbar zu machen und alle Felder der Klasse mit Werten aus dem Environment zu befüllen. Listing 5 enthält unsere MinaSSHDProperties, die die oben genannten Konfigurationsoptionen bereits enthält. Hier sollte man sich nicht bei einem ersten Blick auf die Klasse verunsichern lassen, denn eigentlich handelt es sich um ein einfaches POJO. Im Folgenden werden wir die einzelnen Elemente gezielt betrachten.
Listing 5
@ConfigurationProperties(prefix = "mina.sshd")
public class MinaSSHDProperties {
private int port = 8022;
private final Session session = new Session();
private final List<Resource> hostKeys = new ArrayList<>();
private final List<User> users = new ArrayList<>();
public int getPort() { /*...*/ }
public void setPort(int port) { /*...*/ }
public Session getSession() { /*...*/ }
public List<Resource> getHostKeys() { /*...*/ }
public List<User> getUsers() { /*...*/ }
public static class Session {
@DurationUnit(ChronoUnit.SECONDS)
private Duration idleTimeout;
public Duration getIdleTimeout() { /*...*/ }
public void setIdleTimeout(Duration idleTimeout) { /*...*/ }
}
public static class User {
private String name;
private String password;
public String getName() { /*...*/ }
public void setName(String name) { /*...*/ }
public String getPassword() { /*...*/ }
public void setPassword(String password) { /*...*/ }
}
}
Beginnen wir mit der @ConfigurationProperties-Annotation. Sie dient Spring Boot nicht nur als Marker, sondern definiert auch, welches Präfix die Konfigurationsoptionen erhalten. In diesem Beispiel definieren wir ein Präfix mina.sshd. Bei der Wahl des Präfix sind der Kreativität keine Grenzen gesetzt. Es ist jedoch ratsam, ein leicht verständliches Präfix zu verwenden, das Dopplungen vermeidet und ausdrückt, auf welche Komponente sich eine Konfiguration bezieht. Ein Präfix server ist problematisch, da nicht ersichtlich wird, um was für einen Server es sich handelt (und es zudem bereits durch Spring Boot belegt ist).
Damit die MinaSSHDProperties von Spring Boot beachtet werden, muss die Klasse über @EnableConfigurationProperties registriert werden. Da wir eine Auto Configuration bereitstellen, bietet sich hierfür die MinaSSHDAutoConfiguration an (Listing 6).
Listing 6
@EnableConfigurationProperties(MinaSSHDProperties.class)
@ConditionalOnClass(SshServer.class)
@Configuration
public class MinaSSHDAutoConfiguration {
// …
}
Nachdem wir Spring Boot entsprechend vorbereitet haben, betrachten wir nun die eigentliche MinaSSHDProperties-Klasse im Detail, beginnend mit dem Port. Der Port wird als int-Feld in der Klasse deklariert. Spring Boot muss nun entscheiden, welche Werte diesem Feld zugewiesen werden. Hierbei kommt ein relativ einfaches Namensschema zum Einsatz, bei dem das Präfix (mina.sshd) mit dem Feldnamen zusammengesetzt wird, getrennt durch einen Punkt. Daraus resultiert der Property-Name mina.sshd.port. Enthält das Environment eine Property mina.sshd.port, wird der Wert dieser Property dem Feld zugewiesen.
In manchen Situationen kann es jedoch hilfreich sein, die Properties einer Klasse weiter zu strukturieren. Betrachten wir den Idle Timeout, der sich auf eine Session bezieht. In diesem Fall kann er in einer eingebetteten Klasse gekapselt werden (Listing 5). Der idleTimeout ist in einer Session-Klasse gekapselt, die wiederum über das Feld session in den MinaSSHDProperties zu erreichen ist. Auch hier wird der Property-Name zusammengesetzt: mina.sshd.session.idleTimeout. Der idleTimeout ist dabei in Camel Case angegeben, was jedoch nicht die einzige Möglichkeit ist. Spring Boot bietet ein Relaxed Binding, das beispielsweise die mina.sshd.session.idle-timeout ebenfalls für das Binding in Betracht zieht. Diese Kebap Case genannte Notation erhöht vor allem in Properties-Dateien die Lesbarkeit.
Das Feld idleTimeout birgt eine weitere Besonderheit: Der Datentyp ist eine java.time.Duration. Eine Duration kann eine beliebige Zeitspanne definieren, von wenigen Nanosekunden bis zu Jahren. Eine Möglichkeit wäre es, immer alles in Nanosekunden anzugeben, was bereits bei Tagen zu sehr großen Zahlen führt. Mit der @DurationUnit-Annotation kann spezifiziert werden, ob die Angabe z. B. in Sekunden, Minuten, Stunden, Tagen oder gar Millennien erfolgt.
Auch Collections stellen für Spring Boot keine Herausforderung dar. Betrachten wir hierfür die Host Keys. Typischerweise werden bei einem SSHD mindestens zwei unterschiedliche SSH-Key-Typen hinterlegt (RSA und DSA), potenziell auch mehr. Daher ist hostKeys auch eine Collection, deren Elemente jeweils eine Spring Resource sind. Damit können wir die jeweiligen Host Keys mit den Mitteln des Spring Resource Frameworks referenzieren. Ein YAML-Beispiel ist in Listing 7 zu sehen.
Listing 7
mina:
sshd:
host-keys:
- classpath:ssh_host_dsa_key
- classpath:ssh_host_rsa_key
Bleibt nur noch, die Benutzer und deren Passwort zu konfigurieren. Natürlich sollte in einer produktiven Library eine wirkliche Benutzerverwaltung integriert werden oder beispielsweise auf Spring Security aufbauen. Für unsere Betrachtung soll uns jedoch eine einfache Konfiguration von Benutzern und deren Passwörtern genügen. Auch hierbei haben wir wieder eine Collection, diesmal jedoch sind die Elemente vom Typ User. Die Klasse User ist ein weiteres einfaches POJO, das lediglich die Felder für den Namen sowie das Passwort eines Users enthält. Listing 8 enthält eine zugehörige YAML-Konfiguration.
Listing 8
mina:
sshd:
users:
- name: admin
password: password
- name: root
password: unsecure
Jeder Eintrag aus einem YAML-Dokument wird in ein entsprechendes User-Objekt umgesetzt. Damit haben wir rein deklarativ ein sehr einfaches Benutzermanagement implementiert.
Validierung
Was geschieht jedoch, wenn die von einem Entwickler vorgenommene Konfiguration fehlerhaft ist? Betrachten wir beispielsweise die Portnummer. Da wir in der Klasse MinaSSHDProperties den Port als int deklariert haben, wird Spring Boot bereits sicherstellen, dass sich der angegebene Wert in einen Integer konvertieren lässt. Wird jedoch beispielsweise eine negative Zahl angegeben, sieht Spring Boot das als grundsätzlich gültigen Wert an. In vielen Fällen kann die Validierung eines Werts der eingebundenen Library überlassen werden, wenn sie ohnehin die Werte validiert. Ist jedoch eine weitere Validierung nötig, bietet sich der Einsatz von Jakarta Bean Validation (JSR-303 und JSR-349) an. Die Integration in Spring Boot ist sehr einfach. Wir benötigen eine zusätzliche Abhängigkeit zum spring-boot-starter-validation, der die notwendigen Abhängigkeiten bereitstellt. Damit können wir unsere MinaSSHDProperties um Validierungsregeln erweitern (Listing 9).
Listing 9
// ...
import org.springframework.validation.annotation.Validated;
import javax.validation.constraints.Max;
import javax.validation.constraints.Min;
@ConfigurationProperties(prefix = "mina.sshd")
@Validated
public class MinaSSHDProperties {
@Min(1)
@Max(65535)
private int port = 8022;
// ...
}
Damit Spring Boot eine Validierung durchführt, muss die Klasse mit @Validated annotiert sein, dann können alle Validierungsannotationen von Jakarta Bean Validation verwendet werden. Im Beispiel wird der Wertebereich des Ports auf gültige Werte eingegrenzt. Ist der konfigurierte Wert ungültig, wird die Anwendung nicht starten und eine qualifizierte Fehlermeldung liefern.
Auto Complete für die Konfiguration
Bei einer Vielzahl von Konfigurationsmöglichkeiten kann man schnell den Überblick verlieren. Idealerweise sollte uns jedoch unsere IDE auch beim Erstellen der Konfigurationen unterstützen. Hierfür bietet Spring Boot zusätzlich Metadaten über die konfigurierbaren Einstellungsmöglichkeiten an. Verwendet man eine IDE wie beispielsweise IntelliJ IDEA, mit Unterstützung für die Konfigurationsmetadaten, wird eine Autovervollständigung beim Editieren angeboten (Abb. 3).
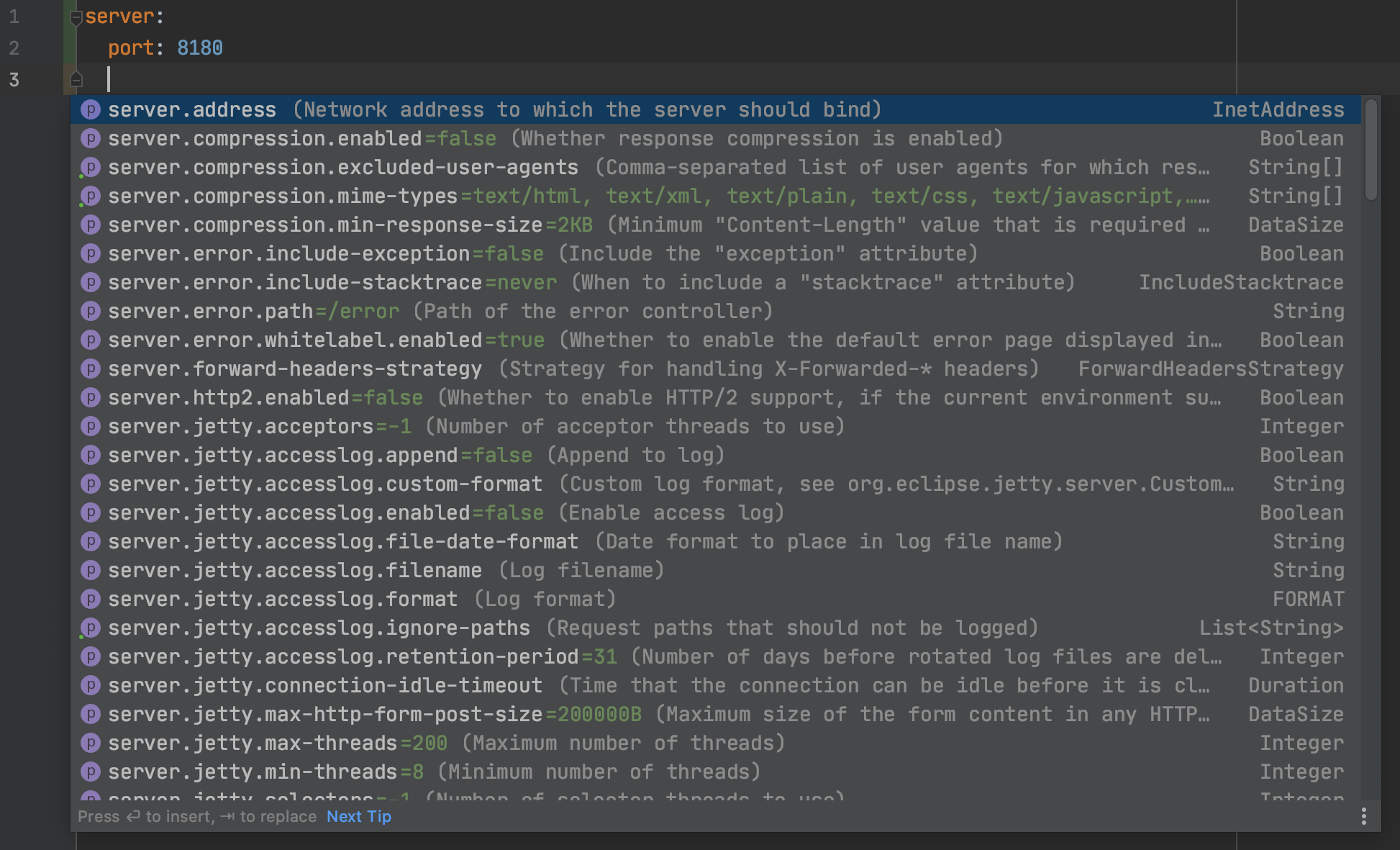
Diese Autovervollständigungen beruhen auf Metadaten in den jeweiligen Projektartefakten. Zu finden sind diese Metadaten in META-INF/spring-configuration-metadata.json der jeweiligen Bibliotheken, es ist auch möglich, sie von Hand zu erstellen. Das Format der spring-configuration-metadata.json ist ausführlich dokumentiert. Gebräuchlicher ist es, die Metadaten automatisch generieren zu lassen. Hierfür bietet Spring Boot einen Annotation Processor an, der die Metadaten automatisch generiert, basierend auf der @ConfigurationProperties-Annotation und den erkannten Feldern. Damit der Annotation Processor die Arbeit aufnimmt, ist lediglich eine einzige Dependency notwendig, wie in Listing 10 exemplarisch für Maven zu sehen.
Listing 10
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> <optional>true</optional> </dependency>
Damit werden die Metadaten bei jedem Anwendungs-Build automatisch erstellt und stehen dem Konsumenten unserer Auto Configuration zur Verfügung.
Fazit
Spring Boot macht das Konfigurieren von Anwendungen einfach. Mit diesem Konzept lassen sich nicht nur Konfigurationen einfach und sauber strukturieren, sondern es bietet viele Möglichkeiten, die eigene Anwendung für die verschiedensten Situationen zu konfigurieren.
Spring Ecosystem auf der JAX & W-JAX:
● Spring-Boot-Apps als GraalVM Native Images
● Workshop: Moderne Web-Apps mit Angular und Spring Boot




