
Seien wir ehrlich: Auch wenn uns Java in den vergangenen 20 Jahren sowohl im Frontend als auch im Backend gute Dienste geleistet hat, hätte wohl kaum jemand sein Erspartes darauf gewettet, dass Java uns auch in die Wunderwelt der Cloud begleiten könnte. Zu groß die augenscheinliche Diskrepanz zwischen den Anforderungen der Cloud und den Möglichkeiten von Java.
Ein Zitat von Filippe Costa Spolti, Senior Software Engineer bei Red Hat, bringt dies sehr schön auf den Punkt: „I started thinking about my application’s performance – in this case, the bootstrap time – and asked myself whether I was happy with the actual time my application took to start up. The answer was no. And, nowadays, this is one of the most important metrics to be considered when working with microservices, mainly on a serverless architecture.“ [1]
Während in der Cloud kleine, schnelle und flexible Anwendungen gefragt sind, kommt Java eher schwerfällig daher – so der allgemeine Konsens.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Mit Quarkus (aktuell in der Version 2.75) ist 2019 allerdings ein für Container optimierter Lösungsansatz gelungen, der dieses Vorurteil zunichtemachen will. „Supersonic/Subatomic/Java“, so der provokante Disclaimer auf der Homepage von Quarkus.io [2]. Quarkus wurde von Beginn an mit der Absicht konzipiert, sich als „Kubernetes-native Full-Stack Java Framework für JVMs und native Kompilierung“ optimal in die Welt von Microservices, Cloud und Co. einzubetten.
Aber immer der Reihe nach. Bevor wir uns mit der Lösung beschäftigen, gilt es zunächst einmal, das Problem zu verstehen. Was ist in der Cloud eigentlich so anders als im gewohnten Enterprise-Computing-Umfeld? Und warum bringt dies erhebliche Probleme für unser gutes altes Enterprise Java mit sich?
Bereit für die Cloud?
Eine Anwendung in die Cloud zu verlagern, kann – wenn man es richtig angeht – etliche Vorteile mit sich bringen. Schnelle Provisionierung neuer Ressourcen, bedarfsgerechte und automatische Skalierung von Services sowie erhöhte Kosteneffizienz dank Pay-per-Use-Modell, um nur einige zu nennen.
Im Gegenzug verlangen Cloudumgebungen deutlich mehr Flexibilität von den in ihnen laufenden Anwendungen als wir es aus dem klassischen Enterprise Computing gewohnt sind. Natürlich ließe sich eine monolithische Anwendung eins zu eins in die Cloud verfrachten (aka lift & shift). Das würde allerdings fast keinen Mehrwert bringen. Um die Vorteile der Cloud voll auszuspielen, bedarf es einer an die Cloudumgebung adaptierten Anwendungsarchitektur, welche die Software als Service versteht und entsprechend klein, schnell und flexibel ist. Klein im Sinne von niedrigem Speicherbedarf, schnell im Sinne von schnellen Start-up-Zeiten und flexibel im Sinne von modular aufgebaut (für einen tieferen Einblick in die Anforderungen an eine Cloud-native Anwendung verweise ich auf die „Twelve-Factor-App“-Methode [3]). Nur wenn diese Voraussetzungen gegeben sind, lässt sich eine Anwendung bzw. lassen sich einzelne Module/Services der Anwendung bei Bedarf schnell und effizient hoch und runter skalieren. Ein wichtiger Aspekt, der in der Cloud bares Geld wert ist – und das nicht nur im übertragenen Sinne!
Als Laufzeitumgebung für Anwendungen in der Cloud hat sich in den letzten Jahren Kubernetes in Kombination mit Docker-Containern als eine Art De-facto-Standard etabliert. Abbildung 1 zeigt eine typische automatisch skalierbare Cloudumgebung auf Basis eines Kubernetes Clusters. Das ist die Welt moderner Softwareanwendungen in den Jahren 2020plus.
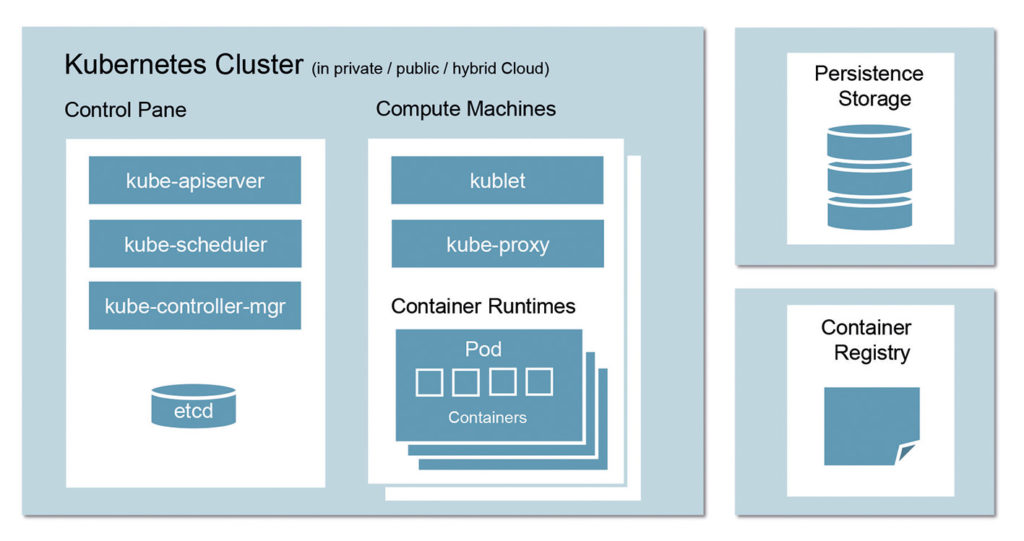
Abb. 1: Kubernetes Cluster

Enterprise Java und die Cloud
Schaut man sich die Anforderungen an eine für die Cloud optimierte Anwendung an, scheint eine auf Enterprise Java basierende Anwendung genau das Gegenteil davon zu sein. Warum ist das so?
Der Enterprise Java Standard Java EE (aka Jakarta EE) wurde ursprünglich konzipiert, um unternehmenskritische Anwendungen dauerhaft in einer stabilen Umgebung – dem Java EE Application Server – ablaufen zu lassen. Dauerhaft bedeutet hier, dass eine einmal deployte Anwendung über Wochen oder Monate hinweg ohne jegliche Änderungen läuft.
Dieses Konzept der stabilen und sehr langlebigen Laufzeitumgebung hat seinen Preis. Basiert eine Anwendung auf dem Enterprise-Java-Standard – egal ob Full Profile oder das etwas schlankere Web Profile – sind zur Laufzeit schnell etliche 100 MB Memory Footprint erreicht. Den Großteil davon macht dabei die Server Runtime aus. Aber auch, wenn nur diejenigen Bestandteile des Servers verwendet werden, die tatsächlich für die Anwendung notwendig sind, und daraus zum Beispiel eine Self-contained Application in Form eines Runnable JAR gebaut wird, ist eine Anwendungsgröße deutlich unter 100 MB nicht wirklich realistisch. Gleiches gilt im Übrigen auch für die alternative Verwendung des Spring Frameworks. Ein solches Konstrukt ist deutlich zu groß für eine automatische Skalierung im Sekundenbereich – egal, ob dabei Kubernetes und Container zum Einsatz kommen oder nicht.
Aber der Speicherbedarf stellt nicht einmal das größte Problem von Enterprise-Java-Anwendungen in der Cloud dar. Fast noch stärker ins Gewicht fällt die lange Start-up-Zeit. Sie macht es nahezu unmöglich, kontinuierlich, zeitnah und schnell neue Instanzen einer Anwendung bzw. einzelner Services zu deployen und zu starten, um so zum Beispiel on the fly erhöhte Last abzufangen. Serverless-Szenarien, bei denen Start-up-Zeiten im Bereich von Millisekunden erwartet werden, verbieten sich per Definition.
Der Grund für die hohen Start-up-Zeiten ist leicht erklärt. Enterprise Java hat in den letzten zehn Jahren den Fokus verstärkt auf Aspekte wie „Ease of Development“ und „Convention over Code“ gelegt. Diese beinhalten u. a. die intensive Verwendung von Annotationen und anderen Metadaten, die erst während des Deployments bzw. beim Start-up der Anwendung gescannt und aufgelöst werden. Über diesen Mechanismus wird zum Beispiel zum Start einer Enterprise Application sichergestellt, dass es für jeden CDI Injection Point genau eine Bean mit passendem Typ, Qualifier und Scope gibt, die zur Laufzeit eingebunden werden kann. Gibt es dagegen keine passende Bean bzw. mehr als eine, kommt es beim Starten der Anwendung zu einer entsprechenden Exception.
Natürlich werden in diesem Moment nicht wirklich alle abhängigen Klassen erzeugt und initialisiert. Das würde tatsächlich noch einmal deutlich länger dauern und entsprechend mehr Speicherplatz benötigen. Stattdessen werden zunächst nur Proxies als Stellvertreter generiert.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Dieser Ablauf des Metadata Processings während des Deployments bringt zwei große Nachteile mit sich. Zum einen kosten das Scannen der Metadaten und das Auflösen der Abhängigkeiten Zeit. Zum anderen werden für diesen Prozess zusätzliche Klassen zum Aufbau und zur Verwaltung der Abhängigkeiten benötigt, die rein gar nicht nichts mit der eigentlichen Anwendung zu tun haben. Abbildung 2 zeigt das Metadata Processing während des Deployments einer Jakarta-EE-Anwendung.
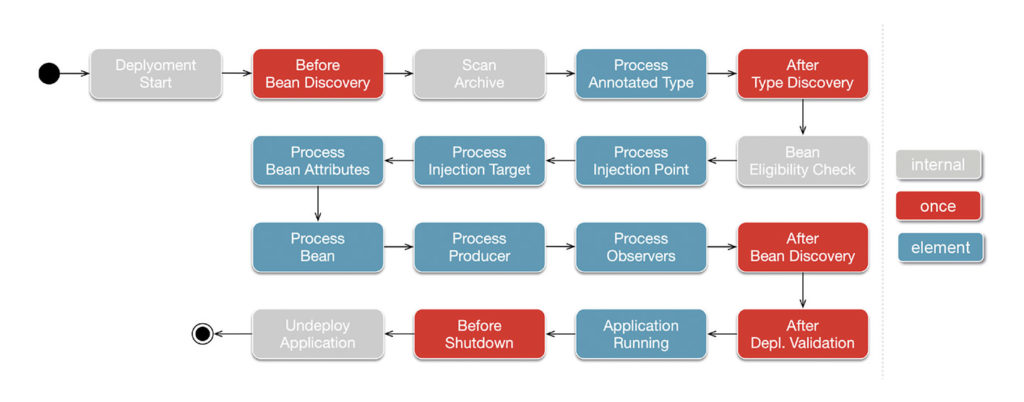
Abb. 2: Metadata Processing
Zusammenfassend kann man sagen, dass Enterprise Java im Hinblick auf die Cloud zwei große Probleme aufweist. Zum einen sind die auf Jakarta EE basierenden Anwendungen bzw. Services in der Regel einfach zu groß. Zum anderen starten sie zu langsam. Da helfen auch gut gemeinte Ansätze zur Minimierung des Server-Overheads, wie zum Beispiel das Jakarta MicroProfile, nur bedingt weiter. Denn das wesentliche Problem, das Auflösen der Abhängigkeiten zum Zeitpunkt des Deployments, bleibt auch hier bestehen.
Quarkus bringt nun einige Optimierungen mit, die ihren Hebel zielgerichtet an den beschriebenen Problemstellen ansetzen.
Build-Time-Optimierung
Die erste Optimierung basiert auf der (berechtigten) Annahme, dass ein Großteil der durch Java EE ermöglichten Dynamik zur Laufzeit in typischen Service-basierten Szenarien nicht wirklich benötigt wird und sich die damit verbundene Auflösung der Abhängigkeiten daher problemlos von der Deployment- bzw. Start-up-Phase in die Compile- und Build-Phase verlagern lässt. Denn wurde eine Anwendung erst einmal als Container Image zur Verfügung gestellt, ändert sich dieses Image in der Regel nicht mehr.
Durch einen entsprechenden zusätzlichen Schritt in der Build Pipeline (Abb. 3), in dessen Verlauf etliche dynamische Konstrukte aufgelöst und durch statische Pendants ersetzt werden, schafft es Quarkus, die Größe der Anwendung – je nach verwendeten Libraries – etwa um die Hälfte zu minimieren. Durch den Wegfall des Metadata Processings zum Start der Anwendung verkürzt sich auch die Start-up-Zeit deutlich. Verstärkt wird dieser Effekt noch einmal durch die Verwendung des in Version 1.5 eingeführte Fast-Jar Classloaders [4]. Dieser persistiert zur Build-Zeit die Lokationen aller Klassen und Ressourcen, sodass sie zum Start-up nur noch eingelesen werden müssen.
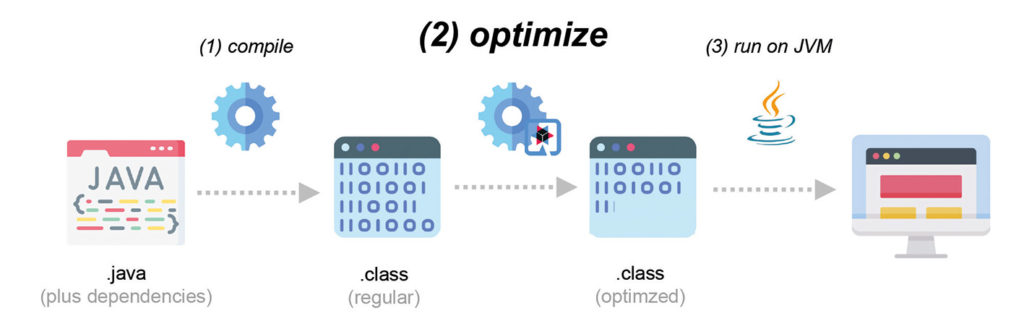
Abb. 3: Build-time-Optimierung
Möchte man wissen, welche Optimierungen von Quarkus in diesem Schritt durchgeführt wurden, kann dazu im Development Mode (dazu später mehr) ein eigens dafür generierter Debug Endpoint aufgerufen werden: http://localhost:8080/q/arc/[beans|observers|removed-beans]
Supersonic via Ahead-of-time Compilation
Auch wenn uns diese Optimierung schon eine deutliche Verminderung der Anwendungsgröße und einen entsprechenden Boost der Start-up-Zeit beschert, kann von „Supersonic“ noch keineswegs die Rede sein. Szenarien, in denen eine Anwendung bzw. ihre Services regelmäßig neu deployt oder bei Bedarf automatisch skaliert werden sollen, sind zwar durchaus denkbar. Serverless-Szenarien, in denen Start-up-Zeiten im Bereich einiger weniger Millisekunden benötigt werden, dagegen nach wie vor eher nicht.
Aber auch hier hat Quarkus eine Lösung im Gepäck: Ahead-of-time Compilation. Die Idee ist, den Build-Prozess um einen weiteren Optimierungsschritt zu erweitern, im Zuge dessen unter Zuhilfenahme von GraalVM ein native Executable erzeugt wird (Abb. 4). Der kompilierte Source Code wird also zur Laufzeit nicht mehr interpretiert, sondern kann direkt als nativer Maschinencode ausgeführt werden. Dies ist selbst gegenüber stark optimiertem Bytecode unter Verwendung von Just-in-time Compilern ein Quantensprung. Die Größe der Anwendung verringert sich, je nach Anwendung, um einen Faktor bis zu zehn gegenüber der ursprünglichen Variante. Die Start-up-Zeit sinkt in den Bereich von Millisekunden. Das ist Supersonic!
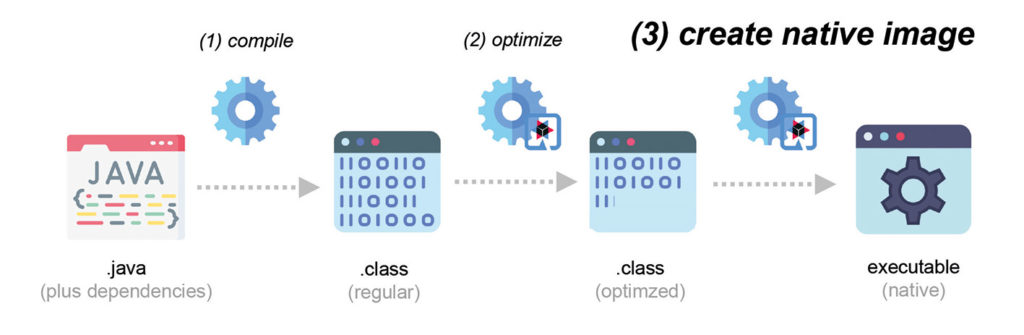
Abb. 4: Ahead-of-time-native-image-Generierung
Das Erzeugen eines native Executable für das eigene OS ist dank Maven-Plug-in denkbar einfach [5].
./mvnw package -Dnative
Aber Achtung: Zum einen dauert der zugehörige Build-Prozess relativ lang und ist somit nicht für ein regelmäßiges Build in der eigenen Entwicklungsumgebung geeignet. Zum anderen – und das ist deutlich schwerwiegender – möchte man am Ende ja nicht unbedingt ein Executable, das auf der eigenen Maschine läuft, sondern vielmehr eines für die produktive Umgebung. Und dies ist, wie wir ganz am Anfang des Artikels gelernt haben, ein von Kubernetes gemanagter Docker-Container auf 64-Bit-Linux-Basis.
Möchte man ein Runnable für Linux erzeugen, und zwar ohne dafür extra GraalVM auf dem eigenen Rechner oder der CI/CD-Infrastruktur zu installieren, kann auf folgendes Maven Command zurückgegriffen werden:
./mvnw package -Dnative -Dquarkus.native.container-build=true
Mit Hilfe der Direktive quarkus.native.container-build=true findet der Build-Prozess innerhalb eines temporär erzeugten Containers statt.
Noch einen Schritt weiter geht folgendes Maven Command. Mit seiner Hilfe wird nicht nur ein Executable für eine zukünftige Containerumgebung erstellt, sondern der Container gleich mit:
./mvnw package -Pnative -Dquarkus.native.container-build=true
-Dquarkus.container-image.build=true
WORA vs. WORP
Mit Hilfe von Build-time Optimization und Ahead-of-time Compilation gelingt es Quarkus, Enterprise Java auch in Zeiten von Microservices, Serverless, Cloud und Co. konkurrenzfähig zu machen. Dank native Executables werden sowohl der Ressourcenverbrauch als auch die Start-up-Zeiten deutlich minimiert.
Aber … nutzen wir nicht gerade deshalb Java, um unabhängig von dem zugrunde liegenden Betriebssystem zu sein? Gilt plötzlich der 1995 von Sun ins Leben gerufene Slogan „Write once, run anywhere“ nicht mehr? In der Tat, in Zeiten von Containern als Ablaufumgebung ist das ehemalige Highlight der Plattformunabhängigkeit nahezu obsolet geworden – zumindest, wenn es um Enterprise Java geht. An die Stelle von „anywhere“ rückt „predictable“ im Sinne einer vorhersehbaren Ablaufumgebung, da wir auf Basis des Containers überall die gleiche Zielumgebung schaffen können. WORP ist das neue WORA!
Und das funktioniert wirklich?
Ja und nein. Es ist leicht vorstellbar, dass die gezeigten Optimierungen auch einige Limitierungen mit sich bringen. Diese ergeben sich zum einen durch die Limitierungen der GraalVM bzw. SubstrateVM [6], zu denen u. a. Dynamic Class Loading, Native VM Interfaces, Reflection und Dynamic Proxies gehören. Zum anderen kommen weitere Limitierungen durch die Verwendung der Quarkus-eigenen Dependency-Injection-Lösung (ArC DI) hinzu, die sich zwar anfühlt wie CDI 2.x, am Ende aber nur ein Subset der Features darstellt [7]. So werden z. B. @ConversationScoped und @Interceptors nicht unterstützt. Gleiches gilt für CDI Portable Extensions.
Die genannten Limitierungen spielen in der Praxis allerdings kaum eine Rolle bzw. können in der Regel relativ einfach umgangen werden. Die Grundidee von Quarkus ist, dass 80 Prozent aller Anwendungsfälle aus dem Enterprise-Computing-Umfeld out of the box funktionieren sollten. Für die restlichen 20 Prozent ist ein wenig Handarbeit vonnöten.
So bringt Quarkus von Haus aus Unterstützung für die wichtigsten (De-facto-)Enterprise-Standards und Libraries mit. Hierzu gehören u. a. MicroProfile, Netty, Vert.x, Apache Carmel, Elastic Serach, Flyway, Neo4j, Kafka, ActiveMQ, Kubernetes und AWS Lambda.
Getreu dem Motto „was nicht passt, wird passend gemacht“ bietet Quarkus zusätzlich ein sehr mächtiges Extension Framework [8], mit dessen Hilfe auch diejenigen Libraries eingebunden werden können, die aufgrund der aufgezeigten Limitierungen out of the box nicht mit Quarkus funktionieren würden. Abbildung 5 zeigt noch einmal den gesamten Quarkus-Stack im Überblick.
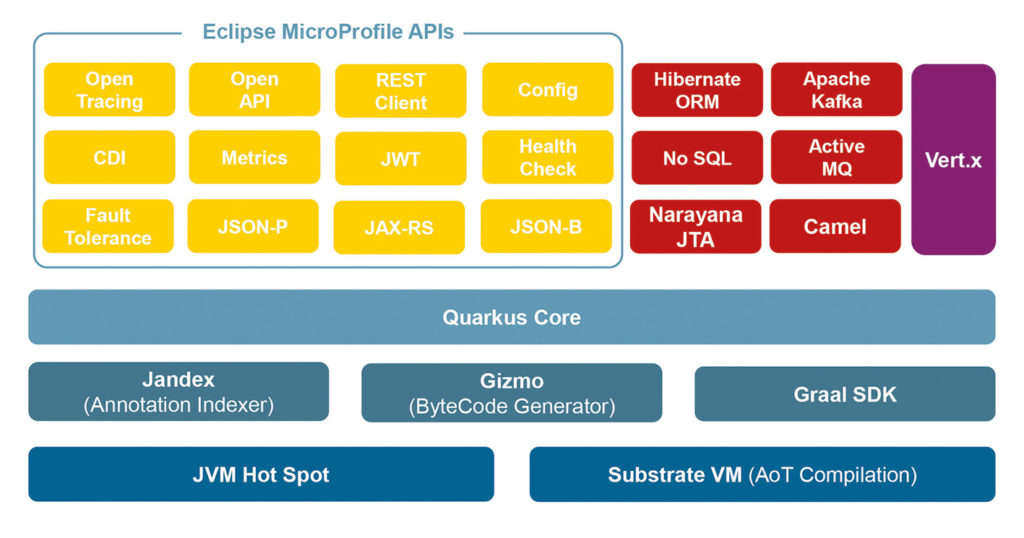
Abb. 5: Der Quarkus-Stack
Fazit
Quarkus ist mit dem Ziel angetreten, sich als „Kubernetes-native Full-Stack Java Framework für JVMs und native Kompilierung“ optimal in die Welt von Microservices, Serverless, Cloud und Co. einzubetten und hebt Enterprise Java dabei auf die nächste Stufe.
Schmale Build-Artefakte führen zu sehr schlanken Container Images. Schnelle Bootzeiten erlauben ein sofortiges Scale-up. Und dank geringem RSS-Speicher (Resident Set Size) können mehr Container bei gleichem RAM instanziiert werden.
Erreicht wird dies durch Build Time Optimization und Ahead-of-time Compilation. Etwaige Limitierungen, die diese beiden Ansätze mit sich bringen, können durch einen eigenen Extension-Mechanismus mit ein klein wenig Handarbeit aus dem Weg geräumt werden.
Damit die zusätzlichen Schritte im Build-Prozess sich nicht negativ auf die Turnaround-Zeiten innerhalb der Entwicklung auswirken, bietet Quarkus einen eigenen Development Mode mit einer Art Hot Deployment. Kurz und gut: Quarkus ist ein Framework, das wirklich Spaß macht!
Links & Literatur
[4] https://developers.redhat.com/blog/2021/04/08/build-even-faster-quarkus-applications-with-fast-jar#
[5] https://quarkus.io/guides/building-native-image
[6] https://github.com/oracle/graal/blob/master/substratevm/Limitations.md




