
Um sinnvoll beurteilen zu können, ob Jakarta EE (ehemals Java EE, ehemals J2EE – kurz: JEE) aktuell noch (s)eine Daseinsberechtigung hat, gilt es zu verstehen, wie heutzutage eine typische Unternehmensanwendung und deren Ablaufumgebung aufgebaut sind.
Die Welt von Cloud-Native and Friends
Die Anwendung selbst kommt häufig modular, z. B. in Form von Self-contained Systems oder Microservices daher. Die Kommunikation zwischen den einzelnen Teilen der Anwendung erfolgt in der Regel asynchron über Events. Ziel dieses Architekturansatzes ist es, eine möglichst große Unabhängigkeit der einzelnen Services untereinander zu erreichen. Das gilt sowohl für die Entwicklung als auch für die Tests, das Deployment und den Betrieb.
Die Ablaufumgebung ist dann meist einer der etablierten Cloud-Provider oder alternativ eine Managementplattform, die ein Cloud-ähnliches Erlebnis im eigenen Rechenzentrum ermöglicht (z. B. Red Hat OpenShift).
Die wesentlichen Key-Player, die es in einem solchen Set-up zu unterstützen gilt, sind die De-facto-Standards Docker-Container und die mittlerweile bei der Cloud Native Computing Foundation (kurz: CNCF) beheimatete Containermanagementplattform Kubernetes, die zur automatisierten Bereitstellung, Skalierung und Verwaltung der containerisierten Anwendung genutzt wird.
So weit, so gut. Aber was genau bedeutet das nun für den Aufbau einer Anwendung? Und wie hängt das mit unserer Ausgangsfrage „Ist JEE noch zeitgemäß?“ zusammen?
In einer Welt von stark verteilten Anwendungen, deren einzelne Bestandteile in der Cloud in Form von Managed Containern hochgradig automatisiert bereitgestellt und verwaltet werden, gelten andere Regeln als noch vor Jahren im Umfeld monolithischer Anwendungen mit einem zentralen Application Server als Ablaufumgebung.
Die einzelnen Bestandteile der verteilten Anwendung sollten möglichst klein sein, um schlanke Container-Images zu ermöglichen. Die Start-up-Zeiten der Container sollten möglichst gering sein, um so bei Bedarf eine Skalierung in Echtzeit zu erlauben. Die Resident Set Size (kurz: RSS), also der vom Laufzeitprozess benötigte Speicher, sollte möglichst niedrig sein, um so bei gleichen Ressourcen mehr Container zu gewährleisten. Denn in der Cloud gilt nun einmal die goldene Regel „Je weniger Ressourcen, desto weniger Kosten“.
Zusammengefasst lässt sich also sagen, dass der Bedarf einer Cloud-Native-Anwendung bzw. ihrer Bestandteile wie folgt charakterisiert werden kann:
-
klein aka niedriger Speicherbedarf
-
schnell aka geringe Start-up Time
-
flexibel aka Modularisierung
Abbildung 1 zeigt eine typische Ablaufumgebung auf Basis eines Kubernetes-Clusters.
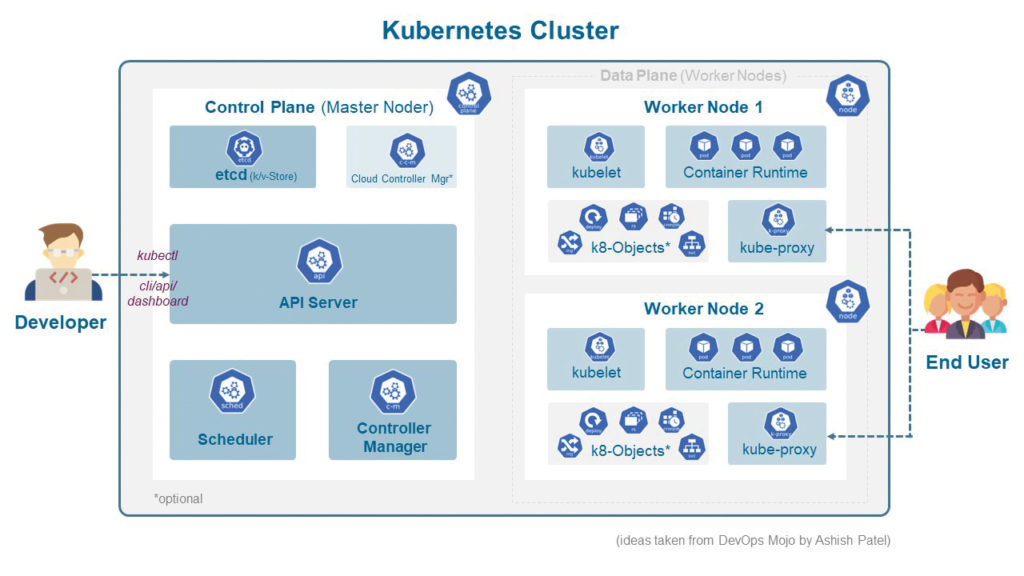
Abb. 1: Kubernetes-Cluster
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Die Welt von Jakarta EE
Klein, schnell und flexibel. Das sind nicht unbedingt die ersten Attribute, die einem einfallen, wenn man an den Java-Enterprise-Standard denkt. Das Gegenteil ist der Fall.
Anwendungen auf Basis von JEE sind eher groß. Das gilt insbesondere dann, wenn man den Application Server in die Betrachtung mit einbezieht. Die Start-up-Zeit einer JEE-Anwendung, also der Zeitraum vom Deployment innerhalb eines App-Servers bis zur Beantwortung des ersten Requests, ist in der Regel recht hoch. Und mit besonderer Flexibilität trumpft eine auf JEE basierende Anwendung auch nicht gerade auf. Zwar kann – Stand heute – zwischen zwei unterschiedlichen Varianten namens Full Profile („bitte einmal alles“) und Web Profile („bitte einmal fast alles“) gewählt werden, das erscheint aber in Hinblick auf die angestrebte Modularisierung eher wie eine Wahl zwischen Not und Elend.
Die Ausgangsbasis, um in der neuen Welt von Cloud-Native und Co. mitspielen zu dürfen, könnte also kaum ungünstiger sein. Warum also an JEE festhalten? Zumal mittlerweile etliche Java-basierte Frameworks – wie z. B. Spark, Micronaut, Helidon SE oder Meecrowave – existieren, die speziell für das oben beschriebene Microservices- und Cloud-Szenario entworfen wurden.
JEE wurde von Anfang an als Lösung für Enterprise Applications konzipiert. Entsprechend stabil sind die zugehörigen Laufzeitumgebungen. Die APIs sind nach mehr als zwanzig Jahren Evolution auf jeden Fall ausgereift. Auch wenn sie aufgrund von Abwärtskompatibilität noch so einige Altlasten mit sich herumschleppen. JEE ist ein sehr weit verbreiteter Standard. Entsprechend viel Wissen existiert in der Community. Apropos Standard: Durch die Vielzahl an JEE-Providern besteht keine Abhängigkeit zu einem speziellen Hersteller.
Bevor wir also all diese Vorteile über Bord werfen und uns nach proprietären Lösungen umschauen, kann es durchaus Sinn ergeben, zu überlegen, ob und wie wir JEE evtl. doch für stark verteilte Anwendungen in Cloud-Umgebungen nutzen können.
Schaut man sich einmal die JEE APIs im Detail an, so wird schnell deutlich, dass die reine Implementierung von Microservices dank JAX-RS, JSON-B, JSON-P und CDI denkbar einfach ist. Das Problem liegt also weniger in den Fähigkeiten der APIs als vielmehr in der Größe des resultierenden Artefakts und der damit zusammenhängenden Start-up-Zeit sowie der zugehörigen Laufzeitumgebung namens Application Server.
Der Herausforderung der Größe des Deployment-Artefakts versucht man durch das Konstrukt der Profile Herr zu werden. Die Idee hinter den Profilen ist, dass ein Subset an APIs genommen und zu einem Profile kombiniert werden kann. Dabei ist es durchaus erlaubt, das Profile um eigene APIs zu ergänzen, die nicht zwangsläufig auch in das Full Profile einfließen müssen. So soll verhindert werden, dass sich die JEE-Spezifikation unnötig aufbläht.
Für ein Profile wird in einer eigenen Spezifikation das Zusammenspiel der eingebundenen APIs definiert und so garantiert, dass diese optimal aufeinander abgestimmt sind. Stand heute – also Jakarta EE 9 – gibt es, wie bereits beschrieben, genau zwei Profiles, die leider beide recht groß und somit für unser Zielszenario „Microservices in der Cloud“ eher ungeeignet sind. Mit der kurz vor dem Release stehenden, neuen Spezifikation Jakarta EE 10 wird allerdings ein weiteres, deutlich minimalistischeres Profile namens Core Profile eingeführt werden, das es erlaubt, sehr kleine Artefakte zu erzeugen. Zu den APIs des Core Profiles gehören u. a. CDI 4.0 light, JSON-B 3.0, JSON-P 2.1, JAX-RS 3.1 – eine optimale Basis für die Umsetzung von Microservices!
Bleibt also noch die Herausforderung des Application Servers als zentrale Ablaufumgebung. Die JEE-Spezifikation ist ursprünglich für eine Welt angedacht, innerhalb derer in relativ großen Abständen monolithische Anwendungen in einer stabilen Laufzeitumgebung deployt werden. Oder anders formuliert: JEE ist aufgrund des Single-Runtime-Ansatzes weder für stark verteilte Anwendungen noch für feingranulare und hochfrequente Deployments konzipiert. Aber wo ein Wille ist, ist auch ein Weg.
JEE als Distributed Runtime(s)
JEE und das Konzept des zentralen Application Servers werden quasi synonym verwendet. Das dem nicht zwingend so sein muss, zeigt Arjan Tijms – aktives Mitglied der Jakarta Specification Group – in seinem Blogpost „You don’t need an application server to run Jakarta EE applications“ [1].
Denn wirft man einmal einen genaueren Blick in die JEE-Spezifikation, so steht dort nirgends geschrieben, dass es eine losgelöste Instanz eines Application Servers inkl. aller Implementierungen der spezifizierten APIs geben muss. Das Gegenteil ist der Fall. In Abschnitt 2.9 „Flexibility of Product Requirements“ der aktuellen Jakarta-EE-9-Spezifikation heißt es: „As long as the requirements in this specification are met, Jakarta EE Product Providers can partition the functionality however they see fit. A Jakarta EE product must be able to deploy application components that execute with the semantics described by this specification.“
Und in Abschnitt 2.12.2 heißt es weiterhin zur Rolle des Jakarta EE Product Providers: „A Jakarta EE Product Provider is the implementor and supplier of a Jakarta EE product that includes the component containers, Jakarta EE platform APIs, and other features defined in this specification. […] A Jakarta EE Product Provider must make available the Jakarta EE APIs to the application components through containers.“
In Konsequenz bedeutet das, dass es durchaus legitim ist, nur die Bestandteile des Servers zu nutzen, die für die innerhalb der eigenen Anwendung verwendeten JEE APIs notwendig sind. Weiterhin können diese Bestandteile des Servers durchaus auch im Rahmen des Build-Prozesses mit der Anwendung selbst zu einem Artefakt aka ueber.jar (oder hollow.jar plus app.war) gebündelt werden. Ein Trick, den sich etliche Jakarte EE Product Provider zunutze machen und neben der klassischen Application-Server-Variante auch Alternativen anbieten (Abb. 2). Details und Beispiele dazu finden sich in dem oben referenzierten Blogpost.
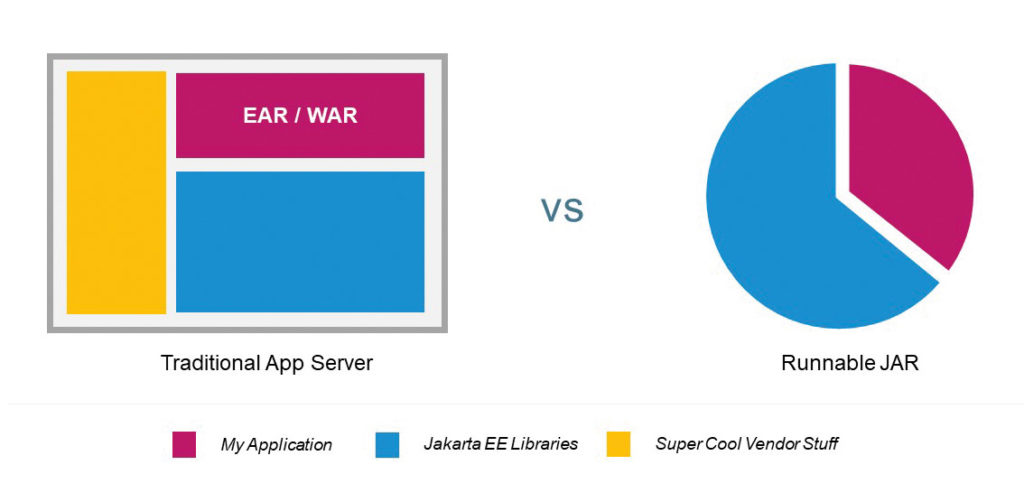
Abb. 2: Application Server vs. Runnable JAR

Was fehlt zum Glück?
Wie es scheint, haben wir soeben die beiden großen Herausforderungen, nämlich zu große Artefakte und die Notwendigkeit eines Application Servers, mit Hilfe des Core Profile und der Erzeugung eines ueber.jar im Build-Prozess elegant aus dem Weg geräumt. Haben wir es damit geschafft? Ist so eine verteilte Anwendungslandschaft auf Basis von Self-contained Services und/oder Microservices mit JEE realisierbar? Die Antwort ist jein.
Die einzelnen Services lassen sich problemlos implementieren und können auch getrennt voneinander gestartet, aktualisiert und skaliert werden. Das eigentliche Problem liegt aber weniger in der Implementierung und dem Betrieb der Services (Micro Architecture), sondern vielmehr in deren Zusammenspiel (Macro Architecture). Denn genau hier fehlt die zentrale Instanz des Application Servers. In einer verteilten Anwendungswelt treten Herausforderungen auf, die so in der JEE-Spezifikation nicht vorgesehen sind (Abb. 3).
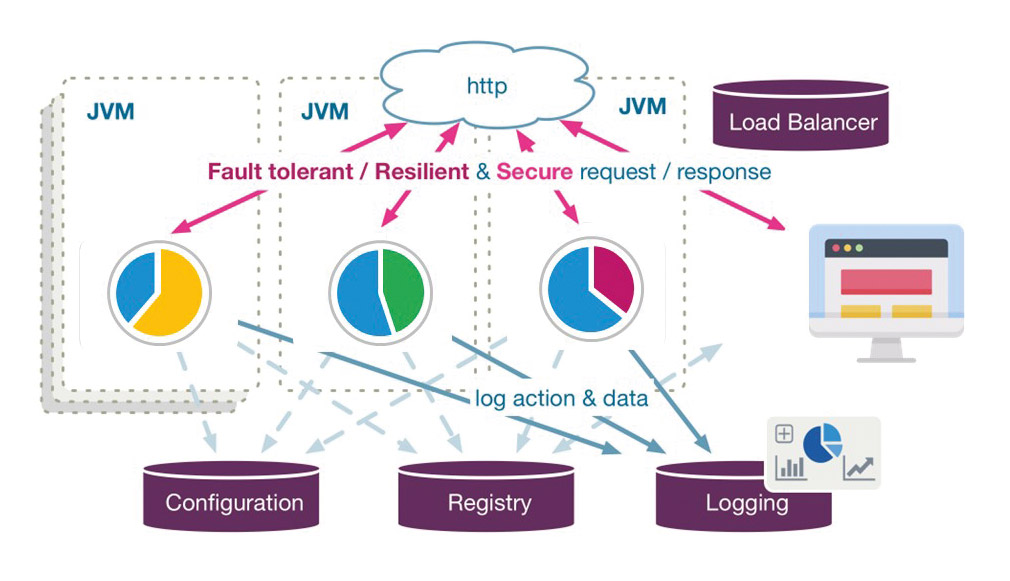
Abb. 3: Distributed Runtimes
Funktionalitäten, die sonst zentral innerhalb der Application-Server-Instanz abgehandelt wurden, müssen nun anders realisiert werden. Verteilt anfallende Informationen müssen zusammengesammelt und verdichtet werden. Kontexte, wie zum Beispiel der Security Context, müssen von einem Service zu einem anderen Service propagiert werden. Fehlersituationen und Ausfälle einzelner Services müssen erkannt und kompensiert werden.
Genau diese Herausforderungen hat bereits 2016 die Initiative MicroProfile.io [2] erkannt und einen entsprechenden API-Stack entworfen, der, ergänzt um einige wenige APIs aus JEE, das Implementieren und Managen verteilter Services auf Basis von Java ermöglicht (Abb. 4) [2].
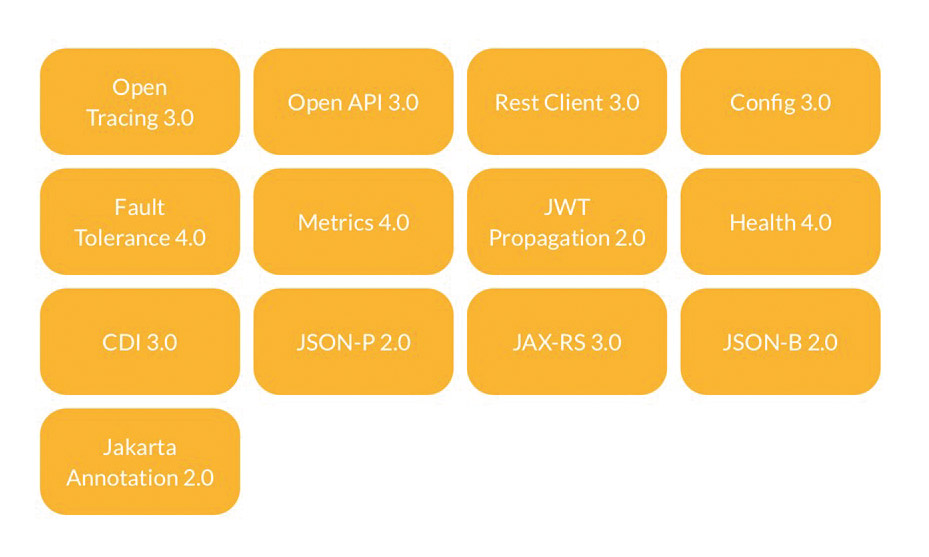
Abb. 4: MicroProfile APIs
Es fällt auf, dass die genutzten JEE APIs aus der MicroProfile-Spezifikation nahezu identisch mit denen des neu angedachten Core Profile sind. Das kommt nicht von ungefähr. Es ist vorgesehen, zukünftige Versionen der MicroProfile-Spezifikation dahingehend abzuändern, dass die jeweils aktuelle Version des Core Profile als Basis dient.
Ein subjektives Zwischenfazit
Dank Core Profiles freier Interpretation des Begriffs Application Server (Stichwort ueber.jar bzw. hollow.jar) und der bewusst auf die Herausforderungen verteilter Systeme zugeschnittenen APIs des Jakarta MicroProfile, besitzen wir eine sehr gute Grundlage für die Realisierung von Self-contained Services bzw. Microservices für die Zielplattform Cloud.
Die auf dieser Basis entstehenden Services liegen in der Regel bei einer Größe von unter 100 MB und sind nach ihrem Start in einigen Sekunden ansprechbar. Klein genug und schnell genug, um regelmäßige und losgelöste Deployments via Container in der Cloud durchzuführen.
Problematisch bleibt es allerdings nach wie vor immer dann, wenn die zu verarbeitende Workload sehr ungleichmäßig anfällt und daher neue Instanzen eines Service on the fly via Kubernetes Autoscaling bereitgestellt werden sollen. Denn für eine Nahezu-Echtzeitskalierung ist die Größe des zu deployenden Artefakts und damit auch die Start-up-Zeit nach wie vor ein wenig zu hoch.
Insbesondere der Extremfall der Serverless Functions, bei denen ein Service für die Beantwortung eines einzelnen Calls gestartet und danach wieder direkt beendet wird, schließt sich in diesem Szenario per Definition aus. Denn dort werden Start-up-Zeiten im Bereich von einigen wenige Millisekunden benötigt.
Ein Blick hinter die Kulissen
Auch wenn wir schon viel erreicht haben, scheinen wir nun also mit unseren JEE-Bordmitteln in Kombination mit Jakarta MicroProfile an unsere Grenzen zu stoßen. Dazu passt sehr gut ein Zitat von Filipe Spolti (Red Hat): „I started thinking about my application’s performance – in this case, the bootstrap time – and asked myself whether I was happy with the actual time my application took to start up. The answer was no. And, nowadays, this is one of the most important metrics to be considered when working with microservices, mainly on a serverless architecture.“
Aber warum schaffen wir es nicht, auch die Bootstrap Time noch weiter zu optimieren? Um das zu verstehen, hilft ein Blick auf das, was während der Boot-Phase einer JEE-Anwendung hinter den Kulissen passiert. Während des Starts einer JEE-Anwendung wird ein relativ komplexer Prozess zur Verarbeitung und Auflösung der Metadaten durchlaufen (Abb. 5).
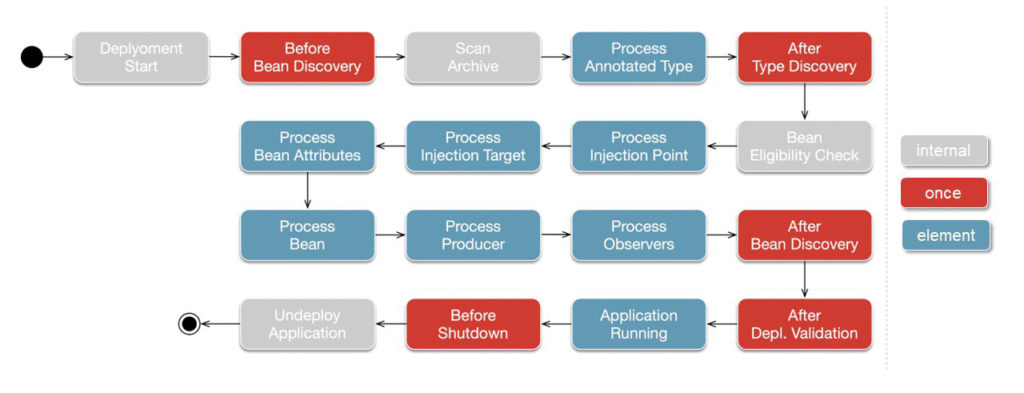
Abb. 5: Metadata Processing zum Start-up
Annotationen werden gescannt, Abhängigkeiten aufgelöst und auf Eindeutigkeit geprüft, Proxies erzeugt und vieles, vieles mehr. Das kostet nicht nur eine Menge kostbarer Zeit, sondern bedarf auch zusätzlicher Ressourcen, die zum größten Teil nur während der Bootstrap-Phase benötigt werden. Möchte man also kleiner und schneller werden, ist genau hier der Hebel, an dem es anzusetzen gilt.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Voodoo kommt ins Spiel
So schön es ist, dass das Processing der Metadaten und somit die Auflösung der Abhängigkeiten bereits zum Zeitpunkt des Deployments durchgeführt und somit verhindert wird, dass fehlerhafte Anwendungen überhaupt erst starten, so lästig ist es für das von uns angestrebte Wunschszenario. Den Prozess weiter nach hinten zu schieben, also auf einen Zeitpunkt, an dem die Anwendung bereits deployt ist und Requests entgegennehmen kann, ist wenig sinnvoll, da es so zu Fehlern in Produktion kommen kann. Was aber wäre, wenn man die ganzen Aufwände weiter nach vorne verlagert?
Ein sehr großer Anteil des Metadata Processing kann problemlos bereits zur Build Time erfolgen. Pseudodynamische Konstrukte können so durch statischen Code ersetzt werden. Das bringt nicht nur einen deutlichen Boost für die Start-up-Zeit, sondern verkleinert zusätzlich das resultierende Artefakt um einen erheblichen Faktor und erlaubt uns somit deutlich kleinere Container. Genau diesen Ansatz zur Build-Time-Optimierung verwendet das Quarkus-Framework [3]: „A Kubernetes Native Java stack tailored for OpenJDK HotSpot and GraalVM; crafted from the best of breed libraries and standards“.
Das Resultat kann sich sehen lassen. Allein durch die Verwendung der Build-Time-Optimierung sind die resultierenden Artefakte, also die Self-contained Services bzw. Microservices, nur etwa halb so groß wie ohne deren Verwendung. Noch interessanter ist aber, dass sich durch das Ersetzen von dynamischen durch statische Komponenten die Bootstrap-Zeit ca. um den Faktor fünf verbessert.
Das sind schon einmal sehr positive Aussichten. Aber Quarkus geht noch einen Schritt weiter. Als zusätzliche Optimierung kann optional aus dem via Build Time Optimization erzeugten plattformunabhängigenJava-Artefakt ein plattformabhängiges Runnable erzeugt werden. Ahead-of-Time-Compilation heißt hier das Zauberwort (Abb. 6).
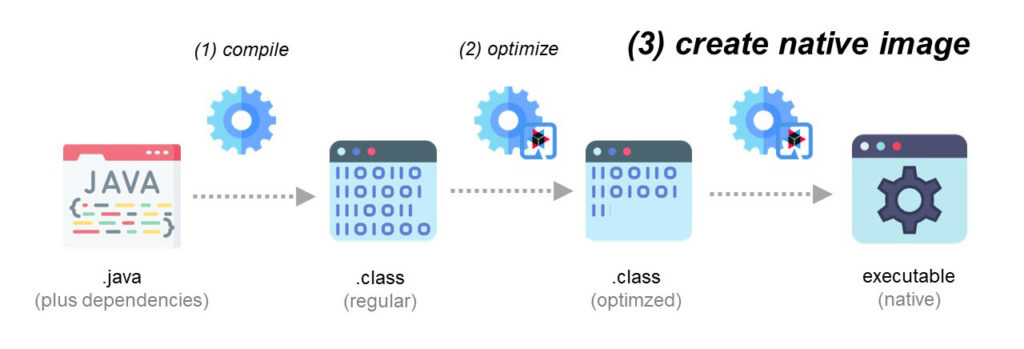
Abb. 6: Ahead-of-Time-Compilation
Dank AoT-Compilation schrumpft unser Artefakt ca. um Faktor zehn, und Start-up-Zeiten im Bereich von wenigen Millisekunden werden möglich. Unser Ziel scheint erreicht! Aber irgendwie klingt das zu schön, um wahr zu sein. Wo also bitte ist der Haken?
Zum einen bringt die Verwendung der beiden eben angesprochenen Optimierungen (Build Time Optimization und Ahead-of-Time Compilation) einige Restriktionen für die eigene Anwendung mit sich. Das betrifft insbesondere die direkte oder indirekte Verwendung von Reflection [4], aber zum Beispiel auch die leicht eingeschränkte Funktionalität durch Quarkus’ eigene CDI-Variante namens ArC [5]. Alles nichts, was man nicht in den Griff bekommen kann, aber was am Ende evtl. ein wenig manuellen Zutuns bedarf, um seine Services inkl. der eingebundenen 3rd-Party unter Quarkus zum Laufen zu bekommen.
Zum anderen ist unser Runnable nun nicht mehr plattformunabhängig! Dabei ist WORA (write once, run anywhere) doch das große Versprechen von Java! Aber ist das wirklich ein Problem? Unsere Services sollen in einem Container laufen. Das gilt sowohl auf lokalen Rechnern als auch in der Cloud. D. h. nicht das zugrunde liegende OS des Rechners ist entscheidend, sondern vielmehr das des Containers. Und genau das ist auf allen Systemen gleich und vorhersehbar. „Write once, run predictable“ aka WORP ist das neue WORA.
Fazit
JEE war jahrelang der Primus, wenn es um die Umsetzung von großen, unternehmensweiten Anwendungen ging. Grund dafür waren vor allem ein über zwei Jahrzehnte ausgereiftes API sowie eine sehr stabile Runtime. Entsprechend groß waren/sind die Community und die Anzahl der existierenden Anwendungen.
Typische JEE-Anwendungen sind in der Regel monolithischer Natur und laufen in einer zentralen Ablaufumgebung, dem JEE Application Server. In Zeiten von Cloud und Co. ändern sich die Anforderungen (Abb. 7). Aus einem Monolithen wird eine Vielzahl von Services. Aus der zentralen Ablaufumgebung eine Cloud-Native-Umgebung mit den Key-Playern Docker-Container und Kubernetes.
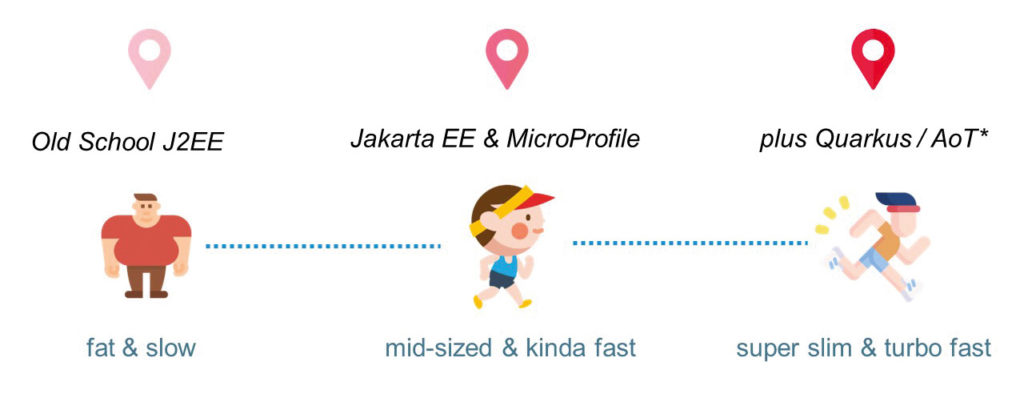
Abb. 7: Jakarta EE in Zeiten von Cloud-Native
Die Realisierung einzelner Services ist dank APIs wie JAX-RS, JSON-P, JSON-B und CDI mit JEE kein Problem. Erzeugt man im Build-Prozess ein entsprechendes schlankes Paket (ueber.jar oder besser hollow.jar plus app.war), sind auch die resultierenden Containergrößen und Start-up-Zeiten akzeptabel.
Durch die Verteiltheit des Systems und den Wegfall des Application Servers als der zentralen Laufzeitumgebung ergeben sich neue Herausforderungen. Hier hilft das Jakarta MicroProfile mit seinen speziell auf verteilte Systeme zugeschnittenen APIs.
Mit der Kombination von JEE und MicroProfile haben wir somit einen guten Stack zur Implementierung von Microservices-basierten Anwendungen an der Hand. Das gilt zumindest dann, wenn der Anspruch an die eigene Anwendungswelt nicht darin besteht, alle paar Minuten neue Deployments vorzunehmen oder bestehende Services in Nahezu-Echtzeit rauf- bzw. runterzuskalieren.
Ist das notwendig, so kann auf Quarkus und seine Build Time Optimization zurückgegriffen werden. Metadata-Processing, das normalerweise zur Bootstrap-Zeit ausgeführt werden würde, kann in der Build-Phase durch statischen Code ersetzt werden, und so lassen sich das resultierende Artefakt in seiner Größe sowie die zu dessen Start notwendige Zeit deutlich reduzieren.
Muss es noch kleiner und schneller sein, z. B. in Szenarien mit stark schwankender Workload und entsprechender Anforderung an dynamische Skalierung, oder aber bei der Implementierung von Serverless Functions, kann mit Hilfe der Ahead-of-Time Compilation von Quarkus ein natives Excecutable erzeugt werden. Das ist dann zwar nicht mehr plattformunabhängig, was aber bei einer vorhersehbaren Ablaufumgebung – dem Container – kein wirkliches Problem darstellt.
Links & Literatur
[4] https://quarkus.io/guides/writing-native-applications-tips




