

Um echtes Continuous Delivery (CD) zu betreiben und trotzdem durchgetestete Software zu liefern, benötigen wir automatisierte E2E-Tests. Klassischerweise werden diese vom nachgelagerten Testteam durchgeführt. In einem agilen Umfeld möchten wir jedoch Abhängigkeiten von anderen Teams vermeiden und die Software trotz asynchroner oder synchroner Schnittstellen selbst mit der eigenen CD Pipeline durchtesten und deployen – in der Produktion. CD sieht in der Theorie etwa so aus: Code, Push, CD-Pipeline, Deploy to PROD. In der Praxis könnte sich aber folgende Debatte entwickeln:
Der Product Owner (PO) sagt: „Stopp! Ihr könnt doch Software nicht ohne in einer explizit aufgesetzten Integrationsumgebung durchgeführte End-to-End-Tests (E2E) in die Produktion ausliefern.“
Dev: „Why not? Wir haben alles mit der Pipeline getestet.“
PO: „Aber doch nur innerhalb eurer Microservices! Was ist mit den Interaktionen zu den anderen Systemen?! Die können nur in einer Integrationsumgebung ordentlich als End-to-End-Test getestet werden.“
Dev: „In so einem Vorgehen können wir nicht nach Continuous Delivery arbeiten. Und wieso brauchen wir E2E-Tests auf einer Integrationsumgebung, wenn wir innerhalb unserer Pipeline alles automatisiert testen?“
PO: „Nichts für ungut, aber ihr könnt nicht alle Fälle, die da draußen in der richtigen Welt passieren können, in euren Tests abbilden.“
Dev: „Eigentlich haben wir alle fachlichen Fälle, die du uns als Anforderung hoch priorisiert hast, auch mit fachlichen Tests abgedeckt. Und alle andere Fälle lassen wir nicht zu. Das ist unsere Definition of Done (DoD).“
PO: „Vielleicht habt ihr fachlich alle Fälle sauber mit Tests abgedeckt, aber schon die Schnittstellen und die Interaktion mit den anderen Systemen, da kann doch einiges schiefgehen. Andere Systeme könnten die Schnittstellen geändert haben.“
Dev: „Wir haben doch alle unsere Schnittstellen mit den Consumer-driven Contracts abgesichert.“
PO: „Und was ist mit der technischen Verbindung, URL, Topic etc.? Woher wissen wir, dass die Verbindung mit den anderen Systemen in der Produktivumgebung funktioniert, ohne das einmal auf einer anderen Umgebung getestet zu haben?“
Dev: „Ja, das stimmt, dafür haben wir Infrastructure-as-a-Code-Unit-Tests und auch – als letzte Sicherheit – Health Checks. Sobald eine Verbindung nicht erfolgreich aufgebaut werden kann, wird die neue Version der Anwendung automatisiert heruntergefahren. Das neue Deployment wird dadurch gestoppt. Die alte Version läuft weiterhin.“
PO: „Trotzdem, die E2E-Tests werden vom Testexperten durchgeführt und auf diese Qualitätskontrolle von außen können wir nicht verzichten.“
Dev: „Dadurch sind wir jedoch abhängig vom Testmanagementteam und können nicht automatisiert in die Produktion deployen. Außerdem steht das dem Fail-Fast-Prinzip entgegen, nach dem wir unsere Fehler sofort – am besten, sobald sie entstanden sind – entdecken können, um sie direkt zu beheben.“
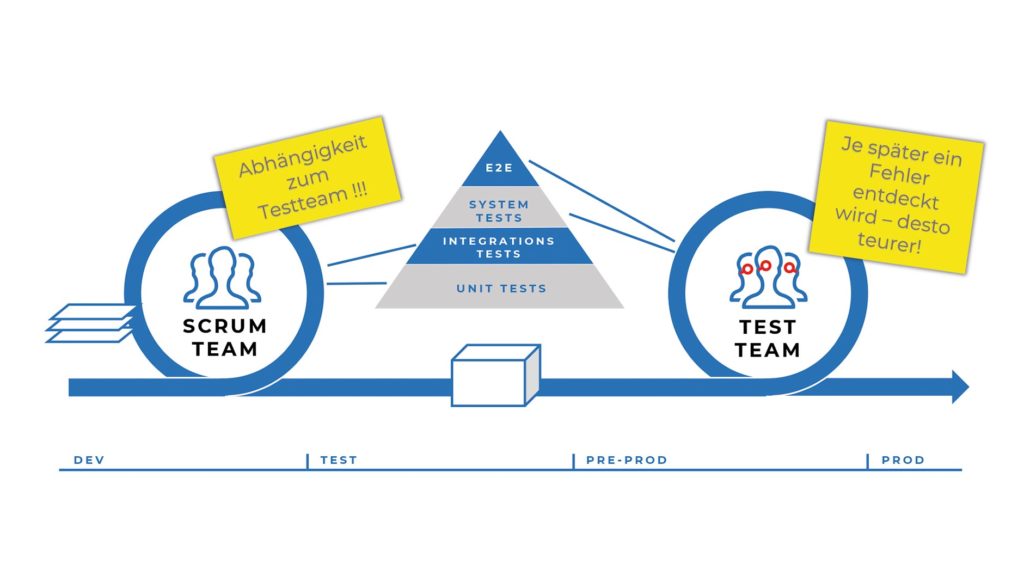
Abb. 1: Nachgelagertes Testteam
So oder ähnlich könnte aktuell eine Debatte über die Integrationstests bei verteilten Systemen ablaufen. Diese POs lassen sich nicht überzeugen, oder? Dabei wissen wir es in der Dev-Community doch mittlerweile besser. Es ist State of the Art, alle Tests zu automatisieren und eine CD Pipeline bis in die Produktion aufzusetzen, oder etwa nicht? Giganten wie Amazon oder Facebook liefern täglich mehrere Tausend Änderungen in die Produktion aus.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Testanforderungen
Vielleicht sollten wir unsere Vorgehensweise hin zu proaktiv ändern. Wenn wir aus der Softwareentwicklung heraus einen Prozess-Change in Richtung Continuous Delivery herbeiführen wollen, müssen wir eventuell selbst die Frage an den Entscheider stellen – falls das Team nicht selbst entscheiden darf und noch nicht gänzlich nach dem DevOps-Ansatz arbeitet. Nehmen wir an, dass der PO entscheidet, so würde die Anforderung sicherlich lauten: Die deployte Software soll in der Produktion fehlerfrei laufen. Dafür soll die Testpyramide vollständig abgetestet sein, und der E2E-Test wird in der Integrationsumgebung durchgeführt.
Ungeachtet der Tatsache, dass ein Ausfall der Software auch durch äußere Umstände herbeigeführt werden kann und nicht nur durch interne Softwarefehler, ist mit „fehlerfrei“ implizit auch die Ausfallsicherheit und anderweitige Sicherheit gemeint. Wir brauchen robuste Software, die ausfallsicher auf einer ausfallsicheren Laufzeitumgebung zur Verfügung gestellt wird. Dabei soll die Integration mit externen Schnittstellenpartnern ebenfalls ausfallsicher aufgebaut sein.
Das ist ganz schön viel – wie kommen wir auf die Idee, dies mit der CD abdecken zu können? Eins nach dem anderen. Die Testpyramide ist komplex, lässt sich jedoch auseinanderbauen.
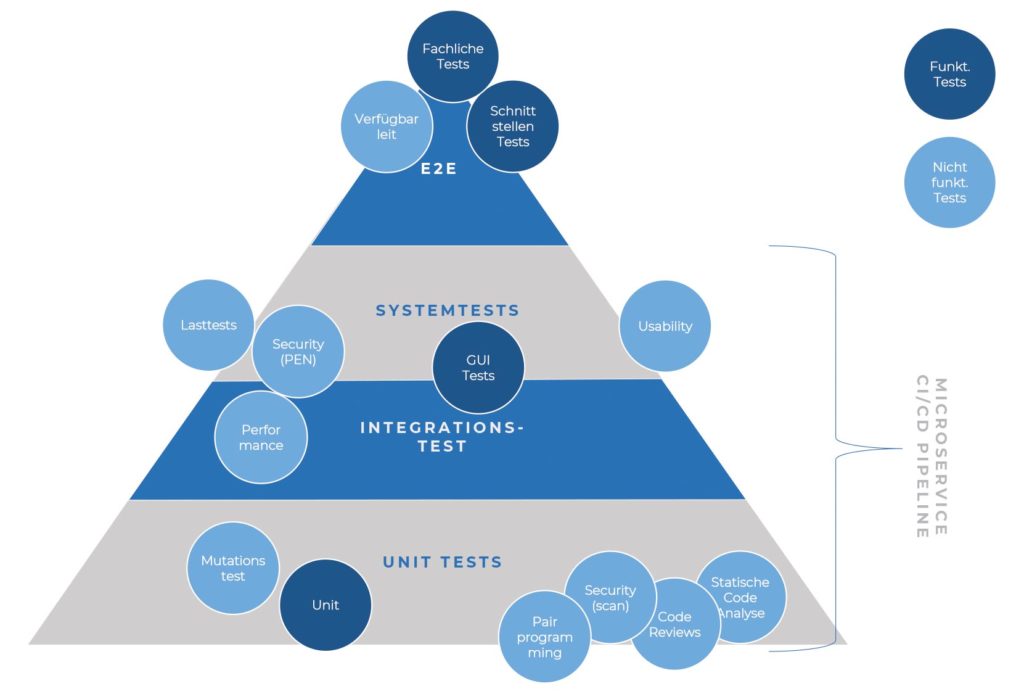
Abb. 2: Klassische Zuordnung der Tests auf die CI/CD Pipeline
Infrastructure as a Code (IaC) hilft uns, alles, was mit der Laufzeitumgebung zu tun hat, als DevOps-Team in die eigene Verantwortung zu holen. Dass IaC auch mit eigenen Unit-Tests abgesichert sein soll, ist klar – ansonsten können wir keine Garantien ausgeben. Mit den Health Checks und den Smoke-Tests können wir die Verfügbarkeit der erwarteten Infrastruktur und die Konfiguration der Integration direkt nach dem Deployment prüfen.
Wie schaut es mit Security-, Last- und Performancetests aus? Auch sie dürfen wir nicht vernachlässigen, und es gibt auch entsprechende Lösungen. In diesem Artikel konzentrieren wir uns jedoch auf die fachlichen E2E-Tests.
Unser Ziel: Automatisierung der E2E-Test, jedoch nur im jeweiligen Verantwortungsbereich des DevOps-Teams. Von der Oberfläche bis zu den öffentlichen Schnittstellen mit den Partnersystemen. Übergreifende, echte E2E-Tests sollen somit nach dem Shift-Left-Prinzip in viele kleine Teile aufgeteilt und die E2E-Verantwortung an die jeweiligen Teams delegiert werden. Aus Sicht des DevOps-Teams und des dazugehörigen Softwareprodukts wird die Testphase in die Entwicklung integriert.
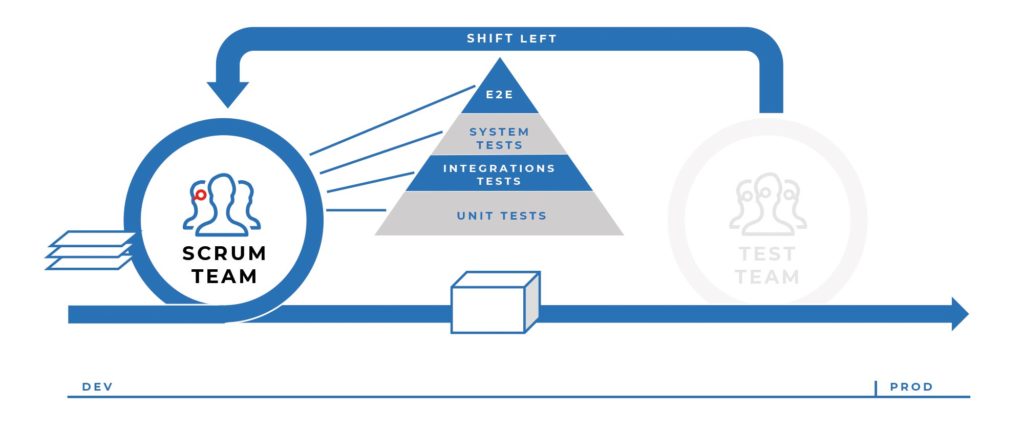
Abb. 3: Vorziehen der nachgelagerten Tests nach dem Shift-Left-Prinzip
Letztendlich sollen die E2E-Fälle vollständig abgedeckt sein. Doch wie können wir sicherstellen, dass trotzdem der gesamte Prozess funktioniert, auch wenn wir nur ein Teil der gesamten E2E-Prozesse testen?
Wir benötigen eine Möglichkeit, die E2E-Tests auf die Teams aufzuteilen, sodass jedes Team seinen Anteil in eigener Obhut auch mit eigenen automatisierten Tests abdecken kann – gleichzeitig soll jedoch sichergestellt sein, dass alle E2E-Testcases (Geschäftsfälle) abgedeckt werden und an den Schnittstellen bei allen Schnittstellenpartnern das gleiche Verständnis der Nutzung der Schnittstelle herrscht.
Der erste Teil ist einfach. Das erwartete Verhalten des jeweiligen Teilsystems, das in dem Prozess interagiert, kann mit automatisierten Black-Box-Integrationstests abgedeckt werden. Optimalerweise wird hierfür Behaviour-driven Development eingesetzt – dazu kommen wir noch.
Dass es jedoch genau an den Schnittstellen trotz aller Abstimmungen zu Fehlern kommt, wenn diese zum ersten Mal nach der Implementierung/Anpassung integrativ zusammengeschaltet werden, wissen wir leider aus eigener Erfahrung. Wir können dem PO nicht übelnehmen, dass er uns das nicht abkauft.

APIs, APIs, APIs
APIs, wie wir die Schnittstellen lieber nennen, müssen zwischen den Parteien abgestimmt sein. Wir Menschen sind jedoch nicht gut darin, fehlerfrei miteinander zu kommunizieren. Deshalb haben wir Spezifikationsstandards für die Schnittstellen entworfen. Angefangen vom CSV über Cobol Copybook bis zu XSD, WSDL und JSON Schema, OpenAPI, AsyncAPI, Avro, Protobuf etc. Mittels des Schema-First-API-Ansatzes kann das zentral abgestimmte Schema an Schnittstellenparteien verteilt werden, um den Server Proxy und die Client Stubs daraus zu generieren. Wenn wir die Schemaspezifikation dann noch für jedes einzelne Feld durch Regular Expressions absichern, kann nichts mehr schiefgehen, oder?
Leider doch, und zwar dann, wenn die Schnittstelle zwar technisch korrekt eingebunden ist, aber die Bedeutung fachlich missverstanden wurde. Dann tauchen die resultierenden Fehler erst bei der ersten echten Integration auf.
Eine zentrale Schemadefinition ist außerdem nicht für alle Schnittstellen optimal, wenn es darum geht, die Geschwindigkeiten der jeweiligen Teams voneinander zu entkoppeln. Ein zentrales Schema koppelt die beteiligten Parteien eng aneinander. Sobald eine Änderung aufgrund einer Partei erfolgen muss, müssen oft alle anderen beteiligten Parteien die Änderungen im Gleichschritt umsetzen und veröffentlichen. Daher geht die Entwicklung mittlerweile zum Code-First-API-Ansatz, nach dem die Schnittstelle vom Provider zuerst implementiert wird und – davon ausgehend – nach einer Beschreibung die Implementierung der Schnittstellennutzer-(Consumer-)Anbindung erfolgt. Die Consumer implementieren nur diejenigen Teile der Schnittstellen, die sie tatsächlich benötigen. Wenn sich die Schnittstelle ändert und die Änderung rückwärtskompatibel umgesetzt wurde, muss nur der Consumer angepasst werden, der diese Änderung nutzen möchte. Zeitlich gesehen, kann diese Anpassung nachgelagert geschehen. Damit erreicht man eine lose Koppelung zwischen den Schnittstellenpartnern.
Ein weiteres Argument für das Testen der nach dem Code-First-API-Ansatz implementierten Schnittstellen ohne zentrales Schema ist, dass beim Schema-First-Ansatz nicht nur die fachliche Einbindung fehlerhaft sein kann, sondern auch die technische Implementierung des API selbst.
Consumer-driven Contracts
In dem beschriebenen Szenario, in dem die Consumer eines API nur die Untermenge des vollständigen API verwenden, ist es für den API-Provider interessant, die Nutzungsweise der jeweiligen Consumer zu kennen. Dazu zwei Beispiele:
-
Ein Feld, das von keinem Consumer verwendet wird, kann so einfach aus dem API entfernt werden.
-
Bei den Anpassungen an einem Feld müssen nur die betroffenen Consumer informiert werden.
Dies ist die zentrale Idee des Consumer-driven Contract-(CDC-)Ansatzes. Beim CDC handelt jeder Consumer eines API dessen Nutzungsweise in Form eines Vertrags aus und stellt diese dem API-Provider zur Verfügung. Diese Verträge werden sowohl auf der Consumer- als auch auf der Providerseite für das unabhängige und damit entkoppelte Testen einer Schnittstelle herangezogen. Dadurch kommen wir der PO-Anforderung nach, dass alle Schnittstellen getestet werden müssen.
In einem solchen CDC-Vertrag (oder nur CDC) definiert jeder API Consumer für sich folgende Rahmenbedingungen der API-Nutzung, von denen der Consumer selbst ausgeht:
-
Bei synchronen APIs:
- Struktur der Anfrage (Request), die der API Consumer bei der API-Anfrage erstellen wird
- Header
- Key-Value-Wertepaare
- Payload
- Schemaähnliche Definition der Request-Struktur
- Header
- Struktur der Antwort (Response), die der API Consumer bei der API-Anfrage als Antwort erwartet
- Header
- Key-Value-Wertepaare
- Payload
- Schemaähnliche Definition der Response-Struktur
- Header
- Struktur der Anfrage (Request), die der API Consumer bei der API-Anfrage erstellen wird
- Bei asynchronen APIs
- Struktur der Nachricht (Message), die der API Consumer bei der API-Nutzung erwartet
- Header
- Key-Value-Wertepaare
- Payload
- Schemaähnliche Definition der Response-Struktur
- Header
- Struktur der Nachricht (Message), die der API Consumer bei der API-Nutzung erwartet
Provider States: Das Ganze definiert der Consumer jeweils je genutztem Provider State. Das ist der Zustand des Providers oder des angefragten/publizierten Datensatzes. Dazu zwei Beispiele:
-
Für den Provider State „Datensatz nicht vorhanden (404)“ sieht eine Antwort anders aus, als wenn ein Datensatz vorhanden ist.
-
Falls der Schnitt des API unterschiedliche Datensatzausprägungen zulässt, die dann jeweils andere Pflichtfelder in der Antwort/Nachricht haben, wäre bei einem Person-API, bei dem auch die Beziehungen der Personen ausgegeben werden, ein möglicher Provider State: „Person mit Beziehungen“. Bei der Person mit Beziehungen sieht die Antwort/Nachricht anders aus, als wenn keine Beziehungen vorhanden sind.
Beim CDC-Ansatz rückt mit der Definition der Provider States die fachliche Nutzung der APIs in den Vordergrund. Erst durch diese fachliche Perspektive des API können wir für das gleiche API, sofern es in unterschiedlichen fachlichen Fällen anders genutzt wird, die jeweilige Nutzungsweise definieren und testen. Das API wird also abhängig von der fachlichen Nutzung getestet. Ein Test für den Provider State „Person mit Beziehungen“ prüft, ob die Beziehungen korrekt über das API gemeldet wurden. Bei einer Person ohne erfasste Beziehungen, aber mit „Biometrischen Daten“ sieht die API Response/Event wieder anders aus. Die API-Tests können damit für alle unterschiedlichen Ausprägungen als Provider States definiert werden. Zu viele Provider States weisen allerdings auf einen schlechten Schnitt des API hin.
Provider-Tests: Nachdem der Consumer für alle genutzten Provider States den CDC definiert hat, kann er diesen zum Zweck der Information und Verifikation an den Provider kommunizieren. Erst bei der Rückmeldung der erfolgreichen Verifikation des CDC durch den Provider kann der Consumer davon ausgehen, dass von ihm getroffene Annahmen bei der Erstellung des CDC auch vom Provider erfüllt werden können. Beim CDC Testing spricht man dabei von Providert-Test.
Consumer-Tests: Bevor der Consumer den CDC an den Provider kommuniziert, soll er für sich selbst prüfen, ob der von ihm erstellte CDC tatsächlich mit der API-Implementierung übereinstimmt. In dem Fall sprechen wir von einem Consumer-Test.
CDC Broker: Um die Publikation und Durchführung der CDC-Tests zu erleichtern, bieten alle CDC-Testing-Frameworks einen zentralen Knoten, der die publizierten CDCs entgegennimmt und den Providern für die Verifikation zur Verfügung stellt. Da die CDC-Tests automatisiert in den CD Pipelines ablaufen sollen, ist daher der CDC Broker von immenser Bedeutung für den Ansatz, denn erst durch ihn ist die Automatisierung erreichbar.
Der CDC Broker protokolliert die Testläufe. Wenn es also zu einer Abweichung in der API-Implementierung kommt, wird dies im CDC Broker registriert und die Tests der Teams schlagen Alarm. Zusätzlich hat der CDC Broker eine rudimentäre Weboberfläche, welche die auf dem Broker veröffentlichten Verträge anzeigt und weitere Informationen dazu wiedergibt.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Schritte des Consumer-driven Contracts
Um den vollständigen CDC-Prozess abzuschließen, sind folgende Schritte notwendig: Die Vorbedingung ist, dass der Provider die API-Doku mit allen möglichen Provider States bereitgestellt hat:
-
Consumer
- Consumer definiert den CDC
- Consumer verifiziert den CDC intern im Consumer-Test
- Nach dem erfolgreichen Consumer-Test publiziert der Consumer seinen CDC auf dem zentralen CDC Broker
-
Provider
- Provider verifiziert alle für ihn publizierten CDCs und meldet das Ergebnis an den Broker zurück. Wichtig hierbei: Die Provider-Verifikation sollte von Consumern automatisiert angetriggert werden können, um die Consumer CD Pipeline nicht zu blocken.
Erst bei der erfolgreichen Verifikation durch den Provider kann der Consumer sicher sein, dass die API-Implementierung in der Integration funktionieren wird, und seine Änderungen produktiv veröffentlichen.
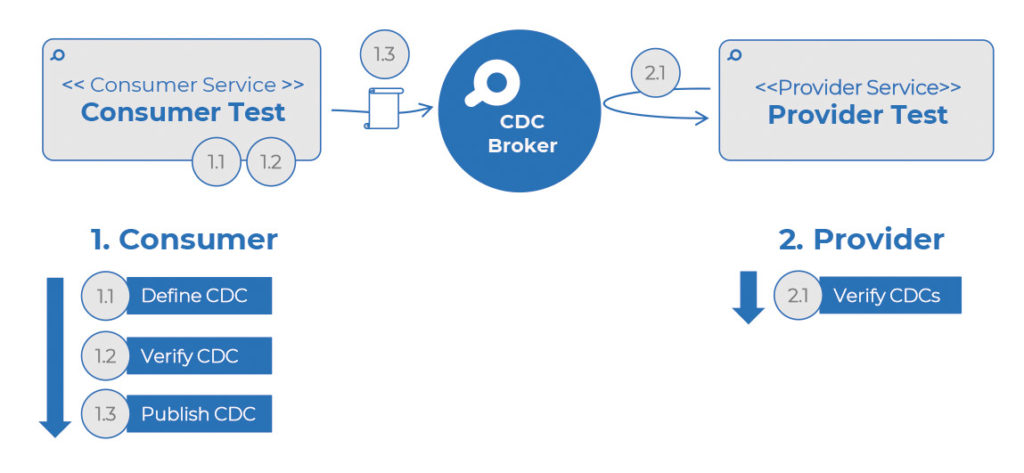
Abb. 4: Schritte des Consumer-driven Contracts
PACT [1] ist zurzeit das bekannteste CDC-Framework, gefolgt von Spring Cloud Contract [2]. Ein Vergleich dieser beiden Frameworks im Detail wurde bereits von unseren Kollegen durchgeführt und kann auf entwickler.de nachgeschlagen werden [3].
Behaviour-driven Development
Mit dem CDC-Ansatz können wir sicherstellen, dass die Schnittstellen funktionieren. Dies ist jedoch nur ein Teil der E2E-Tests. Abseits der Schnittstellen ist der Kern jeder Anwendung die eigene fachliche Logik. Viel bekannter als CDC ist der Ansatz Behaviour-driven Development (BDD).
Beim BDD-Ansatz wird das erwartete Soll-Verhalten einer Anwendung in Form der fachlichen Akzeptanzkriterien definiert. Dabei bedient sich der BDD-Ansatz der Idee des Test-driven Development (TDD). TDD wird jedoch beim BDD eine Stufe höher, nämlich auf die fachlichen Anforderungen, angewendet. So kann der PO bei der Definition der Anforderungen in einer User Story auch die BDD-Akzeptanzkriterien definieren. Erst wenn diese erfüllt werden, ist die Fachlichkeit korrekt implementiert. Die Akzeptanzkriterien sollen dabei so klar und eindeutig definiert werden, dass sie auch zu deren eigener Verifikation eingesetzt werden können. Die Akzeptanzkriterien bilden damit auch die fachliche Testspezifikation mit den Testdaten ab.
Die Vorteile liegen für das Dev-Team auf der Hand: Durch die Testspezifikation wird ein Beispielablauf mit sinnvollen fachlichen Beispieldaten (Testdaten) beschrieben, was bei der Entwicklung eventuelle Missverständnisse aus einer rein abstrakten Beschreibung reduziert – nach dem Motto „Ein schlechtes Beispiel ist immer noch besser als eine bloße Beschreibung“. Und diese soll bereits vorab nach der TDD-Idee implementiert werden. Ein erwartetes Verhalten wird so vorab getestet und erst dann als erfolgreich getestet gemeldet, wenn die Anforderung wie spezifiziert umgesetzt wurde. Der PO kann dann die User Story bewiesenermaßen abschließen. Die implementierten Tests bleiben erhalten und dienen als Regressionstests für weitere Anpassungen der Anwendung.
Die Spezifikation der Akzeptanzkriterien folgt dabei dem klassischen Muster der Testspezifikation. Zuerst werden die Vorbedingungen definiert (GIVEN). Dementsprechend kann das definierte Verhalten ausgelöst/angestoßen werden (WHEN). Letztendlich werden die Ergebnisse verifiziert (THEN).
Durch den Einsatz vom Domain-Specific-Language-(DSL-)Lösungen wird ermöglicht, dass diese Spezifikation in der fachlichen Domänensprache erfolgt. Dadurch bleibt die Spezifikation auch als Dokumentation des Verhaltens der Anwendung für eine breite Zielgruppe nutzbar.
Die Anforderungen werden als fachliche Szenarios definiert. Mehrere Szenarien spezifizieren eine Funktion und können alle innerhalb einer feature-Datei abgelegt werden. Die BDD-Frameworks führen diese als automatisierte Tests aus, was wiederum eine Voraussetzung für den Einsatz innerhalb der CD Pipelines ist. Das Beispiel in Listing 1 stellt eine derartige Funktion mit mehreren Szenarien dar.
Feature: Anlage einer Adresse
Durch diese Funktion wird eine neue Adresse angelegt
@positive
Scenario Outline: Erfolgreiche Anlage einer neuen Inland-Adresse
Given Person <person> existiert
When neue Adresse mit folgenden Daten angelegt wird:
person: <person>
strasseNr: <strasseNr>
plzOrt: <plzOrt>
Then wurde die Adresse erfolgreich als Inland-Adresse erfasst
Examples:
| person | strasseNr | plzOrt |
| Helena Adam | Musterstr. 12 | 12345 Musterstadt |
| Manuell Ernst | Heßbrühlstr. nn | 88888 Ortens |
| Sabine Lustig | Nope Drope 234f | 90009 Zentopia |
Wie das Beispiel in Listing 1 zeigt, wurde für drei unterschiedliche Durchläufe (Exampels) ein Szenario-Outline (Template) definiert. Bei der Durchführung des Tests muss als Vorbedingung eine Person mit passendem Namen angelegt werden. Dabei scheinen weitere Pflichtfelder der Person irrelevant zu sein. Der Test muss sich also darum kümmern, dass hinter dem Schritt Person <person> existiert eine Person mit dem jeweiligen Namen angelegt wird.
Unter When wird dann die Adresse zu der bestehenden Person erfasst und gespeichert. Das ganze Szenario bearbeitet nur die positiven Fälle, was hier mit dem Custom-Tag @positive dargestellt wird. Fehlerfälle sind hierbei Out of Scope und würden in einem eigenen Szenario abgebildet, was wohl der PO durch eine weitere User Story spezifizieren wird.
Schließlich muss der Then-Schritt die zuletzt erfasste Adresse auslesen und prüfen, ob diese mit dem Inlandkennzeichen wie gefordert erfasst wurde.
Das BDD-Framework kann solch eine Featurespezifikation als Unit-Test ausführen und die Ergebnisse sowohl für die CD Pipeline wie auch als Reports melden. Eines der am meisten eingesetzten Frameworks im Java-Umfeld ist Cucumber [4]. Falls man auf den Glue-Code (Ausimplementierung der Testschritte) verzichten und etwas technischere Beschreibungen der Szenarien in Kauf nehmen möchte, kann man mit dem Karate Framework [5] die Implementierung der Tests schneller umsetzen.
Kein Mut zur Testlücke bei der fachlichen Testabdeckung
Mit BDD-Tests decken wir die Fachlichkeit ab, mit CDC-Tests die Schnittstellen. Können wir damit die klassischen E2E-Tests bereits ad acta legen? Noch nicht ganz.
Die E2E-Tests stellen sicher, dass alles im Zusammenspiel funktioniert. Wir haben jedoch nur sichergestellt, dass die jeweiligen BDD-Tests und die jeweiligen CDC-Tests eigene Bereiche abdecken. Um den gesamten Geschäftsfall abzudecken, müssten wir diesen sowohl in BDD-Tests als auch in CDC-Tests stückeln und alle teilnehmenden Anwendungen damit abdecken. Erst wenn wir sowohl die Fachlichkeit als auch die Schnittstellennutzung für den jeweiligen Geschäftsfall testen – und dies in der gesamten Kette bei allen teilnehmenden Anwendungen gemacht wurde – ist keine Testlücke mehr im E2E-Geschäftsprozess vorhanden.
Da aktuell kein Framework BDD und CDC in einem kann, haben wir beide Ansätze kombiniert. Da beide auf die fachliche Ausrichtung (bei CDC Provider States) setzen, ist es uns möglich, die fachlichen E2E-Tests so aufzuteilen, dass sowohl die vollständige Umsetzung der Fachlichkeit als auch die der Schnittstellen je Geschäftsfall getestet werden kann.
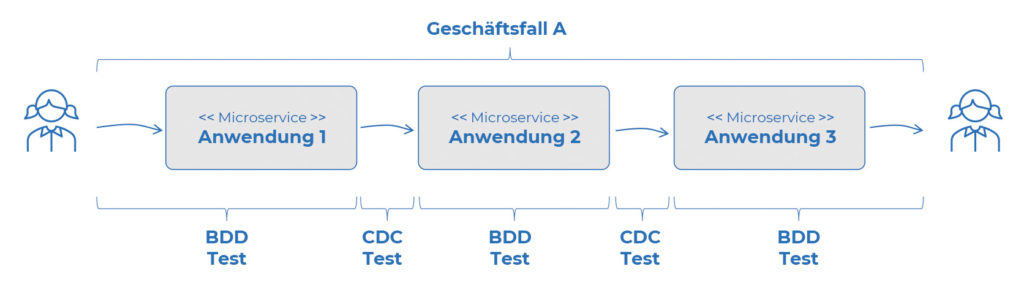
Abb. 5: Aufteilung des E2E-Tests auf die BDD- und CDC-Tests je Geschäftsfall
Das sieht nun nach viel Arbeit aus, aber das täuscht. Das ist nur die Folge des Shift-Left-Prinzips, in dem die klassisch nachgelagerten E2E-Testaufwände in die Entwicklungsphase hineinverlagert werden. In der Summe sind die Gesamtaufwände durch die frühzeitige Fehlererkennung und Vollautomatisierung der Tests geringer.
Agile-driven Integrationstests
Das A und O beim Ansatz Agile-driven Integrationstests sind die Identifikation der fachlichen Ereignisse (Events) und die Definition der Interaktionen zwischen Benutzer und Anwendung sowie zwischen den Anwendungen selbst. In einem Domain-driven-Design-(DDD-)Kontext kann dies beispielsweise als Ergebnis eines Event-Storming-Workshops entstehen. Sobald die wichtigsten Events (Pivotal-Events) identifiziert wurden, können sie in der Folge von den beteiligten Teams im Detail spezifiziert werden. Um auch alle unterschiedlichen Geschäftsfälle sorgfältig testen zu können, ist es hierbei notwendig, dass auch die unterschiedlichen Ausprägungen der Pivotal-Events als Provider States identifiziert und als Referenzevents definiert werden. Diese Definitionen der Referenzevents je Provider States dienen als Grundlage für BDD- und CDC-Tests. In Abbildung 6 ist der gesamte Ansatz vereinfacht dargestellt.
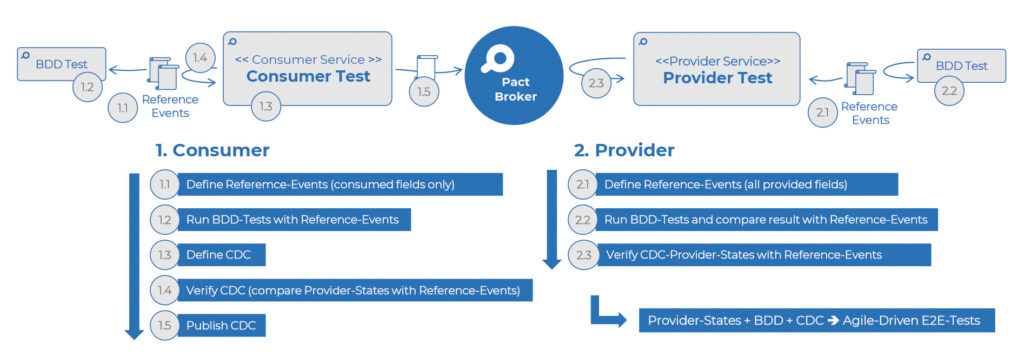
Abb. 6: Agile-driven Integrationstests
Die Vorbedingung des CDC-Ansatzes gilt auch hier: Der Provider hat die API-Dokumentation mit allen möglichen Provider States bereitgestellt.
Wie in Abbildung 6 in den Schritten 1.1 und 2.1 gezeigt, definieren sowohl Provider als auch Consumer die Referenzevents – oder Requests-Responses-Objekte im Falle des synchronen API – für jede benötigte Ausprägung des Geschäftsprozesses als eigenständigen Provider State. Im nächsten Schritt wird, zunächst ausgehend von den Referenzevents der Provider States, die jeweilige Logik mit den BDD-Tests (Schritte 1.2 und 2.2) getestet. Auf der Consumer-Seite kann der jeweilige für den Provider State erstellte BDD-Test mittels Referenzevent direkt ausgelöst werden. Auf der Provider-Seite dagegen werden die Referenzevents als Expected Events mit dem Ergebnisevent (Actual Event) aus den BDD-Tests verglichen. Wurde die jeweilige fachliche Logik erfolgreich getestet, können sowohl Provider als auch Consumer die CDC-Tests umsetzen und hierfür jeweils die Referenzevents für die Provider States als Basis einsetzen (Schritte 1.3–1.5 und 2.3).
Für die aktuellen CDC-Tools muss die Definition der Verträge in der jeweiligen DSL (Pact DSL bei Pact und Groovy DSL bei Spring Cloud Contract) weiterhin vom Consumer ausprogrammiert werden. Der Consumer-Test wird jedoch durch die Referenzevents stark vereinfacht. Da die fachliche Logik bereits mit dem BDD-Test verifiziert wurde, muss der Consumer-Test jetzt nur sicherstellen, dass der publizierte Vertrag mit den definierten Referenzevents je Provider State übereinstimmt. Der Provider dagegen kann für die Durchführung der Provider-Tests eigene Referenzevents 1:1 verwenden.
Wichtig ist: Die jeweiligen Consumer- und Provider-Schritte können entkoppelt voneinander umgesetzt werden. Die CDC Tools bieten hierfür Unterstützung mit Versionsnummern für Consumer/Provider. Die Teams sollen trotzdem die Änderungen des API miteinander abstimmen, können jedoch entkoppelt voneinander die Anpassungen implementieren und diese auch bis in die Produktion, unabhängig vom jeweiligen Deployment der anderen, veröffentlichen.
Hands-on – das Event-driven-Architecture-Szenario
Bevor wir in die Praxis starten, wollen wir einen Blick auf unser fachliches Szenario werfen. Für unser Beispiel wollen wir zwei Bounded Contexts (aus dem Domain-driven Design) miteinander interagieren lassen. Für jeden Bounded Context ist ein separateres Scrum-Team zuständig, dessen Mitglieder alle in komplett getrennten Umgebungen arbeiten. Eigene Technik, eigene Sprache.
In Abbildung 7 sehen wir links den Bounded Context Personen, mit den Entitäten Person, Anschrift und biometrische Daten, und rechts den Bounded Context Grüße, mit den Entitäten Person und Gruß. Wichtig dabei ist, dass die Person in Personen keine direkte Beziehung zu der Person in Grüße hat.
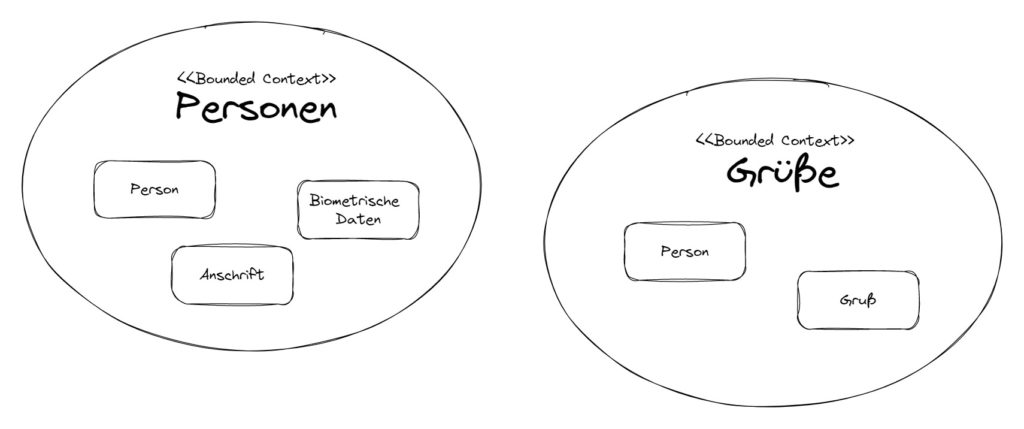
Abb. 7: Bounded Context
Die Entitäten können ähnliche oder gleiche Konzepte haben, müssen aber nicht. Sie haben in jedem Bounded Context ihre eigene Daseinsberechtigung und ihren eigenen fachlichen Wert. Der Bounded Context Personen verantwortet die Verwaltung der Personendaten. Jegliche Änderung der Daten einer Person wird in einem Event Person geändert publiziert.
Der Bounded Context Grüße benötigt die Personendaten in eigenem Kontext. Er konsumiert die publizierten Events und wandelt die Daten in seine Interpretation der Person um. Wenn dies abgeschlossen ist, kann der Nutzer einen Gruß an die Person erzeugen.
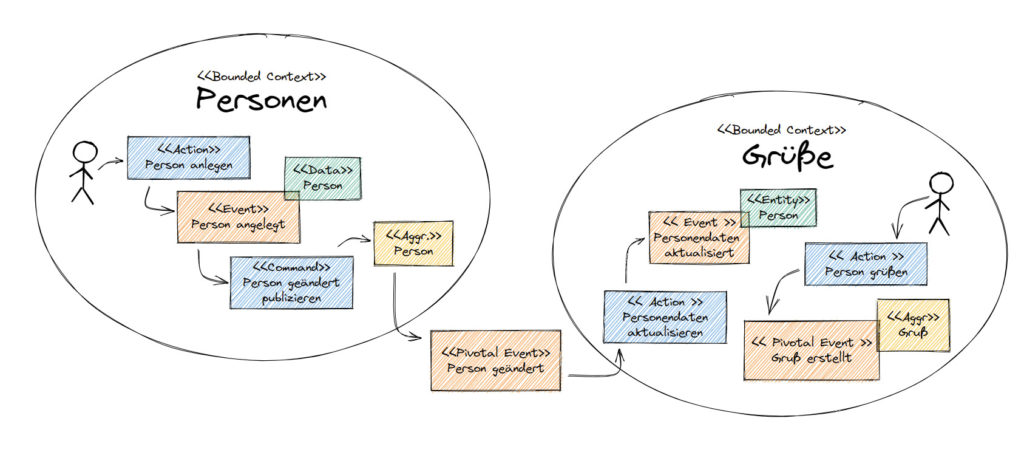
Abb. 8: DDD Pivotal Event
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
CDC-Vertrag
Da wir möchten, dass beide Bounded Contexts unabhängig voneinander arbeiten (siehe Consumer-driven Contracts) soll das asynchrone API mit dem Event Person geändert durch den CDC-Vertrag spezifiziert und getestet werden. Das bedeutet, dass sich die Bounded Contexts auf ein Austauschformat einigen. Üblicherweise präsentiert der Eventproduzent dabei sein komplettes Event, und der Konsument gibt an, welche Teile daraus er benötigt. Diese werden dann gemeinsam mit Beispieldaten im Vertrag (engl. Contract) festgehalten. Sind sich beide Seiten einig, werden die Verträge in den Source Code überführt. In dem Beispiel verwenden wir hierfür das Framework PACT [1].
In Listing 2 sehen wir, wie eine solche Einigung aussehen kann. Wir haben uns hier für JSON als Austauschformat entschieden, da das Event auch mit JSON publiziert wird. Im Bereich header werden die vom Consumer erwarteten Headerinformationen beschrieben. Im Bereich payload</em sehen wir den beispielhaften Eventinhalt für den Provider State Person mit Geburtstag, der vom Consumer für eine Person mit Geburtstagsangaben erwartet wird. Dieser Provider State ist für den Consumer relevant, da er für den eigenen Geschäftsfall Geburtstagsgrüße versenden möchte.
{
"header": {
"action": "create",
"contentType": "application/json",
"event": "PersonChanged",
"kafka_topic": "person",
"providerState": "PersonWithBirthday"
},
"payload": {
"id": 1,
"surname": "Adam",
"forename": "Helena",
"email": "[email protected]",
"birthday": "1984-08-06"
}
}
Consumer
Den Anfang macht der Consumer. Dort können wir eine einfache Unit-Test-Klasse für den CDC-Vertrag als eigene PACT-Methode definieren (Listing 3).
@Pact(consumer = "greeting-service-person-consumer")
MessagePact createPersonWithBirthdayPact(MessagePactBuilder builder) {
PactDslJsonBody body = new PactDslJsonBody();
body.integerType("id", 1L)
.stringType("surname", "Adam")
.stringType("forename", "Helena")
.stringType("email", "[email protected]")
.localDate("birthday", "YYYY-MM-dd", LocalDate.of(1984, 8, 6));
Map<String, Object> metadata = new HashMap<>();
metadata.put("Content-Type", "application/json");
metadata.put("kafka_topic", "person");
metadata.put("action", "create");
metadata.put("event", "PersonChanged");
metadata.put("providerState", "PersonChanged");
return builder.given("PersonWithBirthday")
.expectsToReceive("PersonChanged")
.withMetadata(metadata)
.withContent(body)
.toPact();
}
Über die PACT-DSL können wir das Schema unserer Payload schnell und einfach definieren. Neben üblichen Standardtypen können auch Arrays und geschachtelte Objekte definiert werden. Auch ist die Spezifikation der Enumerationen und der Regular Expressions möglich.
Über den MessagePactBuilder</em werden neben der definierten Payload weitere Metainformationen angegeben. Die Methode given erwartet den Namen des Provider States, und die Methode expectsToReceive befüllt man optimalerweise mit dem Namen des Events. Die Header können als Key Value Map spezifiziert werden.
Als Nächstes wird die eigentliche Consumer-Test-Methode zur Verifikation des eigenen PACT-Vertrags zum definierten Provider State implementiert (Listing 4). Über den Parameter pactMethod der Annotation @PactTestFor wird die PACT-Vertrag-Methode angegeben, die verifiziert werden soll. Mit providerType kann der API-Typ als synchron oder asynchron festgelegt werden.
@Test
@PactTestFor(
pactMethod = "createPersonWithBirthdayPact",
providerType = ProviderType.ASYNCH,
pactVersion = PactSpecVersion.V3)
void verifyPersonWithBirthdayPact(MessagePact messagePact) {
new ConsumerVerifier("PersonChanged", "PersonWithBirthday")
.verify(messagePact);
}
Sobald die Consumer-Verifikation erfolgreich implementiert wurde und der Consumer-Test mit dem Maven-PACT-Plug-in gestartet wurde, wird der PACT-Vertrag für den angegebenen Provider State erstellt und im Maven-Target-Verzeichnis als JSON-Datei abgelegt (Listing 5). Üblicherweise ist das target/pacts. Die Datei wird immer nach den angegebenen Consumers und Providern benannt.
{
"consumer": {
"name": "greeting-service-person-consumer"
},
"messages": [
{
"contents": {
"birthday": "1984-08-06",
"email": "[email protected]",
"forename": "Helena",
"id": 1,
"surname": "Adam"
},
"description": "PersonChanged",
"matchingRules": {
"body": {
"$.birthday": {
"combine": "AND",
"matchers": [
{
"date": "YYYY-MM-dd",
"match": "date"
}
]
},
"$.email": {
"combine": "AND",
"matchers": [
{
"match": "type"
}
]
},
"$.forename": {
"combine": "AND",
"matchers": [
{
"match": "type"
}
]
},
"$.id": {
"combine": "AND",
"matchers": [
{
"match": "integer"
}
]
},
"$.surname": {
"combine": "AND",
"matchers": [
{
"match": "type"
}
]
}
}
},
"metaData": {
"action": "create",
"contentType": "application/json",
"event": "PersonChanged",
"kafka_topic": "person",
"providerState": "PersonChanged"
},
"providerStates": [
{
"name": "PersonWithBirthday"
}
]
}
],
"metadata": {
"pact-jvm": {
"version": "4.3.6"
},
"pactSpecification": {
"version": "3.0.0"
}
},
"provider": {
"name": "person-service-person-producer"
}
}
In dem PACT-Vertrag ist das in Listing 3 definierte Format in der PACT-eigenen Notation zu erkennen.
ConsumerVerifier
Die Consumer-Verifikation des PACT-Vertrags findet in unserem Beispiel mit Hilfe von ConsumerVerifier statt. Hierbei handelt es sich um eine eigens in Listing 2 definierte, nach dem Referenz-Event-Format ausgelegte Standard-Helper-Implementierung (Listing 6), die allgemein für Consumer-Tests genutzt werden kann. Damit ist die individuelle Implementierung der Verifikation obsolet, was ein weiterer Vorteil dieses Ansatzes ist, da wir dadurch sehr schlanke CDC-Tests erhalten.
public ConsumerVerifier(final String eventName, final String providerState) {
this.eventName = eventName;
this.providerState = providerState;
mapper = new ObjectMapper();
final Path eventPath = EVENTS_PATH.resolve(eventName)
.resolve(providerState + ".json");
final JsonNode event;
try {
event = mapper.readTree(eventPath.toFile());
} catch (final IOException e) {…}
header = new HashMap<>();
final JsonNode eventHeader = event.get("header");
eventHeader
.fieldNames()
.forEachRemaining(name ->
header.put(name, eventHeader.get(name).textValue()));
payload = event.get("payload");
}
Zur Verifikation erzeugt uns das PACT-Framework aus dem MessagePact-Objekt eine gültige Payload und die dazugehörigen Header. Diese Informationen haben wir in Listing 2 in unseren Test-Resources als JSON-Datei abgelegt.
Der ConsumerVerifier liest nun die Referenzdatei aus und trennt Header und Payload voneinander. Die Daten aus MessagePact und Referenzdatei werden jeweils mit dem Jackson ObjectMapper in JsonNodes gelesen. Mit Hilfe von AssertJ (Listing 7) lassen sich dann beide Werte (actual vs. expected) sehr einfach vergleichen (Schritt 1.4 aus Abb. 6).
public void verify(final MessagePact messagePact) {
final byte[] pactMessage =
messagePact.getMessages().get(0).contentsAsBytes();
final Map<String, Object> pactMetadata =
messagePact.getMessages().get(0).getMetadata();
try {
assertThat(mapper.readTree(pactMessage)).isEqualTo(payload);
} catch (IOException e) {…}
assertThat(pactMetadata).isEqualTo(header);
}
Damit ist der Consumer-Test fertig und kann mit einem einfachen Befehl auf dem zentralen PACT-Broker zur Verifikation veröffentlicht werden: mvn clean verify pact:publish. Ob das Event tatsächlich korrekt konsumiert werden kann, wird mit dem BDD-Test geprüft.
Provider
Der Provider muss zur Implementierung des Provider-Tests nicht auf den Consumer warten. Der Provider-Test kann jedoch erst dann einen Consumer-driven Contract verifizieren, wenn dieser auf einem PACT Broker veröffentlicht wurde. Zur Implementierung des Provider-Tests brauchen wir die Methoden aus Listing 8.
@State("PersonWithBirthday")
public void createPersonWithBirthdayProviderState() {
providerVerifier = new ProviderVerifier("PersonChanged", "PersonWithBirthday");
}
@PactVerifyProvider("PersonChanged")
public MessageAndMetadata personCreatedEvent() throws IOException {
return providerVerifier.toMessageAndMetadata();
}
@TestTemplate
@ExtendWith(PactVerificationInvocationContextProvider.class)
void testTemplate(PactVerificationContext context) {
providerVerifier.verify(Person.class);
context.verifyInteraction();
}
Eine Methode, um den Provider State zu definieren: Diese wird mit @State und dem Namen des Provider States annotiert. In der Methode wird der ProviderVerifier mit den Parametern für Event und Provider State initiiert. Der ProviderVerifier funktioniert ähnlich wie sein Pendant, der ConsumerVerifier. Das heißt, er liest eine JSON-Datei anhand von Event und Provider State aus den Test-Resources.
Die zweite Methode, annotiert mit @PactVerifyProvider und dem Event als Parameter, dient dazu, die Daten für den Abgleich mit dem PACT zur Verfügung zu stellen. Dank des Ansatzes kann mit Hilfe der ProviderVerifier hier eine starke Vereinfachung durch Standardisierung erzielt werden.
Die Methode testTemplate führt nun die Prüfung des PACT aus. Zuerst wird geprüft, ob die Daten aus Listing 9 als PACT-Referenzdatei in die passende Java-Klasse gelesen werden können. Danach werden die Daten mit dem PACT abgeglichen. Nebenbemerkung: Wie in Listing 9 zu sehen, liefert der Provider ein weiteres Feld phone, das von dem Grüße-Consumer nicht gelesen wird.
{
"header": {
"action": "create",
"contentType": "application/json",
"event": "PersonChanged",
"kafka_topic": "person",
"providerState": "PersonChanged"
},
"payload": {
"id": 1,
"surname": "Adam",
"forename": "Helena",
"email": "[email protected]",
"birthday": "1984-08-06",
"phone": "+49 1234 56789"
}
}
Der Provider kann nun seine Tests gegen den zentralen PACT Broker laufen lassen und verifiziert so stets die aktuelle, veröffentlichte Version des CDC-Vertrags:
mvn verify -Dpact.provider.version=1.0-SNAPSHOT
-Dpact.verifier.publishResults=trueDas Ergebnis sollte dann in etwa aussehen wie in Abbildung 9.
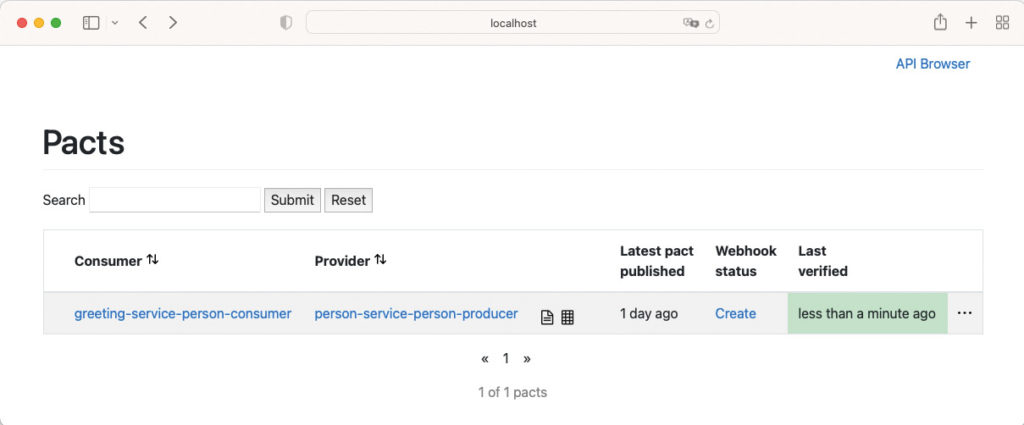
Abb. 9: PACT Broker GUI
Damit haben wir bis hierhin sichergestellt, dass das vom Consumer erwartete Schema des Austauschformats auf Consumer- und Provider-Seite zueinander passen.
Behavior-driven-Development-Test
Das hilft uns aber noch lange nicht beim Ablösen der externen E2E-Tests. Also werfen wir einen Blick darauf, wie wir unsere fachlichen Tests in Angriff nehmen. Im Optimalfall haben wir die Schnittstelle definiert und mit PACT getestet und damit schon ein fertiges Event als Beispiel vorliegen. Das nehmen wir zur Hand und schreiben erst einmal einen Test dafür (Listing 10).
Feature: Birthday Greeting
Scenario: consume person with birthday event and send birthday greeting
Given event PersonChanged with Provider-State PersonWithBirthday
When event is published and consumed
And I could greet the person with the email [email protected]
Then Birthday greeting goes to "Helena Adam"
Mit Hilfe des Cucumber Frameworks [4] definieren wir ein paar einfache Schritte, in denen das Event veröffentlicht und verarbeitet und im Anschluss ein Gruß bei unserem Service angefragt wird. Lösen wir die einzelnen Schritte einmal nacheinander auf: Im ersten Schritt geben wir das Event und den Provider State vor: Given event PersonChanged with Provider-State PersonWithBirthday.
@Given("event {word} with Provider-State {word}")
public void eventWithProviderState(String event, String providerState) throws IOException {
var eventPath = EVENTS_PATH
.resolve(event)
.resolve(providerState + ".json");
var mapper = new ObjectMapper();
var eventJson = mapper.readTree(eventPath.toFile());
payload = eventJson.get("payload");
header = eventJson.get("header");
}
In Listing 11 sehen wir die Logik dahinter. Über die @Given-Annotation registrieren wir unseren Schritt in Cucumber. Durch die zwei Platzhalter {word} holen wir uns die Parameter für unsere Methode: event und providerState. Anhand der Parameter identifizieren wir die JSON-Datei, die wir schon aus Listing 2 kennen. Sie enthält die Payload und die Header für den notwendigen Event. Mit Hilfe des Jackson ObjectMappers lesen wir nun die JSON-Datei ein, um sie anschließend separat als payload und header zu speichern.
Weiter geht es mit When event is published and consumed. Listing 12 zeigt uns, wie wir mit @When den Schritt registrieren und darin das Event an unseren Kafka Broker schicken. Die Methode createKafkaProducer() erstellt uns einen einfachen Kafka Producer, den wir direkt verwenden, um den ProducerRecord abzusenden. Den Value des Records erstellen wir mit JacksonNode.toString(), die Methode getHeader() wandelt die JsonNode header in ein Set mit Kafka-Headern um.
Damit die Nachricht nun von unserem Service verarbeitet werden kann, warten wir 500 Millisekunden. Eine elegantere Variante wäre, anhand von Metriken zu prüfen, wann ein Event verarbeitet wurde.
@When("event is published and consumed")
public void eventIsPublishedAndConsumed() throws InterruptedException {
createKafkaProducer()
.send(
new ProducerRecord<>(
"person", 0, "person", payload.toString(), getHeader()));
Thread.sleep(500);
}
Jetzt sind wir so weit, dass wir mit And I could greet the person with the email [email protected] den Gruß von unserem Service auslesen können.
@And("I could greet the person with the email {word}")
public void greetPersonWithEmail(String email) {
response = given().queryParam("email", email)
.when().get("/greeting").body().prettyPrint();
}
Listing 13 registriert dafür einen weiteren BDD-Schritt mit @And. Um den REST Endpoint aufzurufen, verwenden wir REST-assured und speichern die Rückgabe in response. Schließlich prüfen wir mit dem Schritt Then Birthday greeting goes to “Helena Adam”, ob es sich um einen Geburtstaggruß handelt und ob er an die richtige Person gerichtet wurde. AssertJ wird bemüht, um zu prüfen, ob die >response auch dem Gruß an name entspricht.
@Then("Birthday greeting goes to {string}")
public void birthdayGreetingGoesTo(String name) {
assertThat(response).isEqualTo("Happy Birthday " + name + "!");
}Nun kann mit der Implementierung der Logik begonnen werden, bis der Test auf Grün springt. Damit sind die fachlichen Anforderungen an den Bounded Context Grüße erfüllt und getestet. Ähnlich wird der BDD-Test des Bounded Contexts Personen implementiert.
Das hier dargestellte Beispielprojekt kann auf GitLab zur besseren Nachvollziehbarkeit angesehen werden [6].
Fazit
Durch das Verbinden von CDC und BDD über eine Quelle (Listing 2) haben wir nun die Möglichkeit, die Tests unserer Logik auf Basis von CDC zu erstellen und kontinuierlich zu testen. Wenn sich also nun ein Provider State des PACT dergestalt ändert, dass die Schnittstelle nicht mehr funktionieren würde, merken wir das in unseren Tests. So ist die Integration von Schnittstelle und Logik gesichert und wir können bereits während der Entwicklung sehen, ob eine Schnittstelle später in Produktion fehlerhaft wäre, und dies sofort korrigieren, ohne dabei direkt abhängig von anderen Teams zu sein.
Wenn wir aus CDC-Tests bereits unterschiedliche fachliche Fälle abbilden können, stellt sich die Frage: Wieso brauchen wir BDD-Tests noch? Wieso testen wir die fachliche Logik nicht mit den CDC-Tests direkt? Zum einem: Nicht für alle fachlichen Funktionen sind CDC-Tests notwendig – hierfür werden laut der Testpyramide trotzdem fachliche Black-Box-Tests benötigt. Das bringt uns zu dem Punkt, dass wir fachliche Verhaltenstests (BDD-Tests) auf jeden Fall einsetzen. Zum anderen ist hier eine klare Trennung erreicht. Die fachliche Logik wird mit den BDD-Tests beschrieben (User Stories, Akzeptanzkriterien etc.) und getestet und die Schnittstellen mit den dann sehr schlanken CDC-Tests. Dies erhöht die Wartbarkeit.
Zu beachten ist, dass dieser Ansatz vorerst an den unternehmensinternen Schnittstellen angewendet werden kann. Das PACT Framework bietet für den zentralen Broker noch keine Authentifizierungs- und Autorisierungsfunktionalität. Daher ist an dieser Stelle das vollkommene Vertrauen aller Beteiligten notwendig. Möglich ist es, den PACT Broker hinter einem Reverse-Proxy-Server bereitzustellen und so den Zugang abzusichern. Auch ist es möglich, mehrere PACT Broker in unterschiedlichen Zonen zu betreiben. Über die Parameter kann einem PACT-Test der Ziel-PACT-Broker mitgeteilt werden, sodass damit auch mehrere unterschiedliche PACT Broker in einem Testprojekt möglich wären. So gesehen wäre die Bereitstellung eines dedizierten PACT Brokers für eine externe Schnittstelle ebenfalls möglich. Dieser sollte dann für die beiden Schnittstellenparteien zugänglich gemacht werden.
Letztendlich erreichen wir mit dem Agile-driven Integrationstest eine vollständige Testabdeckung aller Geschäftsfallkonstellationen in der fachlichen Logik und über die Schnittstellen – und das mit den automatisierten Tests, die jedes DevOps-Team für sich selbst implementiert und in der eigenen CD Pipeline ausführen kann.
Der PO dazu: „Wow – in dem Fall müssen wir unser DevOps-Team in der Testkompetenz verstärken, um alle diese Fälle abbilden zu können. Dass wir damit tatsächlich Continuous Delivery umsetzen können, das hätte ich nicht für möglich gehalten – aber es scheint tatsächlich umsetzbar zu sein. Ran an die Arbeit!“
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Links & Literatur
[1] https://pact.io/
[2] https://spring.io/projects/spring-cloud-contract
[3] https://entwickler.de/spring/consumer-driven-contracts-mit-spring-001
[5] https://github.com/karatelabs/karate#readme
[6] https://gitlab.com/sidion/demo/2022/javamagazin/agiledrivenintegrationstests




