
„Design before Implementation” gehört zu den zentralen Prinzipien guter Softwareentwicklung – und wurde in vielen Projekten in den letzten Jahren vernachlässigt. Mit dem Aufkommen von AI-gestützter Entwicklung entsteht nun oft der Eindruck, man könne aus lose formulierten Geschäftsregeln direkt funktionierende Software erzeugen. Das Gegenteil ist jedoch der Fall: Gerade wenn AI Teil realer Anwendungen wird, steigen die Anforderungen an Klarheit, Struktur und präzise Entwürfe. Der Beitrag zeigt, warum detaillierte Spezifikationen und sauberes Systemdesign nicht an Bedeutung verlieren, sondern im Zeitalter von Enterprise AI wichtiger werden als je zuvor.
Um es gleich vorwegzusagen: Von sauberem Design profitiert jede Softwareentwicklung, ob mit oder ohne KI. Wenn dafür eine „Renaissance“ entsprechender Prinzipien notwendig ist, dann ist sie ohnehin überfällig und der Zeitpunkt perfekt. In vielen Projekten, die nach iterativen/agilen Verfahren arbeiten, sind klassische Techniken leider auf der Strecke geblieben. Design gehört aus zwei Gründen dazu.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Zum einen, weil „agil“ gern als Ausrede für das Weglassen jeglicher Dokumente – also auch jeglicher Designdokumente – herhalten musste. Das ist eine Missinterpretation, die letzten Endes den Begriff „Software Craftsmanship“ hervorgebracht hat [1]. Abläufe und Strukturen in nicht trivialer Software bedürfen detaillierter Beschreibungen, die mit dem Auftraggeber abgestimmt sind. Was dem Handwerker seine Bauzeichnung ist und dem Musiker seine Partitur, ist dem Software Craftsman seine Softwarespezifikation.
Zum anderen – und das macht auch Anhängern des präzisen Entwurfs das Leben schwer –, weil es kaum ein Werkzeug gibt, das sich komfortabel für eine iterative Entwicklung der Entwürfe eignet. Zum Beispiel hat kein einziges bekanntes UML-Tool einen Änderungsmodus mit einer hybriden Darstellung von bestehendem, neuem und gelöschtem Inhalt wie ihn etwa Microsoft Word hat. Das ist ein Hauptgrund, warum MS Word über Jahrzehnte hinweg Grundlage für iterative Systemspezifikationen war. Andererseits ist Word kein Modellierungswerkzeug, sondern „nur“ ein Textverarbeitungsprogramm. Wenn eine KI die Kontrollstrukturen einer Ablaufbeschreibung verstehen soll – Schleifen, Verzweigungen, Ausnahmen usw. –, dann ist eine Freitextbeschreibung die falsche Basis.
Renaissance heißt also nicht einfach zurück zu den alten Methoden und Werkzeugen, sondern die Prinzipien des Software-Engineerings, die sich über Jahrzehnte bewährt haben, mit einer neuen Generation von Werkzeugen umzusetzen, die den heutigen Anforderungen an Agilität und KI-Integration gerecht werden. Selbst Vibe Coder merken das zunehmend und bringen den Begriff „Spec-driven Development“ als Trendthema auf [2], wobei dort aktuell andere Schwerpunkte gesetzt werden.
Warum Design wichtig ist
Mit Design bzw. Entwurf ist hier primär gemeint: eine detaillierte Beschreibung von Abläufen in den System-Use-Cases einer Software. Die Beschreibungen sind einerseits möglichst fachorientiert und natürlichsprachlich formuliert, andererseits aber so präzise, dass sie ohne Risiko von Fehlinterpretationen in Code übersetzt werden können. Sie fußen dabei auf einem Vokabular von Geschäftsobjekten und deren Beziehungen untereinander. Beides – die Geschäftsobjekte und die Abläufe – sind verbindliche Grundlagen für alle Stakeholder, vom Auftraggeber über die Entwickler bis zu den Testern. Das sind seit jeher zentrale Konzepte von OOA/OOD und Domain-Driven Design. Wenn es um UI-Funktionalität geht, kommen außerdem Oberflächenspezifikationen hinzu (z. B. Wireframes), die in diesem Artikel aber außen vor bleiben.
Solche Softwareentwürfe sind in ihrer Funktion einer Bauzeichnung beim Bau oder Umbau eines Hauses nicht unähnlich. Und wer jetzt einwendet, dass Häuser im Gegensatz zu Software nicht ständigen Änderungen unterliegen, der möge an Solaranlagen, Wallboxen, Wärmepumpen, Glasfaser usw. denken. Ein Segen, wenn dann gute, aktuelle Grundrisse und Leitungspläne des Gebäudes vorliegen. Gerade iteratives Vorgehen profitiert von jederzeit aktuellen Entwürfen.

Abb. 1: User Story für die Altersdarstellung von Chatbeiträgen
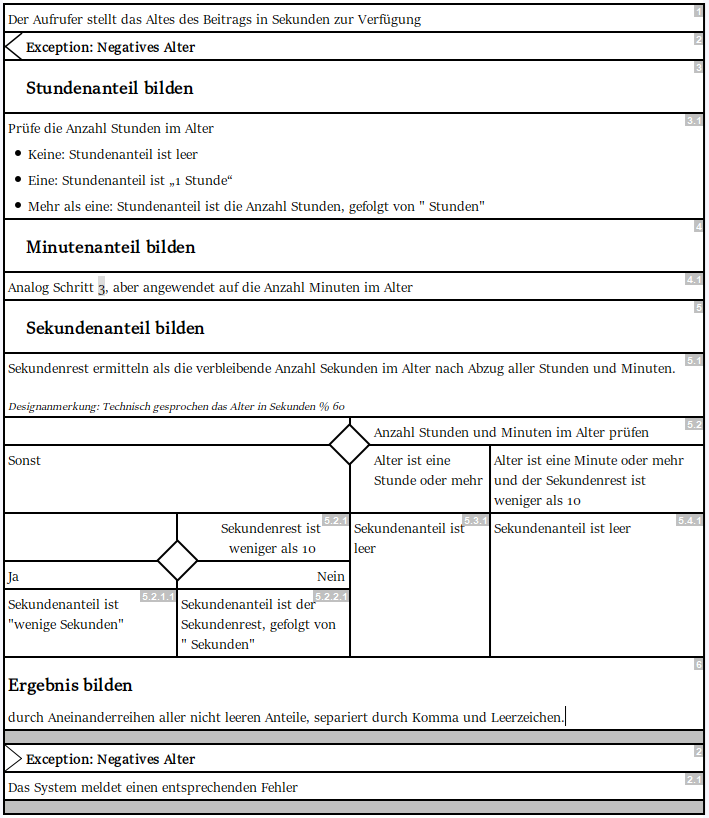
Abb. 2: Systemspezifikation für Altersdarstellung als „Aktogramm“
Zur Verdeutlichung zeigt Abbildung 1 ein einfaches Beispiel für eine Handvoll Geschäftsregeln, wie sie in einer User Story stehen könnten, und Abbildung 2 eine daraus entworfene Ablaufbeschreibung in einer Notation, die später noch genauer betrachtet wird. Die Entwurfsform und das Software-Engineering dahinter sind bewährte Konzepte, die auch in hochkomplizierten Szenarien Anwendung finden. In dem Trivialbeispiel aus Abbildung 1 geht es um die leserfreundliche Darstellung des Alters von Beiträgen in einem Chat. Statt 3 621 Sekunden seit der Veröffentlichung soll dort z. B. „1 Stunde“ stehen. Völlig unkritische Funktionalität, aber es könnten natürlich auch die Ratingregeln einer Bilanzanalyse sein, die in einer Bank über die Vergabe von Millionenkrediten entscheiden.
Was passiert nun, wenn ein unbedarfter Entwickler direkt aus den Geschäftsregeln heraus Code produziert? Die Anforderungen klingen einfach, also wird er direkt drauflos programmieren, ist aber natürlich trotzdem gezwungen, sich Gedanken über die Struktur des Codes zu machen. Die Geschäftsregeln sagen ja nur, was zu tun ist, aber nicht wie. Was sich jetzt abspielt, nennt sich „design a little, code a little“ – ein Antipattern! Unter [3] kann man nachlesen, wieso es anti ist. Es entstehen schlechtes Ad-hoc-Design und schlechter Code. Und was ändert sich, wenn man stattdessen mit einem KI-Agenten arbeitet? Man bekommt den schlechten Code schneller geliefert, das ist alles.
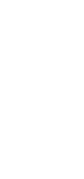
Bei einem KI-Coding-Dojo im vergangenen Herbst durften sich Github Copilot und Junie mit verschiedenen LLMs an dieser Aufgabe versuchen, ohne dass dabei Code entstand, der durch weiteres Prompting irgendwann eine vernünftige Gestalt angenommen hätte. Man wird also im Zeitraffer direkt Zeuge des Problems, und die KI-Agenten zeigen uns im Grunde nur: So naiv geht es nicht. Dabei ist noch gar nicht berücksichtigt, dass die Fachbereiche ihre Anforderungen eher „in loser Schüttung“ liefern – ohne Anspruch auf Vollständigkeit und Schlüssigkeit, dafür mit unausgesprochenen Details zwischen den Zeilen.
Ganz anders sieht das Ergebnis basierend auf der Ablaufspezifikation in Abbildung 2 aus. Hier ist der Entwurf in einer separaten Phase vorweg entstanden und wurde so beschrieben, dass alle Beteiligten das Prozedere der Software nachvollziehen können. Die Beschreibung geschieht in einer Weise, dass man quasi bei Ausfall der Software einen Sachbearbeiter hinsetzen könnte, damit er dem Ablauf folgend die Arbeit manuell erledigt, wenn auch eine Milliarde Mal langsamer. Sowohl Entwickler als auch KI-Agenten können auf dieser Basis brauchbaren Code erstellen, der sich an der Struktur des spezifizierten Ablaufs orientiert und somit auch leicht darauf zu prüfen ist, ob er überhaupt das tut, was gefordert ist. Bei späteren Änderungen im Rahmen iterativer Entwicklung sind die in der Spezifikation vorgenommenen Modifikationen entsprechend leicht im Code zu verorten.
Hier spielen gleiche mehrere Faktoren eine Rolle, die eine vorgelagerte Designphase so wertvoll machen, die sich in späteren Phasen auszahlt:
- Klarheit des Entwurfs: Wenn man sich zwingt, ein für „Normalsterbliche“ nachvollziehbares Verfahren zu beschreiben, das das fachlich gewünschte Ergebnis erzielt, dann stellt man häufig fest: Die vermeintlich bereits glasklaren Gedanken dazu sind unklarer, als man glaubte. Fast jeder kennt das: Sobald man versucht, jemand anderem zu erklären, was man vorhat, zerbröselt eine undurchdachte Idee zu Staub. Eine gute Idee hingegen wird dadurch gestärkt und verfeinert.
- Analytisches Denken: Es dauert u. U. ziemlich lange, bis man ein leicht zu verstehendes Vorgehen formuliert hat, und das ist gut so. Es zwingt den Entwickler, aus dem schnellen impulsiven Denken in das langsame analytische Denken zu wechseln. Es werden dabei ganz andere Hirnregionen aktiv [4] und das Ergebnis ist ein völlig anderes als bei „design a little, code a little“.
- Kurze Feedbackschleifen: Sind die Entwürfe für alle lesbar, können auch die Fachanforderer sie beurteilen und dazu beitragen. Hier entstehen schnelle Feedbackschleifen, von denen agile Entwicklung ohne Spezifikationen nur träumen kann. Schwere Missverständnisse und Konzeptfehler fallen nicht erst nach zwei Wochen in der Sprintreview auf, sondern schon nach zwei Stunden in der frühestmöglichen Phase der Softwareentwicklung. Die Rule of Ten [5] erlaubt da schon viel Spezifikationsarbeit, bevor eine Überfrachtung entsteht.
Um es klar zu betonen: Es geht nicht um eine Rückkehr zum Wasserfallmodell! Die Entwürfe müssen iterativ weiterentwickelt werden können. Sie sind keine Wegwerfprodukte aus einer initialen Anstrengung, sondern lebende Artefakte des Software-Engineerings. Das funktioniert nur, wenn sie in geeigneten Werkzeugen erstellt werden und tagtäglich Mehrwert schaffen. Das ist eine der Herausforderungen, die sich bewusst zu adressieren lohnt.
Entwürfe MIT statt VON der KI
Entwurfsarbeit ist soooo anstrengend – kann das nicht die KI machen? Kann sie nicht, denn sonst wäre ja in dem oben erwähnten Dojo vom Fleck weg guter Code entstanden. Sie ist Konsument der Entwürfe. Die Diskussionen, ob und wie weit KI auch Entwürfe herstellen kann, füllen derzeit die Kaffeeküchen aller IT-Unternehmen der Welt.
Die in diesem Artikel vertretene Meinung fußt auf folgender Sichtweise: Der Abschnitt zuvor erwähnt die Feedbackschleifen, die einen guten Entwurf ausmachen. Menschen, die solche Entwurfsarbeit lieben, streben dabei nach Erkenntnisgewinn und nach einem gemeinsamen Verständnis der Welt zwischen den Beteiligten. In ihren Entwürfen sind sie darauf aus, fachliche Notwendigkeiten und technische Möglichkeiten optimal auszubalancieren. Sie treiben diesen Vorgang bis zu einem Punkt, an dem sie sicher sind, dass die folgende Umsetzung kein Abenteuer mehr ist, sondern zielgerichtetes Handwerk mit einem vorhersagbaren Ergebnis. Software Craftsmanship eben.
Künstliche Intelligenz heutiger Bauart hingegen will auf gar nichts hinaus. Es ist eine hochentwickelte Mustererkennungsmaschine, der wir Menschen ihrer guten Ausdrucksweise wegen gerne Intelligenz, Empathie und intrinsische Motivation zuschreiben. Das ist eine fundamentale Denkfalle, so alt wie der Begriff „künstliche Intelligenz“ selbst [6]. Um KI in der Entwicklung komplizierter Softwaresysteme zu nutzen, muss sie mit klaren Mustern und Strukturen gefüttert werden. Das Ziel ist schließlich keine grob in die richtige Richtung gehende „interessante Inspiration“, sondern exakter, bis auf die letzte 0 und 1 stimmiger Code. Mit „exakt“ haben es LLMs aber naturbedingt nicht so, weshalb die Klarheit der Strukturen und Muster umso wichtiger wird. Und wo kommt diese Klarheit her? Entwurfsarbeit!
Entwürfe sind von der KI also nicht zu erwarten, was eigentlich eine gute Nachricht ist: Wer sich auf diese Tätigkeit versteht – tendenziell also jeder Clean Coder – wird so schnell nicht arbeitslos. Es geht wohlgemerkt um komplizierte Softwaresysteme mit Hunderttausenden Zeilen. Energiewesen, Bilanzanalyse, Touristik und Kundenbindungsprogramme sind einige der Umfelder, in denen die hier dargestellten Konzepte Anwendung finden. Abbildung 3 zeigt bespielhaft aus der Vogelperspektive eine vollständige Use-Case-Spezifikation mittlerer Größe, um einen Eindruck zu vermitteln, wie so etwas in echten Projekten aussieht. Die Ablaufbeschreibung ist hier eingebettet in eine Präambel, Vor- und Nachbedingungen, Geschäftsklassendiagramme, Wireframes usw. Auch wenn man die Texte in dieser Auflösung nicht lesen kann, sollte deutlich werden, dass hier keine triviale Logik beschrieben ist. Ohne Spezifikation ist eine permanente Fortentwicklung solcher Use Cases viel zu ineffizient. Natürlich lässt sich die Arbeit an großen Entwürfen prima mit KI unterstützen, wie Matthias Bartels in seinem Artikel „Mit automatisierter Review zum gelungenen Entwurf“ in dieser Ausgabe des Java Magazins zeigt [7]. Um die zentralen Aspekte zu erläutern, soll aber im Weiteren das oben vorgestellte kleine Beispiel genügen.

Abb. 3: Echte Use-Case-Spezifikation mittlerer Größe, Vogelperspektive
Der eigene Kopfcomputer bleibt also der Ort, wo die Entwürfe letztlich entstehen, wo sie aber nicht bleiben dürfen. Machen wir sie Mensch und Maschine zugänglich, dann maximieren wir die Möglichkeit der Zuarbeit von beiden Seiten. An dieser Stelle kommt passendes Tooling ins Spiel. Künstliche Intelligenz hat zwar erstaunliche Fähigkeiten, fast beliebigen Input zu verarbeiten. Die Qualität der Ergebnisse hängt aber doch davon ab, wie präzise die Eingaben strukturiert und formuliert sind.
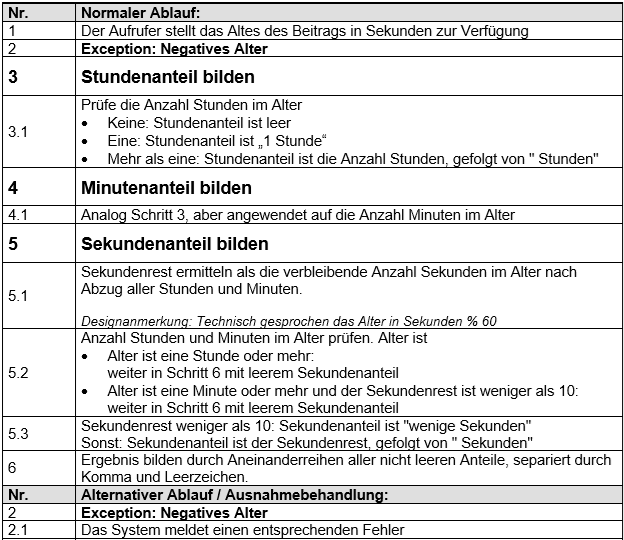
Abb. 4: Systemspezifikation für Altersdarstellung in Microsoft Word
Abbildung 4 zeigt eine alternative Darstellung der Spezifikation aus Abbildung 2, basierend auf einem viel genutzten Microsoft-Word-Template, wie eingangs schon erwähnt wurde. Es soll beispielhaft die Problematik zeigen, die entsteht, wenn man bequem greifbare Text- und Maltools zum Modellieren missbraucht und damit der KI und auch jeder anderen maschinellen Unterstützung das Interpretieren schwer macht. Was direkt auffällt: Die in Abbildung 2 auf den ersten Blick erkennbaren Verzweigungen (dargestellt durch Diamanten) sind nicht mehr unmittelbar zu sehen. Sie liegen textuell beschrieben vor, was dem tabellarischen Layout geschuldet ist, um automatische Nummerierung und Änderungsstabilität zu gewährleisten. Heftige Kompromisse also, die für menschliche Leser vielleicht ein verkraftbares Problem sind. Aber ob eine KI daraus die gemeinte Ablaufstruktur noch gut herauslesen kann? Noch ungünstiger wird es, wenn für Remotearbeit auf kostengünstige, webbasierte Kollaborationswerkzeuge zurückgegriffen wird (z. B. Confluence). Für die Modellierung sind diese Tools nicht gedacht.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Wie sieht’s mit UML-Aktivitätsdiagrammen oder BPMN aus? Hier lassen sich Abläufe modellieren und damit auch gut maschinell auswerten. Leider tauscht man damit die Vor- und Nachteile gegenüber MS Word quasi eins zu eins aus. Änderungsverfolgung, automatische Nummerierung und änderungsstabiles Layout sind futsch. Davon abgesehen brauchen diese Notationen viel Platz und vertragen kaum Text für notwendige Details, die man stattdessen in eine verborgene Doku oder angeheftete Textblasen auslagern muss. Also wieder reichlich Kompromisse in anderer Form, wie in Abbildung 5 exemplarisch dargestellt ist. Das sind alles keine unüberwindbaren Hürden und keine Ausrede dafür, ohne Entwürfe zu arbeiten. Aber vielleicht ist es für eine neue Mensch-Maschine-Zusammenarbeit beim Entwerfen Zeit für „New Kids on the Block“ …
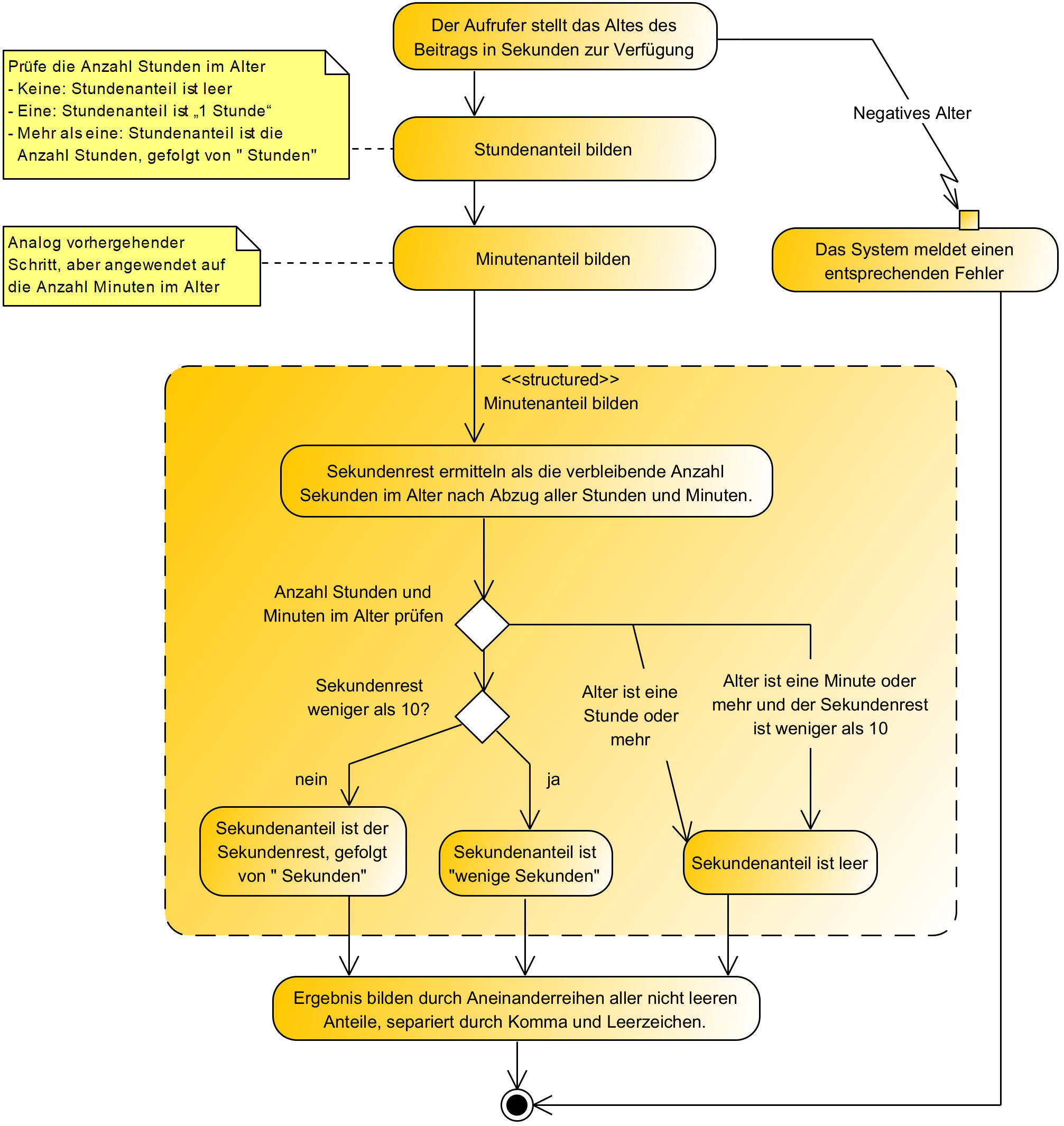
Abb. 5: Systemspezifikation für Altersdarstellung als UML-Aktivitätsdiagramm
Aktogramme
Abbildung 2 zeigt, wie wir gesehen haben, eine Spezifikation für das Beispiel der Altersdarstellung von Chatbeiträgen in Form eines „Aktogramms“. Es handelt sich um eine für Spezifikationen weiterentwickelte Form von Struktogrammen – auch als Nassi-Shneiderman-Diagramme bekannt [8]. Sie sind noch älter als die erste Erwähnung von „Design before Implementation“, dienten aber genau diesem Prinzip. Dabei lag ihr Fokus seinerzeit auf der strukturierten Darstellung von Programmcode, als Letzterer noch 70er-Jahre-Assembler war (so alt sind Struktogramme).
Dieses Problem ist mit Hochsprachen und IDEs mit Syntax-Highlighting inzwischen besser gelöst. Für Spezifikationen werden sie aber wieder interessant, wenn man sie ein bisschen aufmöbelt. Der Begriff „Aktogramm“ ist aus „Struktogramm“ und „Aktivitätsdiagramm“ zusammengesetzt, weil die Notation im Kern dem Darstellungskonzept von Struktogrammen folgt, aber einige Anlehnungen an UML-Aktivitätsdiagramme aufweist. So zum Beispiel die in Abbildung 2 gut erkennbaren Diamanten als Ausdrucksform für Verzweigungen, weil die originale Dreiecksform von Struktogrammen unordentlich wirkt, wenn sie in einem Ablauf wiederholt auftaucht. Es steckt also einiges an Feinschliff in der Notation, um sie für Spezifikationen größeren Umfangs tauglich zu machen. Schaut man sich das Aktogramm aus Abbildung 2 und das entsprechende UML-Aktivitätsdiagramm aus Abbildung 5 aus größerer Entfernung an, bemerkt man die beiden Diamanten recht gut als Gemeinsamkeit.
Das Aktogramm wurde mit dem Java-WYSIWYG-Editor Specman [9] erstellt, der verschiedene praktische Eigenschaften von Word und UML zusammenbringt, z. B.
- Änderungsstabiles Layout: Wenn man hier Schritte in den Ablauf einbringt oder entfernt, gerät das Layout nie durcheinander wie bei Aktivitätsdiagrammen
- Änderungsmodus: Wie in Word, aber mit einer deutlicheren farblichen Hervorhebung wie mit einem Textmarker (3); man scrollt einfach durch und schaut sich eine gelbe Markierung nach der nächsten an, um die am Use Case vorgenommenen Änderungen zu erkennen
- Automatische Schrittnummerierung: Sehr wichtig für Abstimmungsprozesse; „Schau dir mal Schritt 3.4.2 an, ob ich dich gestern richtig verstanden habe“, ohne Nummern wird das Absprechen komplizierter Abläufe schwierig
- Schrittreferenzen: Automatisch aktualisierte Referenzen auf die Nummern anderer Schritte in den Beschreibungen; in Word Usus, in UML ein Manko
- Viel Inhalt: Wir können uns nicht aussuchen, ob die Geschäftslogik einfach oder kompliziert ist, und die Notation darf uns im Fall der Fälle nicht beschränken; in Specman kann man aber jeden untergliederten Schritt (Schleifen, Verzweigungen, Untersequenzen) in der Ansicht zusammenklappen, wenn man an deren Inhalt gerade nicht interessiert ist
- Kontrollstrukturen: Sind gut erkennbar – nicht so gut wie in UML, aber viel besser als in Word; hinzu kommt eine wichtige Erweiterung gegenüber Struktogrammen: Letztere kennen zwar sogenannte Breaks als Entsprechung zum Werfen einer Exception, aber es fehlt die Entsprechung für das Fangen; in Spezifikationen ist es aber wichtig, wie das System mit fachlich relevanten Ausnahmen umgeht, also nicht mit NullPointerException und OutOfMemory– das gehört als querschnittliches Verfahren in die Architekturdoku –, sondern mit Fällen wie „Kunde ist gesperrt“ oder „Zahlungsart ungültig“
Specman speichert die Diagramme in einem JSON-Format, aus dem eine KI die Struktur des Ablaufs gut ablesen kann. Muss sie so etwas aus Bildern ablesen, führt das zu einer höheren Anfälligkeit für Fehlinterpretationen und kostet wesentlich mehr Zeit (und Tokens).
Beim Coding auf Grundlage von Aktogrammen können KI und menschliche Entwickler einige Aspekte direkt übernehmen. Ein Beispiel ist die Unterstrukturierung, die man beim Entwurf komplizierter Abläufe in Aktogrammen automatisch vornimmt. Sie lässt sich bei der Implementierung für das Designprinzip „Single Level of Abstraction“ nutzen. Ein erneuter Blick auf Abbildung 2 zeigt beispielsweise, welche Schritte die oberste Spezifikationsebene bilden – die Schritte mit einstelliger Schrittnummer. Man darf also erwarten, dass auf der obersten Codeebene für die Funktionalität eine Abfolge von Funktionsaufrufen zu finden ist, die genau das widerspiegelt:
- Absicherung gegen negative Angaben
- Bildung des Stundenanteils
- Bildung des Minutenanteils
- Bildung des Sekundenanteils
- Zusammenstellen des Ergebnisses aus den Anteilen
Es stellt sich für den Entwickler nicht die Frage, ob das eine funktionierende und sinnvolle Strategie zur Erfüllung der Anforderungen ist. Das wurde im Vorfeld in der Entwurfsphase ausgetüftelt. Idealerweise unter seiner direkten Mitarbeit oder sogar Federführung, denn die Entwürfe sind nur brauchbar, wenn sie mit technischem Sachverstand entstehen. Dass Fachbereiche oder Businessanalysten das zukünftig selbst machen und dann nur noch eine KI anwerfen, ist also unwahrscheinlich.
Speckit und Co.
Ausgerechnet die junge Szene der Vibe Coder [10] bringt das Thema Spezifikation im Zusammenhang mit KI wieder ins breite Bewusstsein. Trotz zweifellos höherer Schmerzresistenz bzgl. der Codequalität sind die Erkenntnisse dort offenbar die gleichen wie in dem oben beschriebenen KI-Dojo: Von Hello-World-Programmen abgesehen führt Coding ohne Design innerhalb kürzester Zeit in die Unwartbarkeit. Also entstehen auch in diesem Umfeld Spezifikationswerkzeuge, die allerdings nicht den Anspruch haben, die Entwürfe für alle Stakeholder lesbar zu machen. Speckit [11] ist so ein Werkzeug, das eine Plaintext-basierte Notation verwendet. Die Zugänglichkeit aus einer IDE oder Kommandozeile heraus genügt, weil es nur um verbesserte Kommunikation zwischen Entwickler und KI geht. Andererseits reicht der Anspruch in Richtung Coding so weit, dass die KI auf reproduzierbare Weise vollständige Applikationen implementieren soll.
Der Verbrauch kostbarer KI-Tokens gilt bei Speckit allerdings als enorm, was die leichtgewichtigere Alternative OpenSpec [12] zu verbessern verspricht. Dafür hat Letztere aber noch weniger mit Spezifikationen gemeinsam, wie sie in diesem Artikel gemeint sind. Es geht hier eher um die Beschreibung von Arbeitsaufträgen an die KI. Immerhin entsteht auf diese Weise Wiederholbarkeit und Nachvollziehbarkeit, statt dass der Code über geheimnisvolles Ad-hoc-Prompting immer wieder überraschend anders entsteht [13].
Nassi
Plaintext-basierte Spezifikation und hoher Detailgrad sind übrigens kein Widerspruch. Neben Specman gibt es den Aktogramm-Editor Nassi [14], der einen solchen Weg verfolgt und die für Fachanforderer verständlichen Diagramme in HTML-Form generiert. Dieser andere Ansatz für die Erstellung der Aktogramme führt zu einigen Unterschieden darin, wie sich der Spezifikationsvorgang in das Software-Engineering integriert. Im Kern verfolgt Nassi aber dieselbe Intention wie Specman.
In seinem Artikel „Aktogramme als Kommunikationsmedium“ in dieser Ausgabe des Java Magazins stellt Jan Hermanns den Editor ausführlich vor und geht außerdem tiefer auf iterative Entwurfsarbeit ein [15]. Beide Editoren sind Open Source.
KI auf Aktogrammen
Mit maschinenlesbaren, feingranularen und klar strukturierten Entwürfen kann die KI nun auf vielfältige Weise unterstützen, ohne dabei ausgeprägt in die Irre zu laufen oder zu halluzinieren.
Das naheliegende erste Einsatzgebiet ist die Validierung der Spezifikation selbst. Nicht so sehr im Sinne von: Beschreibt die Spezifikation das, was gebraucht wird? Das zu entscheiden ist Aufgabe der Fachbereiche im Rahmen ihrer Reviews. Deswegen ist gute Lesbarkeit für uns Menschen so wichtig. Eine KI kann aber prüfen, ob die Abläufe in sich logisch konsistent und vollständig sind oder ob sie „lose Enden“ haben. Matthias Bartels geht darauf in seinem Artikel ein [7].
Auch die Validierung von Code gegen die Spezifikation – ein zentraler Bestandteil jeder Code-Review – lässt sich teilautomatisieren. Wenn sich der Code sauber an der Struktur der Spezifikation orientiert, dann ist eine KI wie beispielsweise Claude Code ziemlich gut in der Lage, die Übereinstimmung zu prüfen.
Matthias Bartels vertieft auch diesen Aspekt in seinem Artikel, da er ein wichtiges Sicherheitsnetz für die Frage aller Fragen ist: Kann die KI aus genügend präzisen Beschreibungen zielgerichtet Code generieren, der exakt die spezifizierte Funktionalität realisiert? Vorzugweise, ohne dass die Spezifikation dafür den Umfang des Codes selbst annimmt.
Ein klares „Jein“
Es müssen Stand heute noch viele zusätzliche Bedingungen geschaffen werden, um in komplizierten Systemen nennenswert Code aus Entwürfen generieren zu können. Neben der Spezifikation der Geschäftsobjekte (siehe unten) braucht KI noch eine ganze Menge mehr saubere Strukturen – und zwar in der Architektur. Wenn die KI auf eine Weise coden soll, dass es in eine größere Codebasis passt, dann muss sie darin Muster für alles vorfinden, was es zu coden gibt. Sie verwendet sonst munter alles durcheinander, wovon sie in ihrem angelernten projektfremden Wissen meint, dass es passen könnte. Wenn also im Code keine Ordnung herrscht, dann beschleunigt die KI das Broken-Window-Problem [16], und die Unordnung wächst noch schneller als mit menschlichen Entwicklern.
In einer unordentlichen Codebasis empfiehlt es sich, zunächst eine „Insel der Ordnung“ zu schaffen, an der sich die KI orientieren kann. Ein erfolgreich praktizierter Ansatz besteht darin, in einem verlebten Bestandsprojekt einen getrennten Source-Folder einzurichten, in dem sich ausschließlich blitzsaubere Referenzimplementierungen mit minimalem Umfang für alle Bausteine der Architektur befinden, die als verbindliche Muster fungieren. Wie sieht eine Entity aus? Wie sieht ein Testdaten-Builder für eine Entity aus? Wie ist ein Repository mit Cache für datenbankbasierte Konfigurationsdaten aufgebaut? Die Codebausteine in diesem Folder dienen KI und menschlichen Entwicklern als garantiert unverschmutzte Vorbilder und landen nicht in der Auslieferung. Auch hier gilt das gleiche Prinzip: Design before Implementation.
Ein anderer Punkt ist die Minimierung des Kontexts, den die KI für eine Aufgabe berücksichtigen muss. Je kleiner, desto besser. Anforderungsseitig sind präzise Spezifikationen eine gute Voraussetzung. Codeseitig empfiehlt Simon Martinelli in einem kürzlich veröffentlichten Podcast zu Spec-driven Development [17] den Architekturansatz der Self-contained Systems [18]. Grundidee ist die Zerlegung eines größeren Softwaresystems in Säulen unabhängiger Subsysteme, ohne in das Extrem von Microservices abzugleiten. Jedes der Subsysteme erfüllt eine klar umrissene fachliche Aufgabe und verfügt über eigene Datenhaltung und eigenes UI.
„Self-contained“ heißt: Die Subsysteme sind in sich abgeschlossen und brauchen nur minimalen Kontakt zueinander. Ein System-Use-Case bezieht sich auf Funktionalität innerhalb eines dieser Subsysteme, was dann auch für dessen Spezifikationen gilt. Eine KI, die auf Grundlage solcher Spezifikationen Code generiert, muss sich also nur auf das jeweilige Subsystem konzentrieren. Das kann den codeseitig zu berücksichtigenden Kontext erheblich reduzieren und umgekehrt die Wahrscheinlichkeit erhöhen, dass die KI brauchbaren Code in akzeptabler Zeit produziert.
Subsysteme in einer gemeinsamen Codebasis erfordern dann strenge Modularisierung und u. U. mehr Arbeit beim Prompting, damit der KI-Agent nicht aus Versehen links und rechts schaut. Mit separaten Codebasen für die Subsysteme geht man auf Nummer sicher, was aber wiederum viele andere Komplikationen mit sich bringen kann. Das ist Abwägungssache.
Eine sauber gegliederte Spezifikation hat den Vorteil, dass man einer KI auch klar abgegrenzte Teilaufgaben geben kann. Ist das Coden eines komplette Use Case ein zu dickes Brett, kann der Auftrag auch lauten: Implementiere Schritt 3.4.2 der Spezifikation. Es entsteht dann auch nicht so viel Code auf einmal und man tut sich leichter mit der Review. Man führt die KI sozusagen an ganz kurzer Leine. „Vise Coding“ statt „Vibe Coding“ nennt David Farago dieses Konzept, das sich mit Entwürfen der hier beschriebenen Detaillierung gut verbinden lässt [19].
Der statische Teil einer Spezifikation
Das oben verwendete Beispiel wurde bewusst so gewählt, dass es auch ohne Modellierung von Geschäftsobjekten einigermaßen verständlich ist. In der echten Praxis machen die Formulierungen der Abläufe aber intensiven Gebrauch von einem projektspezifischen Begriffsvokabular. Wenn der Leser einer Ablaufbeschreibung nicht zufällig alle darin auftauchenden Geschäftsobjekte und ihr Beziehungsgeflecht im Kopf hat, muss er sich das irgendwo anschauen können – und zwar nicht im Code, der nur Entwicklern zugänglich ist.
Ist die Formulierung „Wenn der Kunde einen Rabattcoupon eingelöst hat …“ überhaupt valide? Kann man irgendwo sehen, was ein Kunde und was ein Rabattcoupon ist und wie die Beziehung zwischen beiden aussieht? Vielleicht besteht die nur indirekt über den Umweg der Artikel einer Bestellung, und man sollte den Ablauf präziser formulieren – für Mensch und KI. Wenn diese Dinge nicht einsehbar sind, ist die Ablaufbeschreibung womöglich nur Kauderwelsch.
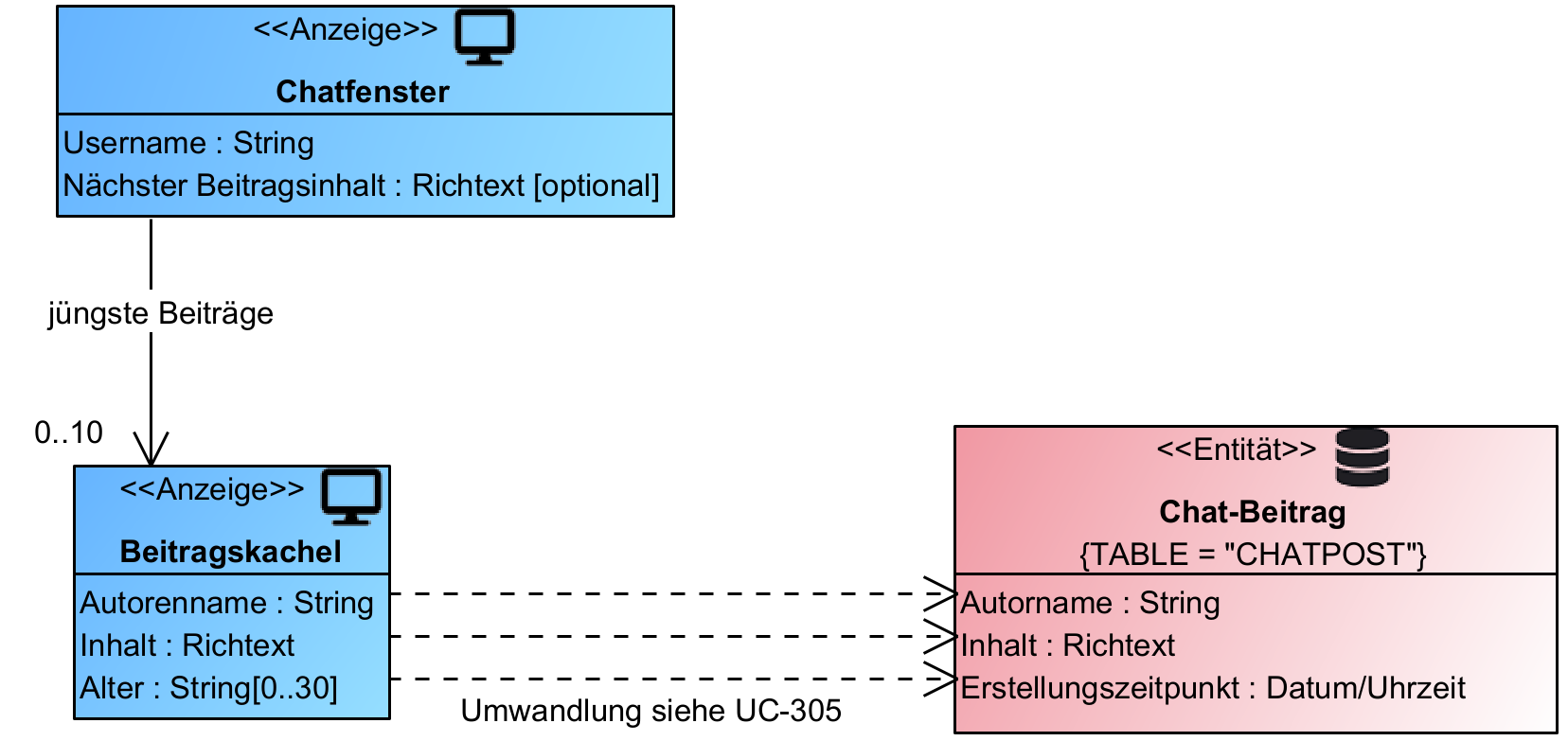
Abb. 6: Geschäftsobjekte als „umweltverträgliches“ UML-Klassendiagramm
Der Anspruch, dass die Entwürfe mit allen Beteiligten abgestimmt sind und sich permanent weiterentwickeln, gilt auch für die statischen Bestandteile. In den Projekten, in denen Specman und Word für die Ablaufbeschreibungen verwendet werden, kommen UML und im Besonderen Klassendiagramme zum Einsatz. Das ist trotz fehlender Änderungsverfolgung usw. ein akzeptabler Kompromiss, denn die Geschäftsobjekte ändern sich weniger häufig und enthalten auch nicht so viele Details wie die Abläufe. In Abbildung 6 ist das beispielhaft für die Geschäftsobjekte des Chatsystems dargestellt, auf die sich die Anforderung mit der Altersdarstellung bezieht. Allerdings sollte es schon „echtes“ UML sein und nicht nur gemalte Diagramme in DrawIO oder Visio. Der Hauptgrund ist die Unterscheidung zwischen dem Modell einerseits und dem Diagramm als eingeschränkte Sicht auf das Modell andererseits.
In größeren Softwaresystemen ist es wenig hilfreich, ein Riesentapetendiagramm mit allen Geschäftsobjekten darauf herzustellen. Sinnvoll und naheliegend ist eher, dass man Use-Case-bezogene Diagramme herstellt, die den Ablaufspezifikationen der Use Cases beigestellt werden (Abb. 3). Zentrale Geschäftsobjekte tauchen dann in diversen Diagrammen auf, sollen aber natürlich nur einmalig modelliert werden, sofern hier nicht nach dem Prinzip der Bounded Contexts bewusst Redundanzen erwünscht sind [20]. Diese Trennung von Modell und Diagramm ist eine wichtige Eigenschaft professioneller UML-Tools wie z. B. Enterprise Architect oder Visual Paradigm.
Hinzu kommt in diesen Tools die Möglichkeit des Aufbaus sogenannter UML-Profile, die u. a. einen Kanon projektspezifischer Stereotype und zugehöriger Tagged Values bereitstellen. Stereotype sind eine Ausdrucksform querschnittlicher Konzepte, über die sich damit verbundene Muster im Code adressieren lassen. Ein KI-Assistent kann über die Stereotype also auf die richtigen Patterns zur Codegenerierung hingewiesen werden, wie Abbildung 6 verdeutlicht. Aus einer View-Klasse sind völlig andere Dinge zu generieren als aus einer Entity-Klasse, wobei Letztere noch mit einem Tagged Value für den Tabellennamen angereichert ist. Mit einem guten Farbschema, unterstützenden Icons und möglichst fachlicher Terminologie lassen sich auch für die Anforderungsseite ansprechende Diagramme herstellen.
Use-Case-bezogene Diagramme haben übrigens den Nebeneffekt eines geschenkten Dependency-Trackings. Ändert man für einen Use Case etwas an der Struktur eines zentralen Geschäftsobjekts, lässt sich im Tool feststellen, in welchen Diagrammen und damit in welchen anderen Use Cases das Objekt eine Rolle spielt und wo man mögliche Auswirkungen prüfen muss.
Alle professionellen UML-Tools bieten Exporte in maschinenlesbare Formate an, z. B. XMI. Damit ist sichergestellt, dass auch KI die Modelle leicht versteht. Noch einfacher ist es mit Tools, die selbst auf Plaintext arbeiten und die grafischen Darstellungen generieren. Weit verbreitet ist z. B. PlantUML [21]. Leider ist hier die Trennung Modell/Diagramm nicht gegeben, was den Einsatz für größere Softwaresysteme erschwert.
Es ist auch die Frage, ob man mit der Optik generierter Diagramme klarkommt. Einer agentischen Codegenerierung ist Optik egal, solange die modellierten Strukturen präzise sind, aber wie bei den Abläufen sind die Adressaten für die Diagramme auch die Fachanforderer. Sinnvolle Platzierung nach fachlichen Gesichtspunkten, saubere Linienführung und Aufgeräumtheit sind hilfreich für das Verständnis. Auch bei den statischen Modellbestandteilen kann man sich nicht immer aussuchen, wie kompliziert die darzustellenden Zusammenhänge sind. Wo immer es geht, hält man die Dinge klein, etwa nach der C4-Methode [22] oder nach den Gestaltungskonzepten von Jacqui Read [23]. Wenn das aber einmal nicht geht, ist es ärgerlich, wenn die Einflussmöglichkeiten auf das Layout beschränkt sind. Man denke an die Analogie zur Bauzeichnung: Detailreichtum und Lesbarkeit sollten kein Widerspruch sein.
Spezifikation einführen
Wenn man Spezifikationen in einem Projekt einführen will, dann fängt man am besten klein an. Ähnlich wie bei der Einführung von Testautomatisierung muss man dabei gegen das kontraintuitive Gefühl ankämpfen, mehr Dinge herzustellen zu müssen, um am Ende effizienter zu sein. Dass ein Drittel mehr Code für Unit-Tests schlussendlich spart statt kostet, musste man auch erst mal verinnerlichen. Erfahrungsgemäß tun sich Youngster damit leichter als alte Hasen.
Für den Einstieg entwirft man z. B. für die nächste etwas kompliziertere Aufgabe einfach mal vorher ein Aktogramm, um darauf basierend zu coden. Das muss nicht gleich perfekt und mit den Anforderern abgestimmt sein. Erst mal für sich selbst üben, um z. B. das Arbeiten im Flow anzustreben [24]. Ist der Feinentwurf nämlich vorweg entstanden, kann man sich hinterher unterbrechungsarm dem Coden widmen. Wenn mir das als Mensch gelingt, sind die Voraussetzungen für KI-Unterstützung gut.
Ein anderer bewährter Einstieg ist z. B. eine fragmentarische Beschreibung aus einem Reverse Engineering von Code, dessen unklare Funktionsweise wiederholt Ärger macht – übrigens auch eine Tätigkeit, bei der KI helfen kann. Der Effekt, dass alle Beteiligten plötzlich in natürlicher Sprache nachlesen können, wie das System an der fraglichen Stelle arbeitet, ist ein Augenöffner.
Vollständig in das Software-Engineering integrierte Spezifikationen nehmen in der oben dargestellten Form etwa ein Fünftel der Zeit ein, die das Implementieren benötigt. Das ist ein grober Erfahrungswert über 15 Jahre und diverse Projekte in verschiedenen Firmen hinweg. Dabei entsteht ein Shift-Left-Effekt [25], der die Aufwände in teureren Folgephasen des Entwicklungsprozesses deutlicher reduziert als neuer Aufwand in den frühen Phasen entsteht. Es braucht nur seine Zeit, bis es einem in die DNA übergeht.
Immer erst die Spezifikation aktualisieren, bevor man an den Code geht. Das muss sich so natürlich und indiskutabel anfühlen wie: Immer erst den Gurt anlegen, bevor man losfährt. Dann funktioniert es.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Fazit
KI-Unterstützung in der Softwareentwicklung hat, der besonderen Natur von LLMs wegen, ihre Tücken. Wo sie einerseits verspricht, das Coding zu beschleunigen, deckt sie andererseits gnadenlos auf, wo in Design und Code bisher „herumgesumpft“ wurde. Detaillierte, abgestimmte Spezifikationen und saubere Codestrukturen sind die Leitplanken, die einer KI den Weg weisen, um sie auch in anspruchsvollen Projekten für mehr als eine bessere Internetsuche zu verwenden. Insofern ist der Zeitpunkt gerade günstig, sich auf solide Entwurfsarbeit zu besinnen. Neue Spezifikationstools sind am Start und die Investitionsbereitschaft für alles rund um KI-Unterstützung ist hoch. Das Prinzip „Design before Implementation“ hat sich über mindestens 30 Jahre als zeitlos erwiesen und es ist unwahrscheinlich, dass KI das ändert, wenn selbst Vibe Coder es erkennen.
Ist dieser Artikel eigentlich mit KI-Unterstützung entstanden? In der Tat ist er das, und zwar genau nach den Prinzipien, die hier für Software beschrieben sind. Der Entwurf des Artikels ist up-front aus menschlicher Arbeit und vielen, vielen Diskussionen entstanden. Aber wenn es um die „Implementierung“ ging, konnte die KI dabei helfen z. B. einen angefangenen Satz sauber formuliert zu Ende zu bringen.
Author
🔍 Frequently Asked Questions (FAQ)
1. Was bedeutet „Design before Implementation“ in der Softwareentwicklung?
„Design before Implementation“ beschreibt den Ansatz, fachliche Abläufe und Systemverhalten zunächst präzise zu spezifizieren, bevor Code geschrieben wird. Ziel ist es, Missverständnisse zu vermeiden und eine belastbare Grundlage für Entwicklung, Tests und spätere Änderungen zu schaffen.
2. Warum werden Spezifikationen durch KI wichtiger statt überflüssig?
Große Sprachmodelle können Code generieren, benötigen dafür jedoch klare und strukturierte Vorgaben. Je komplexer ein Softwaresystem ist, desto wichtiger werden präzise Spezifikationen, damit KI-Systeme konsistente und fachlich korrekte Ergebnisse liefern.
3. Was ist Spec-driven Development?
Spec-driven Development ist ein Entwicklungsansatz, bei dem Spezifikationen die zentrale Grundlage für Implementierung, Tests und Wartung bilden. Anstatt direkt aus Anforderungen zu programmieren, werden Abläufe und Geschäftsregeln zunächst in strukturierter Form beschrieben und anschließend umgesetzt.
4. Welche Vorteile bieten detaillierte Spezifikationen für Enterprise-AI-Projekte?
Detaillierte Spezifikationen schaffen ein gemeinsames Verständnis zwischen Fachbereichen, Entwicklern und Testern. Sie reduzieren Fehlinterpretationen, ermöglichen frühzeitiges Feedback und liefern sowohl Menschen als auch KI-Systemen eine zuverlässige Basis für die Implementierung.
5. Was sind Aktogramme und wofür werden sie eingesetzt?
Aktogramme sind eine Weiterentwicklung klassischer Struktogramme für die Spezifikation von Softwareabläufen. Sie verbinden gute Lesbarkeit für Menschen mit einer klaren Struktur, die auch von KI-Systemen maschinell ausgewertet werden kann.
6. Kann KI selbst Softwarearchitektur und Spezifikationen erstellen?
KI kann bei der Analyse, Validierung und Überarbeitung von Entwürfen unterstützen. Die eigentliche Entwurfsarbeit erfordert jedoch fachliches Verständnis, analytisches Denken und die Abstimmung zwischen Stakeholdern. Deshalb bleiben Menschen für Architekturentscheidungen und Spezifikationen zentral.




