Source: Shutterstock
Amazon Web Services hat den Begriff Serverless [1] vor ziemlich genau drei Jahren, im November 2014, auf der Hausmesse re:invent, mit dem Dienst AWS Lambda eingeführt. Mittlerweile kann ich auf rund zwei Jahre Erfahrung mit dem Serverless-Ökosystem in der AWS Cloud zurückblicken. In dieser Zeit konnte ich diese noch sehr junge Technologie sehr erfolgreich einsetzen, habe aber auch die eine oder andere negative Erfahrung gemacht, die mich hat lernen lassen.
Serverless Computing Manifesto
- Functions are the unit of deployment and scaling.
- No machines, VMs, or containers visible in the programming model.
- Permanent storage lives elsewhere.
- Scales per request. Users cannot over- or under-provision capacity.
- Never pay for idle (no cold servers/containers or their costs).
- Implicitly fault-tolerant because functions can run anywhere.
- BYOC – Bring Your Own Code.
- Metrics and logging are a universal right.
Übrigens: das Serverless-Ökosystem besteht für mich nicht nur aus AWS Lamda. Lambda ist der typische Vertreter, wenn es um Function-as-a-Service geht, was nur ein Subset der Serverless-Welt darstellt. Auch Komponenten wie das API-Gateway, Datastorage wie z. B. S3 und DynamoDB, Messaging Services wie SQS und SNS, Streams wie Amazon Kinesis und viele weitere mehr gehören für mich zum Komplettpaket dazu (Abb. 1). Natürlich gibt es außer AWS noch andere Anbieter von Serverless-Diensten, in diesem Artikel beschränke ich mich jedoch ausschließlich auf meine Erfahrungen mit AWS und hier hauptsächlich auf den Dienst AWS Lambda. Die eine oder andere Erfahrung lässt sich aber durchaus ebenso auf andere Umgebungen übertragen.
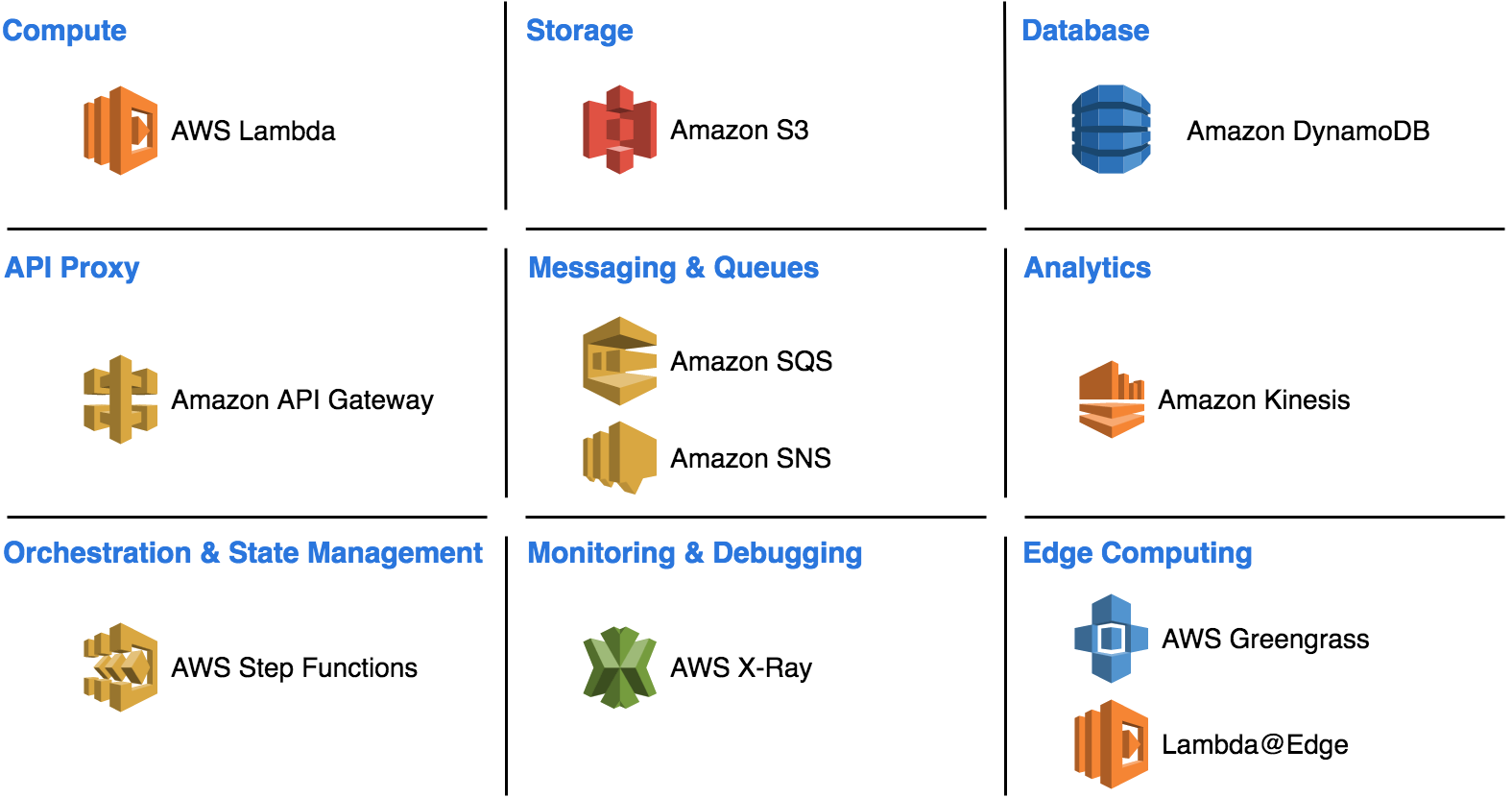
Abb. 1: Serverless-Bausteine in AWS
Anwendungsszenarien
Sehr oft höre ich die Frage, in welchen Szenarien oder wofür man Serverless am besten einsetzen kann. Diese Frage ist gleichermaßen einfach wie auch schwer zu beantworten. Da Serverless keine neue Technologie an sich ist, sondern nur eine weitere Abstraktions-, Virtualisierungs- oder Isolationsebene darstellt, kann damit im Grunde alles gemacht werden, was bislang auf anderen Plattformen ausgeführt wurde.
Ein komplette Webanwendung auf Serverless-Komponenten aufzubauen ist natürlich möglich (Abb. 2). In diesem Kontext wird man statische Ressourcen vielleicht in Amazon S3 ablegen, dynamische Inhalte über AWS Lambda mit DynamoDB verwalten, über das API-Gateway den Lambdafunktionen ein API geben, CloudFront für das CDN (Content Delivery Network) verwenden und die unterschiedlichen AWS-Backend-Domains mit Route 53 einheitlich über einen eigenen Domainnamen publizieren. Das ist kein Problem, wird aber sehr schnell sehr komplex, da viele unterschiedliche Services beteiligt sind und viele einzelne, kleine Ressourcen verwaltet werden müssen. Eine gute und aktuelle(!) Dokumentation der beteiligten Komponenten ist unerlässlich. In der AWS-Welt können die AWS Simple Icons [2] dabei helfen, aussagekräftige Architekturdiagramme zu zeichnen.
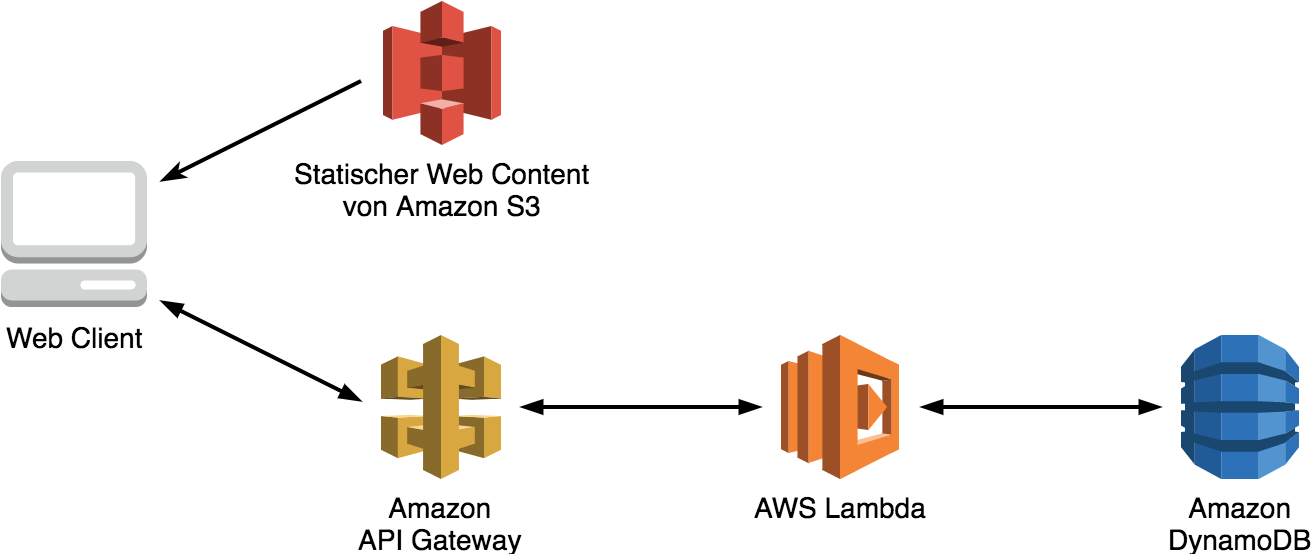
Abb. 2: Serverless-Webarchitektur
Die eigentlichen Stärken von Serverless liegen in der ereignisgetriebenen Verarbeitung von Daten. Ereignisse, die von anderen AWS-Diensten ausgesendet werden (Amazon S3: ein neues Objekt wird abgelegt, verändert oder gelöscht, DynamoDB: Datensätze werden eingefügt, geändert oder gelöscht etc.) oder Daten in Form von Ereignissen, die über AWS-Dienste gesendet werden, wie Nachrichten über SQS Queues oder SNS Topics oder (Echtzeit-)Datenströme (Streams) über Amazon Kinesis (Abb. 3). Die Dienste sind fast allesamt selbst Serverless-Ressourcen und kommunizieren untereinander asynchron über Events, ein typisches Merkmal für verteilte (Micro-)Services. Wenn ein Dienst ein empfangenes Ereignis nicht direkt selbst verarbeiten kann, kann der Entwickler eine Lambdafunktion dazwischenschalten, die die Aufgabe der Datenverarbeitung oder -transformation übernimmt. Auf diese Art ist es sehr einfach, große Datenmengen, die z. B. über Kinesis empfangen werden, in kleinen Batches von beispielsweise 100 Events jeweils von Lambdafunktionen zu verarbeiten und dann in einem anderen Dienst zu persistieren. Auch die MapReduce- Verarbeitung von bereits bestehenden (Massen-)Daten, etwas aus Amazon S3, ist für Serverless ein geeigneter Use Case (Abb. 4).
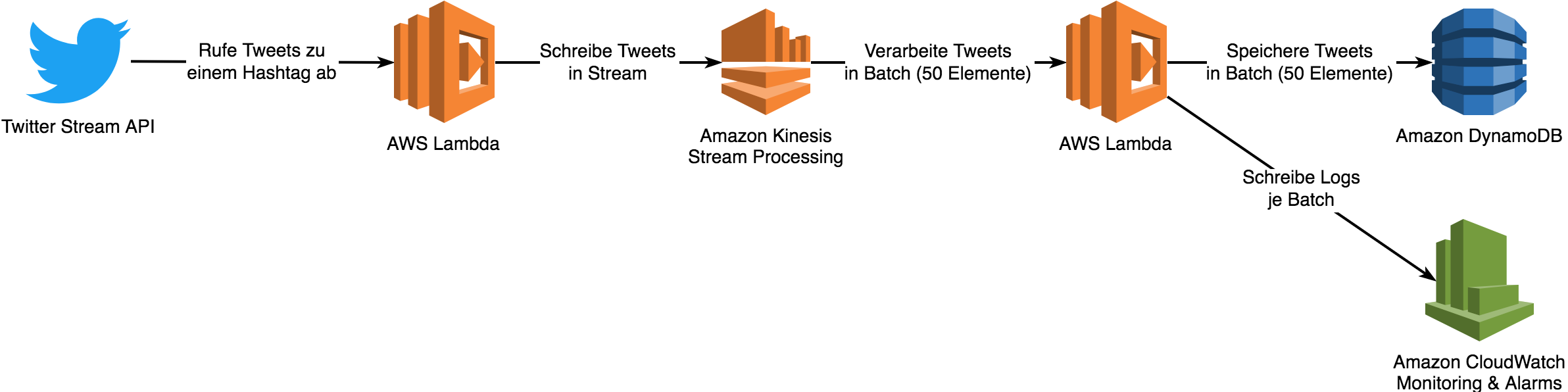
Abb. 3: Serverless-Processing mit Serverless-Komponenten
Wenn Serverless nichts anderes ist als eine weitere Abstraktionsschicht auf vorhandenen Ressourcen oder Plattformen, kann man schnell zu der Aussage kommen, dass Serverless nichts anderes als Platform as a Service (PaaS) ist. Das ist grundsätzlich nicht falsch. Serverless basiert letztendlich auf einer vom Cloud-Anbieter verwalteten und als Dienst angebotenen Plattform, ist als logische Evolution von Paas zu sehen und damit eine spezielle Form dieser Umgebung. Zwischen einer klassischen PaaS und Serverless gibt es vor allem zwei Unterschiede: Einerseits sind in der Serverless-Welt die Artefakte und Ressourcen, die in Betrieb gebracht werden, deutlich kleiner. Es werden beispielsweise keine ganzen Anwendungen oder Container mehr deployt, sondern nur noch einzelne Ressourcen in der Größe einer Funktion. Oder es wird kein komplettes Messaging-System betrieben, sondern es werden nur einzelne Queues genutzt, die bereits als Dienst vorhanden sind. Andererseits muss sich der Entwickler bei einer PaaS um die Grenzen der Verfügbarkeit und Skalierung noch selbst kümmern. Er muss sie einstellen, überwachen und gegebenenfalls anpassen. Bei Serverless passiert dies implizit mit dem anfallenden Request-Aufkommen. Eine Über- und Unterprovisionierung der Umgebung ist somit keine Gefahr mehr, da nur die Ressourcen allokiert werden, die wirklich benötigt werden. Gleichzeitig basiert hierauf auch das Abrechnungsmodell: Es wird nur das bezahlt, was wirklich verwendet wurde. Leerlaufzeiten eines Systems, einer ganzen Plattform werden nicht abgerechnet.
Natürlich muss sich irgendjemand um diese Umgebung, um diese Plattform kümmern. Das können (und sollten) wir bei Serverless aber denjenigen überlassen, die das können und sich ausschließlich um die kosteneffiziente Bereitstellung solcher Services kümmern: den Serverless-Cloud-Anbietern. Der Aufwand, eine auch nur annähernd ähnliche Umgebung On-Premise, also bei sich selbst im eigenen Rechenzentrum, aufzubauen, sollte nicht unterschätzt werden. Nur weil man einen Kubernetes-Cluster [3] auf ein paar (begrenzten) Maschinen betreibt, hat man noch keine private Cloud im eigenen Rechenzentrum. Da gehört mehr dazu.
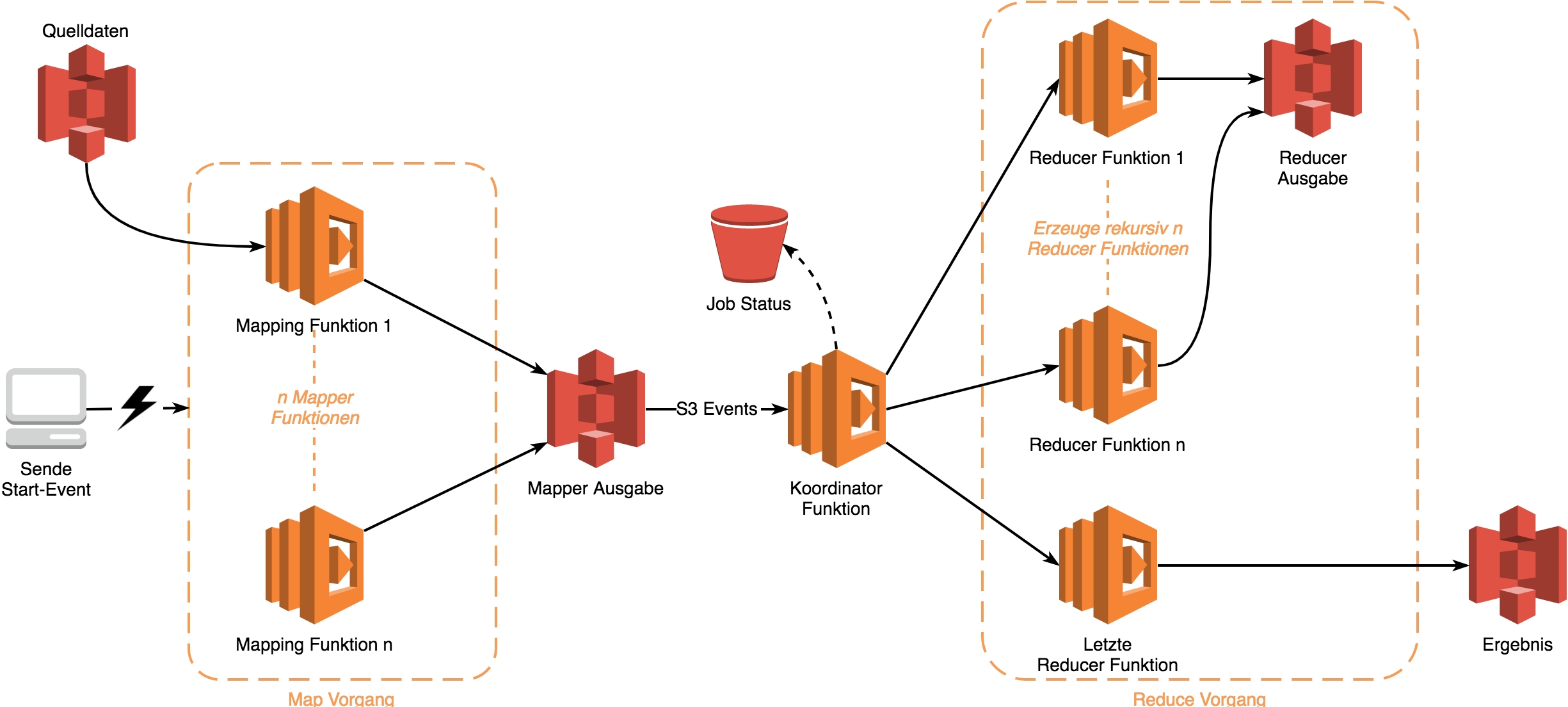
Abb. 4: Serverless-MapReduce-Architektur
Programmiermodell
Die Ablaufumgebung – ein Container – einer Lambdafunktion ist flüchtig. Nachdem eine Funktion ausgeführt wurde, ist deren Umgebung nicht mehr vorhanden. Das stimmt natürlich nur zur Hälfte, da AWS den Container für eine eventuelle erneute Ausführung der Funktion im Cache behält. Dieses Caching ist allerdings nicht definiert und es kann sein, dass der Container innerhalb weniger Minuten komplett gelöscht wird oder aber über eine längere Zeit „lebt“. Diese Steuerung des Cache ist einerseits davon abhängig, wie oft die Funktion generell aufgerufen wird (wenn AWS feststellt, dass die Funktion häufig verwendet wird, wird sie potenziell länger gecacht). Andererseits spielt die Auslastung der Availability Zone (AZ, entspricht bei AWS einem autarken Rechenzentrum), in der der Container existiert, eine Rolle. Einer Lambdafunktion kann man nämlich nur die Region (bei AWS den physischen Standort der AZs) angeben, in der sie ausgeführt werden soll. AWS entscheidet dann selbstständig, in welcher AZ die Funktion letztendlich gestartet wird. Somit kann AWS eine gleichmäßigere Lastverteilung über alle in einer Region verfügbaren AZs erreichen.
Mit diesem Caching kann der Entwickler im Programming Model also arbeiten, er darf sich nur nicht darauf verlassen. So werden beispielsweise alle erzeugten und instanziierten Objekte in einem Funktionsartefakt ebenfalls gecacht, wenn der gesamte Container zwischengespeichert wird. Einzig die direkt durch Lambda aufgerufene Handler-Funktion (in Java-Umgebungen die aufgerufene Methode) wird verworfen und bei einer erneuten Ausführung der Funktion neu durchlaufen. Objekte sollten für eine Wiederverwendung also immer außerhalb der eigentlichen Handler-Funktion gespeichert werden (z. B. als Instanzvariablen) und nie ohne Überprüfung, ob schon eine Instanz des Objekts existiert, erzeugt werden. Möglicherweise existiert das Objekt bereits und lässt sich wiederverwenden. Das spart eine nicht unerhebliche Menge an Zeit bei der Ausführung des Funktionscodes.
In AWS Lambda ist es möglich, eigene Prozesse in der Ablaufumgebung zu starten. Man sollte aber darauf achten, dass diese Prozesse beendet werden, bevor die Handler-Methode beendet ist. Werden die Prozesse asynchron aufgerufen, ist das eine nicht ganz triviale Sache. Der Hintergrund ist der, dass durch die Funktion erzeugte Prozesse, die bei der Beendigung der Funktion selbst noch nicht beendet sind, ebenfalls gestoppt werden. Wird der Container nun gecacht und kommt es zu einer Wiederverwendung dieses Containers, läuft der vormals gestartete Prozess an genau dem Punkt weiter, an dem er pausiert wurde, bevor der Container in den Ruhezustand ging. Das kann zu unvorhergesehenen und unerwünschten Nebenwirkungen und Seiteneffekten führen. Hier also besser aufpassen, falls jemand mit selbst gestarteten Prozessen hantiert.
In Node.js- und JavaScript-Funktionen werden die für die asynchrone Ausführung auf den Callstack gelegten Callback-Funktionen jedoch noch alle ausgeführt, bevor der Container gestoppt wird, auch wenn die eigentliche Handler-Funktion bereits abgearbeitet ist. Dieses Verhalten lässt sich im Context-Objekt der Funktion mit der Property callbackWaitsForEmptyEventLoop beeinflussen. Per Default steht das Property auf true, kann aber auf Wunsch auf false gesetzt werden. Dann verhält sich die Callback-Loop so, dass die asynchronen Funktionen, die zum Zeitpunkt der Beendigung der Handler-Funktion noch nicht ausgeführt wurden, erst beim nächsten Aufruf des Containers zur Ausführung kommen. Auch hier sind unerwünschte Seiteneffekte möglich!
Der Clouds, Container & Serverless Track auf der W-JAX 2018
Fehlerbehandlung und Debugging
Wie oben geschrieben, liegt die eigentliche Stärke von Serverless in der Bearbeitung von Daten(-strömen). Funktionen, die in solchen Pipelines verwendet werden, werden fast ausschließlich asynchron aufgerufen. AWS Lambda hat die Eigenschaft, dass asynchrone Funktionen im Fehlerfall, egal welche Ursache, falls nicht anders konfiguriert, bis zu zwei Mal mit zeitlichem Abstand wiederholt werden. Kann die Funktion auch nach den Wiederholungen nicht erfolgreich ausgeführt werden, wird sie verworfen, mitsamt dem aufrufenden Ereignis, das die zu verarbeitenden Daten enthält. Damit existiert erst einmal keine Nachvollziehbarkeit des Fehlers und die Daten sind gegebenenfalls unwiederbringlich verloren. Abhilfe schafft hier die Verwendung von Dead Letter Queues (DLQ). Jeder Lambdafunktion kann eine DLQ für den Fehlerfall zugewiesen werden. Die DLQ kann entweder eine SQS Queue oder ein SNS Topic sein. Ereignisse (und die in den Events enthaltenen Daten), die zu einer fehlerhaften Ausführung der Funktion geführt haben, werden nach allen erfolglosen Versuchen inklusive der Fehlerinformation von Lambda in die angegebene DLQ gesendet. Auf diese Nachrichten kann dann wieder reagiert werden. Entweder verarbeitet eine andere Lambdafunktion die Fehler-Events automatisch (wenn möglich), oder die Events werden automatisch per E-Mail verschickt. Hier sind viele Varianten möglich, auch dass ein Admin sich die Fehler-Events manuell abruft und entscheidet, was damit geschehen soll. Hauptsache, die Ereignisse gehen nicht verloren und können für eine nachgelagerte Verarbeitung genutzt werden.
Erfolgreiche Unterstützung bei der Fehlersuche und beim Debugging von AWS-Komponenten bietet der Dienst AWS X-Ray. Er zeichnet alle Requests auf, die durch entsprechend aktivierte Ressourcen aufgerufen werden bzw. diese durchlaufen. Ein Request oder Event lässt sich dabei von Anfang bis Ende durch alle beteiligten Ressourcen hindurch verfolgen. Die genaue Fehlerlokation wird ebenfalls entsprechend grafisch und farbig dargestellt. Wichtig zu wissen ist, dass X-Ray primär für die Echtzeitdarstellung der Request Flows gedacht ist und aktuell nur Daten bis sechs Stunden in die Vergangenheit speichert und darstellen kann. Wer ältere Fehler analysieren möchte, muss sich eine andere Lösung einfallen lassen.
Latenzen
Latenzen, speziell Start-up-Latenzen von Lambdafunktionen, sind immer wieder Gegenstand vieler Diskussionen. Es wird dabei gerne behauptet, dass sich Serverless-Funktionen ja nicht produktiv einsetzen ließen, da die hierbei anfallenden Latenzen kontraproduktiv seien. Dem ist aber nicht so. Werfen wir einen Blick auf den bereits mehrfach angesprochenen Einsatzzweck für eine asynchrone Datenverarbeitung, so spielen geringe Latenzen nur eine untergeordnete Rolle, da kein Anwender auf das Ergebnis direkt wartet. Die Berechnungen werden in einem anderen Dienst abgelegt und dort zur Ausgabe oder Anzeige aufbereitet. Ob dies nun ein paar Sekunden früher oder später geschieht, ist unerheblich.
Ist eine Lambdafunktion bereits einmal ausgeführt worden, wird der Container für eine Wiederverwendung gecacht. Kommt es nun zu einer erneuten Verwendung des bereits bestehenden, nur pausierten Containers, steht dieser deutlich schneller für die Funktionsausführung zur Verfügung, da er ja nicht mehr erzeugt werden muss und eine möglicherweise benötigte JVM-Instanz bereits gestartet ist. Ebenso müssen die darin befindlichen Objekte, wenn richtig implementiert, nicht neu instanziiert werden und lassen sich wiederverwenden.
Wird eine Lambdafunktion also häufig verwendet, sind die Start-up-Latenzen, die lediglich beim initialen Ausführen und Erzeugen von Container- und Programmobjekten auftreten, im Verhältnis zu den übrigen Ausführungen deutlich in der Unterzahl und damit im Gesamtkontext zu vernachlässigen. Es gibt eine Stellschraube für Lambdafunktionen, mit der Latenzen und andere zeitkritische Parameter beeinflusst werden können. Dies ist der für die Funktion zur Verfügung stehende Arbeitsspeicher. Mit der Angabe des Speichers verändert sich nämlich nicht nur dieser, sondern auch die zur Verfügung stehende CPU-Rechenleistung und die Netzwerkbandbreite. Mehr Speicher heißt auch mehr von den anderen Ressourcen. Damit kann eine Funktion, die mehr Speicher und damit mehr CPU-Leistung zugewiesen bekommt, ihren Programmcode schneller initiieren und steht früher für die eigentliche Verarbeitung des Events zur Verfügung. Die Start-up-Latenz verringert sich. Auch wenn die Funktion selbst eigentlich nicht viel Arbeitsspeicher benötigt, kann es sinnvoll sein, diesen nach oben anzupassen, um eben von einer geringeren Latenz zu profitieren. Das wirkt sich direkt auf die anfallenden Kosten aus. Die Rechenzeit wird in GB-Sekunden abgerechnet. Weist man einer Funktion einen Arbeitsspeicher von 512 MB zu und diese wird 1 Sekunde lang ausgeführt, so hat man 0,5 GB-Sekunden Rechenzeit verbraucht.
Ein Rechenbeispiel: eine Funktion hat 256 MB Arbeitsspeicher zugewiesen und benötigt regelmäßig etwa vier Sekunden Ausführungszeit. Dies ergibt eine Rechenzeit von 1 GB-Sekunde. Kann nun durch eine Veränderung des Arbeitsspeichers auf 512 MB die regelmäßige Ausführungszeit auf eine Sekunde reduziert werden, so werden nur noch 0,5 GB-Sekunden Rechenzeit benötigt und damit nur diese abgerechnet. Obwohl also mehr Arbeitsspeicher zugewiesen wurde und die Kosten des Lambdaservice sich vordergründig am Arbeitsspeicher orientieren, ist die in Rechnung gestellte Rechenzeit letztendlich geringer. Damit ist es letztendlich günstiger, als weniger Arbeitsspeicher zuzuweisen. Ein Parameter, an dem es sich lohnt, länger zu experimentieren, verschiedene Einstellungen gegenüberzustellen und zu vergleichen. Bei entsprechend vielen Funktionsaufrufen und summierter Rechenzeit kann sich das im Monat schon mal lohnen. Hilfe bietet hier ein spezieller Serverless-Rechner [4].
Eine offizielle Empfehlung von AWS ist übrigens, dass Lambdacontainer mit zeitgesteuerten Events (Cron-Events) aus dem CloudWatch-Dienst warmgehalten werden können, wenn diese regelmäßig, beispielsweise alle fünf Minuten, ein Keep Alive Event gesendet bekommen. Funktionen, die nur selten aufgerufen werden, aber eine hohe Start-up-Latenz haben, können damit im Cache gehalten und die Latenz kann verringert werden. Gerade bei synchron aufgerufenen Funktionen, etwa über das API-Gateway, macht sich das positiv bemerkbar. Auch mit öfter aufgerufenen, dadurch aber insgesamt weniger Rechenzeit verbrauchenden Funktionen (weil weniger initiale Start-up-Zeiten) und gegebenenfalls weniger Speicher benötigenden Funktionen können letztendlich Kosten gespart werden. Auch wenn es auf den ersten Blick nicht so und zudem merkwürdig erscheint.
Nicht nur Java-basierte Funktionen haben eine bemerkenswerte Start-up-Latenz, auch Funktionen, die auf Node.js (JavaScript) basieren, können beim ersten Start durchaus ein bis drei Sekunden brauchen, bis sie an die eigentliche Funktionsausführung kommen, je nach Implementierung und Umfang der mit deployten Bibliotheken. Generell ist eine skriptbasierte Sprache schneller in der ersten, initialen Ausführung als kompilierter Java-Code, der eine JVM-Umgebung benötigt. Python ist ebenfalls eine interpretierte Skriptsprache und gewinnt gerade in der Datenverbeitung von IoT oder Machine-Learning-(ML-)Anwendungen wieder zunehmend an Popularität. Die Sprache Go [5] stellt eine interessante Alternative für Funktionen dar, ist sie doch statisch getypt und liegt als kompilierter Bytecode vor, benötigt aber so gut wie keine Start-up-Zeit durch eine VM o. ä. Go steht derzeit (Mitte November 2017) aber noch nicht direkt als Ablaufumgebung für AWS-Lambda-Funktionen zur Verfügung.
Grenzen
Auch wenn der Begriff Serverless impliziert, dass alles ohne Server läuft und damit vielleicht grenzenlos erscheint, gibt es durchaus wichtige Grenzen im Serverless-Universum, die Entwickler kennen sollten. Je nach Dienst können es sehr viele, granulare Grenzen sein, die einem erfolgreichen Einsatz von Serverless Computing zunächst im Wege stehen können. So ist z. B. bei Lambda der Default-Timeout für eine Funktion auf drei Sekunden eingestellt. Passt der Entwickler ihn nicht an, kann es durchaus passieren, dass eine Funktion gar nicht zur eigentlichen Ausführung kommt. Der Timeout schlägt vor der Codeausführung zu und die Funktion weist eine hohe Start-up-Latenz auf. Gleichzeitig kann eine Lambdafunktion aber maximal fünf Minuten lang laufen, danach wird sie von AWS hart terminiert. Lambda eignet sich also nicht für langlaufende Batch-Verarbeitungen, hierfür gibt es den Dienst AWS Batch (der nicht zu den Serverless-Diensten zählt).
Ganze Applikationskontexte, wie eine Java-EE- oder Spring-Anwendung, sind nicht wirklich sinnvoll mit AWS Lambda zu betreiben (wenngleich möglich [6], [7]). Die (auch bei hoher Speicherallokation) benötigte Start-up-Zeit steht nicht im Verhältnis dazu, dass der Container nach fünf Minuten wieder abgebrochen wird. Es gibt durchaus Unternehmen, bei denen schlägt die Grenze von 1 000 gleichzeitig ausführbaren Lambdafunktionen zu. Wenn man eine große Serverless-Landschaft betreibt und gleichzeitig in dem jeweils selben AWS-Account Produktions-, Test- wie auch Entwicklungsumgebung hat, kann das schon mal vorkommen. Diese Grenze ist allerdings nur eine Vorgabegrenze und lässt sich über den AWS-Support erweitern. Funktionen, die direkt mit einem Ereignis aufgerufen werden und durch die maximale Anzahl an gleichzeitigen Lambdafunktionen nicht ausgeführt werden können, werden abgebrochen und als fehlerhafter Aufruf gezählt. Das initiierende Ereignis wird nicht für eine spätere Ausführung aufbewahrt. Hierfür muss der Entwickler selbst sorgen. Das kann beispielsweise dadurch geschehen, dass Lambdafunktionen nicht direkt von Ereignissen anderer Dienste aufgerufen werden, sondern alle Events zuvor ein eine SQS-Queue geschrieben und damit dann Lambdafunktionen aufgerufen werden. Der Lambdadienst startet dann maximal 1 000 Funktionen gleichzeitig, und die nicht gleichzeitig zu verarbeitenden Ereignisse verbleiben in der Queue bis zu ihrer Verarbeitung. Auf diese Weise gehen keine Daten verloren.
Free: Mehr als 40 Seiten Java-Wissen

Lesen Sie 12 Artikel zu Java Enterprise, Software-Architektur und Docker und lernen Sie von W-JAX-Speakern wie Uwe Friedrichsen, Manfred Steyer und Roland Huß.
Sicherheit
Alle Lambdafunktionen laufen im Standard in einer eigenen VPC (Virtual Private Cloud [8]), so etwas wie ein eigenes Netzwerk. In dieser VPC sind Verbindungen zu öffentlichen Adressen im Internet über HTTP offen, es gibt keine Beschränkungen für einzelne Hosts. Von außen kann nicht auf diese VPCs zugegriffen werden, hierfür ist kein Port verfügbar. Zudem ist ein Angriff von außen schon deswegen schwierig, da die Funktion und der Container selbst ja nur dann aktiv sind, wenn gerade ein Ereignis verarbeitet wird, also kein dauerhafter Zugriff möglich ist. Weiterhin ist der dedizierte Host, auf dem der Container betrieben wird, nach außen nicht bekannt und kann von Ausführung zu Ausführung unterschiedlich sein.
Soll die Lambdafunktion auf Ressourcen innerhalb eigener VPCs zugreifen können, so kann der Entwickler die entsprechende VPC der Funktion zuweisen. Allerdings muss er dann bedenken, dass ein Zugriff auf andere Funktionen als in der dann verwendeten VPC nicht mehr möglich ist. Lässt die eigene VPC beispielsweise keinen Zugriff auf öffentliche Adressbereiche zu, wird auch die Lambdafunktion nicht darauf zugreifen können. Das kann gerade in Bezug auf die Nutzung von anderen (öffentlichen) AWS APIs (z. B. für DynamoDB, SNS, SQS etc.) problematisch werden. Diese Dienste haben ja öffentliche API-Endpunkte. Abhilfe kann hier ein NAT-Routing in der verwendeten VPC schaffen, sodass eine Lambdafunktion darüber auf öffentliche Endpunkte zugreifen kann.
Wird ein API-Gateway verwendet, ist natürlich hier auf die entsprechend sichere Konfiguration zu achten. So lassen sich etwa die Gesamtzugriffe pro Sekunde begrenzen, um die Auswirkungen von potenziellen Denial-of-Service-Attacken (DoS) zu minimieren. Falls eine Authentifizierung und Autorisierung notwendig sind, müssen diese mit geeigneten Mitteln konfiguriert oder implementiert werden. Im Amazon API Gateway steht hierfür eine Authentifizierung gegenüber dem AWS-internen IAM (Identity & Access Management) und selbst zu definierenden Userpools mit Amazon Cognito [8] zur Verfügung. Wem das nicht ausreicht, der kann eine Lambdafunktion als Custom Authorizer in das API-Gateway einhängen. Wie ein Custom Authorizer für die Überprüfung eines JSON Web Tokens aussieht, zeigt der jwtAuthorizr [9].
Ebenso kann die Steuerung von Zugriffen auf das API über API-Keys und -Kontingente vor unberechtigten oder überzähligen Aufrufen auf das öffentliche API schützen. Dabei ist es möglich, unterschiedliche Kontingente auf verschiedene API-Keys zu verteilen, sodass z. B. jeder Kunde bzw. Nutzer des APIs nur die Aufrufe durchführen darf, für die er bezahlt hat. Kontingente sind einstellbar auf Zugriffe pro Sekunde (für eine Begrenzung der gleichzeitigen Aufrufe) und eine Gesamtanzahl an Aufrufen pro Tag, Woche oder Monat.
Testen
Funktionen sind sehr einfach zu testende Einheiten, in Form von Unit-Tests also unproblematisch zu handhaben. Externe Abhängigkeiten und APIs werden entsprechend gemockt, und der Code kann auf korrekte Funktionalität getestet werden. Sobald man aber an Integrationstests kommt und in seiner Funktion auf Cloud-Ressourcen und -Dienste zugreift, muss man diese Ressourcen direkt ansprechen. Das kann zu Latenzen durch Netzwerklaufzeiten führen und zudem die Kosten für die Cloud-Ressourcen beeinflussen. Schließlich werden diese Ressourcen ja genutzt. Nur weil es sich hierbei um Tests handelt, rechnet AWS nicht nichts ab. Man kann aber auch eine Lösung finden, die die Cloud-APIs in der eigenen, lokalen Umgebung offline zur Verfügung stellt. Diese kann beispielsweise LocalStack [10] sein, das fast das komplette AWS-API in einer Docker-Umgebung für eine lokale Offlinenutzung mockt. AWS hat mit AWS SAM Local [11] eine ähnliche, jedoch etwas eingeschränktere Möglichkeit im Portfolio.
Fazit
Serverless Computing bringt zwar keine neue, eigenständige Technologie mit, verlangt jedoch ein eigenes Verständnis für den Umgang mit Cloud-Ressourcen. Wer einfach so weitermacht wie bisher und seine Anwendung einfach nur woanders hin deployen möchte, um Geld in der Cloud zu sparen, wird schnell enttäuscht werden und wahrscheinlich letztendlich sogar auf höheren Kosten sitzen bleiben. Serverless Computing stellt eine sehr evolutionäre Form des Cloud-Computings dar. Der Entwickler kann damit sehr effizient und gleichermaßen effektiv hochskalierbare, elastische und flexible Anwendungen der unterschiedlichsten Art realisieren. Er muss sich nur darauf einlassen. Auch auf den potenziellen Lock-in des Cloud-Anbieters. Wo gibt es heute noch eine wirkliche Anbieterunabhängigkeit? Selbst ein Kubernetes-Cluster bringt den Lock-in auf Kubernetes. Man ist zwar unabhängig von einem Cloud-Anbieter, aber auf Kubernetes angewiesen. Möglicherweise hat man Angst vor steigenden und dadurch möglicherweise explodierenden Kosten, da der Cloud-Anbieter durch diese Abhängigkeit seine Preise erhöhen könnte. Fakt ist aber, dass die großen Cloud-Anbieter ihre Kosten in den letzten Jahren ausschließlich gesenkt haben, nicht erhöht.
Serverless ist die logische Evolution von Virtualisierung und Containern und wird in Zukunft eine große Rolle spielen. Dennoch wird Serverless nicht, wie auch alle anderen Technologien und Paradigmen zuvor, die Silver Bullet für alle unsere Probleme werden. „Use the right tool for the right job“ wird es auch hier heißen. Serverless ist ein weiteres Werkzeug im Portfolio des heutigen Entwicklers. Aber je mehr Werkzeuge wir haben, desto besser können wir arbeiten. Die Zeit, in der wir nur den Hammer verwenden mussten, ist längst vorbei.
Links & Literatur
[1] Serverless: https://aws.amazon.com/serverless/
[2] AWS Simple Icons: https://aws.amazon.com/architecture/icons/
[3] Kubernetes: https://kubernetes.io/
[4] Serverless-Rechner: http://serverlesscalc.com
[5] Spring-Anwendungen mit AWS Lambda: https://github.com/serverlessbuch/lambda-spring
[6] Java-EE-Anwendungen mit AWS Lambda: https://github.com/serverlessbuch/lambda-jaxrs-cdi
[7] Virtual Private Cloud: https://aws.amazon.com/vpc/
[8] Amazon Cognito: https://aws.amazon.com/cognito/
[9] jwtAuthorizr: https://github.com/serverlessbuch/jwtAuthorizr
[10] Localstack: https://localstack.cloud/
[11] AWS SAM Local: https://github.com/awslabs/aws-sam-local
Erfahren Sie mehr über Serverless auf der W-JAX 2018:
● Container vs. Serverless – the Good, the Bad and the Ugly
● Kubernetes Patterns





