
Obwohl der Begriff DevOps bereits 2009 geprägt wurde und seitdem in der IT-Industrie weit verbreitet ist, existieren in Diskussionen, Posts und Vorträgen sehr unterschiedliche Interpretationen davon. Da es keine offizielle Definition von DevOps gibt, ist es müßig, über Begriff und Interpretation zu streiten.
Welches Problem versucht DevOps eigentlich zu lösen? Der Begriff setzt sich aus „Development“ (Entwicklung) und „Operations“ (Betrieb) zusammen [1]. Traditionell sind diese Phasen in der Softwareentwicklung klar voneinander getrennt. Meist gibt es dafür voneinander abgegrenzte Zuständigkeiten, die auch durch unterschiedliche Unternehmensabteilungen repräsentiert werden. Die ursprüngliche Idee von DevOps bestand darin, diese Silos aufzubrechen und eine engere Zusammenarbeit zwischen Entwicklung und Betrieb zu fördern.
Mittlerweile hat sich das Verständnis von DevOps und der damit verbundenen Prinzipien erweitert. Es geht heute um eine ganzheitliche Betrachtung des Softwareentwicklungsprozesses – von der ersten Anforderungsdefinition über Entwicklung, Test und Qualitätssicherung bis hin zum operativen Betrieb der Applikation. Dabei sollen alle relevanten Bereiche berücksichtigt werden. So ergeben sich auch neue Wortschöpfungen wie BizDevOps oder DevSecOps, die ausdrücken sollen, dass nicht nur Development und Operations relevant für ein erfolgreiches Softwareprodukt sind, sondern auch Business- und Securityaspekte.
Stay tuned
Regelmäßig News zur Konferenz und der Java-Community erhalten
Im Gegensatz zu anderen Methoden versucht DevOps nicht, einzelne Aspekte der Softwareentwicklung wie Qualitätssicherung, Aufgabenorganisation, Wertschöpfung, Effizienzsteigerung o. Ä. zu verbessern. Vielmehr zielt DevOps darauf ab, den gesamten Ablauf als vernetzten Wertstrom zu verstehen. Dabei werden systemische Schwachstellen aufgedeckt und Optimierungsbemühungen dort fokussiert, wo sie den größten Einfluss auf den Gesamtprozess haben. Auf diese Weise verspricht das Konzept nicht nur bessere Softwareergebnisse, sondern auch eine nachhaltige Steigerung der Wertschöpfung. Die Effektivität dieses ganzheitlichen Ansatzes ist mittlerweile durch zahlreiche Studien belegt [2], [3], [4]. In diesem Artikel betrachten wir auch die dabei auftretenden Herausforderungen. Zusammengefasst verfolgt DevOps das Ziel, den Beitrag der Softwareentwicklung zum Unternehmenserfolg zu verbessern.
DevOps 3 Ways
Mit den „3 Ways“ hat Gene Kim in seinem 2013 erschienenen Buch „The Phoenix Project“ [5] ein Konzept vorgestellt, das den umfassenden Anspruch von DevOps auf drei konkrete Prinzipien herunterbricht. Diese drei Wege veranschaulichen die Philosophie hinter DevOps und zeigen, worauf sich Organisationen konzentrieren sollten, um die mit DevOps verbundenen Ziele zu erreichen.
- First Way – Flow/Systems Thinking: Der erste Weg beschreibt das Bestreben, möglichst schnell, reibungslos und verlässlich von einer Geschäftsanforderung bis zur aktiven Nutzung durch den Anwender zu gelangen. Dazu ist eine ganzheitliche Betrachtung des gesamten Wertstroms erforderlich.
- Second Way – Amplify Feedback Loops: Empirisches Arbeiten bedeutet, Entscheidungen auf Basis von Beobachtungen und Daten zu treffen. Dafür müssen Feedbackschleifen so früh und so aussagekräftig wie möglich sein, um bei Bedarf rasch gegensteuern zu können. Der zweite Weg fokussiert daher auf den gezielten Ausbau und die Optimierung von Feedbackschleifen.
- Third Way – Culture of Continual Experimentation and Learning: Die stetige Verbesserung erfordert eine Kultur, die nicht nur neue Erkenntnisse wertschätzt, sondern die Menschen aktiv ermutigt, kalkulierte Risiken einzugehen, neue Lösungsansätze auszuprobieren und aus Fehlern zu lernen. Diese Kultur legt die Grundlage für eine Professionalisierung der gesamten Softwareentwicklung.
Nach diesem Überblick vertiefen wir im Folgenden den ersten Weg und untermauern ihn mit Praxisbeispielen.
Der erste Weg: Flow optimieren, Time to Market verkürzen
Der erste Weg in DevOps fokussiert auf einen schnellen, reibungslosen Fluss („Flow“) von der Anforderung bis zum produktiven Betrieb beim Anwender (Abb. 1). Ziel ist es, die Time to Market drastisch zu verkürzen und gleichzeitig Qualität und Zuverlässigkeit zu steigern. Um das zu erreichen, muss der gesamte Wertstrom über alle Zuständigkeitsgrenzen hinweg betrachtet werden. Lokale Optimierungen an den einzelnen Stationen des Wertstroms wie beispielsweise Implementierung oder Qualitätssicherung reichen dafür nicht aus.
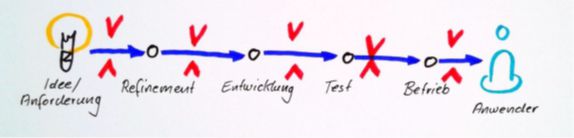
Abb. 1: Stationen von der Anforderung bis zum produktiven Betrieb
Neben der Reduktion der Time to Market ergeben sich noch viele weitere Vorteile, die im Folgenden näher erläutert werden. Zunächst wollen wir aber erörtern, was mit „Optimierung des Flusses“ eigentlich gemeint ist.
Um den Arbeitsfluss zu optimieren, stehen eine Reihe teils wissenschaftlich bestätigter Strategien zur Verfügung. Viele darunter stammen ursprünglich aus der klassischen Produktion, beispielsweise aus der Theory of Constraints [6], dem Toyota Production System [7] oder dem Lean Manufacturing. Immer wieder wird eingewendet, Softwareentwicklung sei „Entwicklung“ und keine „Produktion“, sodass sich der Vergleich verbiete. Der Autor vertritt jedoch eher den Standpunkt, dass durchaus auch Konzepte aus ganz anderen Domänen als Inspiration genutzt werden können, solange diese Konzepte nicht stupide eins zu eins übertragen werden.
Verschiedene namhafte Expertinnen und Experten wie Nicole Forsgren haben in ihren Forschungen nachgewiesen, dass Softwareorganisationen, die Prinzipien aus der Lean-Philosophie übernehmen, signifikant bessere Ergebnisse erzielen. Eine Optimierung des Flows führt häufig zu grundlegenden Paradigmenwechseln und wirkt daher mitunter kontraintuitiv. Wie im weiteren Verlauf noch deutlich wird, können klassische Optimierungsziele – etwa die Maximierung der Auslastung, eine isolierte Steigerung der Effizienz oder entsprechend fokussierte Erfolgskennzahlen – den Fluss sogar behindern. Umso wichtiger ist es, diesen Themen mit Offenheit und der Bereitschaft zu begegnen, eingefahrene Denk- und Handlungsmuster zu hinterfragen und gegebenenfalls über Bord zu werfen.
Bottlenecks identifizieren, um Optimierungen zu fokussieren
Eliyahu Goldratt, der Begründer der „Theory of Constraints“ geht davon aus, dass in einem komplexen System stets genau ein Engpass den Gesamtdurchsatz bestimmt. Goldratt formuliert: „In any value stream, there is always one and only one constraint; any improvement not made at that constraint is an illusion.“ Das heißt: In einem komplexen System bestimmt stets genau ein Engpass den Gesamtdurchsatz. Die Identifikation dieses Engpasses im System muss deshalb der erste Schritt zur Verbesserung des Flows sein. Gemäß der Theory of Contraints wird nur eine Verbesserung am Engpass zu einer Verbesserung des Durchflusses durch das Gesamtsystem führen. Damit gibt der Bottleneck vor, wo Optimierungen fokussiert werden sollten. Da das System aber nicht statisch ist und sich ja vor allem durch Optimierungen verändert, sind auch die Engpässe nicht dauerhaft an derselben Stelle.
Das Suchen nach Engpässen ist also eine kontinuierliche Aufgabe, die niemals abgeschlossen sein wird. Übertragen auf die Softwareentwicklung bedeutet das, dass es nicht vorrangig darum gehen sollte, Anforderungen noch effizienter zu verwalten, Code schneller zu schreiben oder Tests durch Automatisierung weiter zu beschleunigen. Entscheidend ist vielmehr, ob neue Funktionen zügig und kontinuierlich beim Anwender ankommen.
Werden beispielsweise Features aufgrund langer Releasezyklen auf Halde gelegt und erst Monate später an den Anwender ausgeliefert, entsteht eine hohe Verweildauer im System – mit all ihren negativen Auswirkungen. In solchen Situationen gilt es daher vorrangig, organisatorische und technische Voraussetzungen zu schaffen, die häufigere Releases neuer Softwareversionen ermöglichen.
Work in Progress (WIP) begrenzen
Eine weitere sehr wirkungsvolle Strategie zur Verbesserung des Flows ist es, die zeitgleich im System befindliche Arbeit (Work in Progress, WIP) zu begrenzen und dadurch zu reduzieren [8]. Indem weniger parallel zu bearbeitende Aufgaben existieren, können diese zügiger abgeschlossen werden. Es kommt zu weniger Kontextwechseln, halbfertige Arbeit bleibt seltener liegen, und das erneute Einarbeiten entfällt. Dadurch wird nicht nur Verschwendung abgebaut, sondern auch die Durchlaufzeiten sinken deutlich.

So logisch das in der Theorie klingt, so schwierig ist es, gerade diesen Punkt in der Praxis umzusetzen. Die Ursache für viel WIP liegt meist darin, dass Aufgaben aus verschiedenen Gründen nicht weiterbearbeitet werden können und dass auf diese Unterbrechung damit reagiert wird, dass man mit anderen Aufgaben beginnt. Schließlich ist es ja nicht akzeptabel, dass Teammitglieder beschäftigungslos rumsitzen – oder etwa doch?
Der erste Weg zielt darauf ab, nicht nur die Anzahl der Unterbrechungen zu reduzieren, sondern auch die Zielgröße „Auslastung“ zu hinterfragen. Werden Leerlaufzeiten zugunsten eines besseren Flows akzeptiert, sind die Benefits oft deutlich höher als die vermeintlichen Produktivitätsverluste.
Kleinere Batchgrößen
Ein einfacher, aber effektiver Hebel, um den Flow zu optimieren und die Durchlaufzeiten zu minimieren, ist die Reduktion der sogenannten Batchgrößen, also der Größe einzelner Arbeitspakete. Kleinere Arbeitspakete können rascher abgeschlossen werden, es können früher Ergebnisse erzielt und es kann früher Feedback eingeholt werden. Die Wahrscheinlichkeit für Unterbrechungen sinkt und der erwartete Mehrwert kann früher realisiert werden.
Diese kleineren Batchgrößen werden vor allem dadurch erreicht, dass Arbeitspakete aufgeteilt oder zunächst einfachere, weniger vollständige Lösungen umgesetzt werden. Herausforderung dabei ist, dass jedes dieser Teilpakete ein Ergebnis hervorbringen muss, das auslieferbar und nutzbar ist. Nur dann wird der Anspruch des ersten Wegs erfüllt.
Idealerweise kann mit diesem Teilergebnis bereits echtes Anwenderfeedback generiert werden. Je nach Situation kann es aber auch schon ausreichend sein, auf einer technischen Ebene neue Erkenntnisse zu gewinnen. Entscheidend ist stets die Frage, wie sich eine Lösung im Produktivbetrieb bewährt und welche Herausforderungen dabei auftreten. Deshalb ist der Anspruch an die Auslieferbarkeit so wichtig.
Die Arbeitspakete müssen dafür vertikal geschnitten werden, nicht horizontal (Abb. 2). Statt also in einem ersten Paket den vollständigen Datenzugriff zu implementieren – wofür man kaum zeitnahes Feedback erhält – empfiehlt es sich, zunächst nur eine kleine Teilfunktionalität umzusetzen. Das bedeutet beispielsweise, nur sehr wenige Felder von der Bedienoberfläche bis zur Datenschicht abzubilden. In nachfolgenden Paketen können dann weitere Datenfelder ergänzt oder zusätzliche Funktionen wie Validierungen integriert werden.
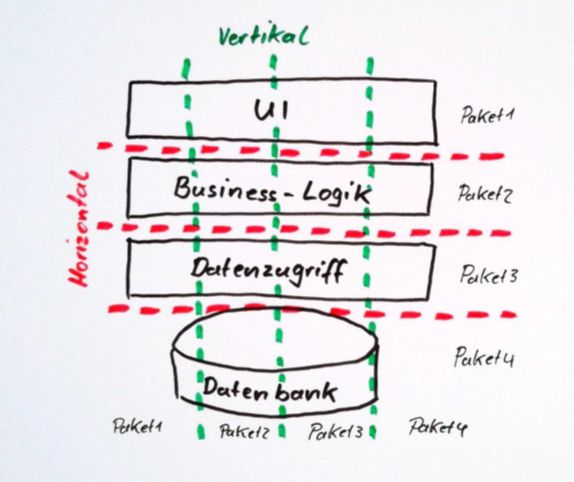
Abb. 2: Horizontale und vertikale Schnitte der Arbeitspakete
Gerade diese vertikale Zerlegung stellt Softwareentwicklungsteams häufig vor größere Herausforderungen, da die Realität selten so idealisiert abläuft wie im obigen Beispiel. Mit etwas Übung und Kreativität lässt sich jedoch in den meisten Fällen eine passende und sinnvolle Aufteilung finden.
Arbeit sichtbar machen
„Ein Bild sagt mehr als tausend Worte“ – dieser Satz gilt auch für den Arbeitsfluss durch das System. Eine Visualisierung kann viele wertvolle Hinweise liefern, macht Optimierungspotenziale sichtbar und verdeutlicht Zusammenhänge. Ein Kanban-Board etwa zeigt, an welcher Stelle im System der aktuelle Engpass liegt, ob WIP-Limits überschritten werden und welche Aufgaben bereits lange Bearbeitungszeiten aufweisen [9]. So ermöglicht die Visualisierung, rasch fundierte Entscheidungen zu treffen und gezielt die richtigen Fragen zu stellen.
Idealerweise bildet die Darstellung den gesamten Wertstrom ab, um das Prinzip des Systems Thinking zu unterstützen. Ergänzend können detailliertere Visualisierungen einzelner Teilstrecken des Value Streams erstellt werden. Dabei muss jedoch sichergestellt werden, dass diese Detailansichten die ganzheitliche Perspektive nicht in den Hintergrund drängen. Manch ein Team war erstaunt über die Komplexität des eigenen Value Streams. Erst nachdem dieser aufgezeichnet war, wurde transparent, wie viele Sonderfälle, Übergaben und verschiedene Quellen für Arbeit existieren.
Eine Visualisierung kann eine Diskussion anstoßen, die zu einer spürbaren Vereinfachung der über Jahre gewachsenen Prozesse und Regularien führt. Genau darauf zielt der erste Weg ab: Durch Verschlankung den Flow zu optimieren und so die Durchlaufzeiten zu reduzieren.
Übergaben reduzieren, mehr gemeinsame Verantwortung
Um eine signifikante Verbesserung des Flows im Gesamtsystem zu erreichen, ist der Abbau von Zuständigkeitsgrenzen erforderlich. In klassischen Organisationsstrukturen führt eine klare Abgrenzung von Verantwortlichkeiten dazu, dass Personen und Teams sich ausschließlich um die Optimierung ihre eigenen Abläufe und Ergebnisse kümmern, ohne die Auswirkungen auf den Gesamtprozess zu berücksichtigen. Im Kontext des ersten Wegs ist dagegen eine engere Kooperation und Zusammenarbeit erforderlich. Statt Teilergebnisse einfach an die nächste Station weiterzureichen und sie damit zu deren Problem zu machen, muss gemeinsam überlegt werden, wie der Gesamtprozess verbessert werden kann.
An welcher Stelle im Prozess kann ein Problem am effektivsten beseitigt werden? Welche Folgekosten haben Abkürzungen, die genommen werden, an anderer Stelle? Wie können redundante Aufgaben vermieden und durch Unterstützung die Kompetenzen aller Beteiligten möglichst ideal eingesetzt werden? Nur wenn eine ganzheitliche Betrachtung vorgenommen wird, von der Anforderung über Planung, Entwicklung, Qualitätssicherung bis hin zum Betrieb, kann der Flow auch wirklich verbessert werden. Wenn bereits bei der Planung und Implementierung darauf geachtet wird, dass anschließend ein möglichst reibungsloser Betrieb möglich ist, werden Kosten und Probleme weitestmöglich vermieden. Genau hier liegt ja der Ursprung des Begriffs „DevOps“.
Der oft zitierte Slogan „You build it, you run it“, der ein Szenario beschreibt, in dem die Entwickler auch die Betriebsverantwortung für ihr Softwareprodukt übernehmen, mag für viele Organisationen eher abschreckend als e0rstrebenswert klingen. Denn dieser Ansatz setzt voraus, dass im Team ein sehr breites Wissensspektrum vorhanden ist, das möglicherweise zuerst durch entsprechende Qualifizierungsmaßnahmen aufgebaut werden muss. Zudem ist es nachvollziehbar, dass diese breitere Verantwortung nicht bei allen Mitarbeitenden auf Gegenliebe stößt. Hier ist eine geeignete Unterstützung des Teams zur Lösung dieser Herausforderungen elementar (dazu kommen wir in Teil 3 der Artikelserie).
Letztlich bedeutet der erste Weg nicht zwingend, dieses Extremszenario vollständig umzusetzen. Vielmehr muss erkannt werden, wo Zuständigkeitsgrenzen und Silos den Gesamtprozess stören, und es muss an Verbesserungen gearbeitet werden. Jedes Unternehmen muss dafür seine individuellen, passenden Lösungen finden.
Wartezeiten minimieren
Eine zentrale Kennzahl zur Bewertung des Arbeitsflusses ist die Durchlaufzeit – also die Zeitspanne, bis ein Arbeitspaket den definierten Start- und Endpunkt des Systems durchläuft. Dabei stellt sich zunächst die Frage: Wo beginnt und wo endet „das System“? Beginnt die Messung bereits, wenn eine Anforderung in den Backlog aufgenommen oder erst, wenn sie einem Sprint zugewiesen wird? Und endet sie mit abgeschlossener Implementierung, mit dem Deployment in den Produktivbetrieb oder erst nach eingehendem Anwenderfeedback?
Auch hier gilt der Grundsatz, dass der Weg das Ziel ist. Teams, die gerade erst mit DevOps-Prinzipien beginnen, haben oftmals nur begrenzten Einfluss außerhalb ihres eigenen Zuständigkeitsbereichs. Daher empfiehlt es sich, dort anzusetzen, wo heute schon Veränderungen möglich sind, und die systemische Perspektive schrittweise zu erweitern.
Wenn man die Durchlaufzeit im Detail analysiert, stellt sich fast immer heraus, dass der aktiv bearbeitete Anteil – also die Zeiten, in denen wirklich Code geschrieben, Tests durchgeführt oder Deployments vorbereitet werden – nur einen Bruchteil der gesamten Durchlaufzeit ausmacht. Den weitaus größten Anteil nehmen die Wartezeiten ein: Phasen, in denen die Anforderung darauf wartet, dass eine andere Person den nächsten Arbeitsschritt übernimmt. Eine strukturierte Flussanalyse [10] hilft dabei, diese Wartezeiten im Prozess transparent zu machen (Abb. 3). Wenn klar ist, wo sich die längsten Wartezeiten häufen, lässt sich wirkungsvoll an deren Reduzierung arbeiten. Denn es ist beinahe immer so, dass eine Verringerung der Wartezeiten deutlich mehr Wirkung auf die Gesamtdurchlaufzeit hat als jedes Bemühen, einzelne Schritte noch schneller auszuführen.
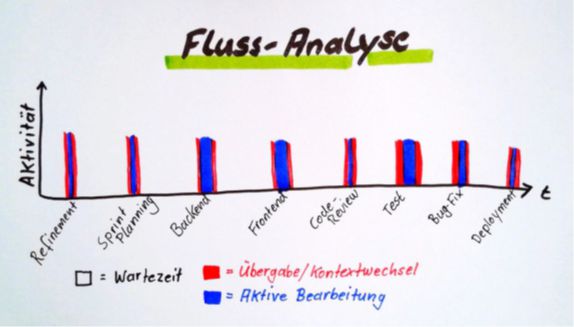
Abb. 3: Die Flussanalyse hilft, Wartezeiten aufzuspüren
Liegt eine Anforderung zunächst monatelang im Backlog, bevor sie in wenigen Tagen oder Wochen umgesetzt und ausgeliefert wird, so scheint es zunächst verlockend, diese Wartezeit im Backlog aus der Betrachtung der Durchlaufzeiten auszuklammern. Während das ein sinnvoller erster Schritt sein kann, muss im Sinne der systemischen Sicht aber längerfristig daran gearbeitet werden, auch diese Wartezeiten zu minimieren. Natürlich ist es aus Sicht des Entwicklungsteams unmöglich, alle Wünsche sofort umzusetzen. Eine ganzheitliche Betrachtung könnte jedoch die Frage aufbringen, ob das Backlog vielleicht zu umfangreich ist. Müsste es so gestaltet werden, dass darin nur Dinge enthalten sind, die zeitnah umgesetzt werden können? Damit könnte auch in Richtung der Stakeholder eine klarere Kommunikation ermöglicht werden. Was ins Backlog aufgenommen wird, das wird mit Sicherheit auch zeitnah umgesetzt. Was nicht zeitnah umgesetzt werden kann, scheint aktuell nicht wichtig genug zu sein.
Stay tuned
Regelmäßig News zur Konferenz und der Java-Community erhalten
Ähnliche Fragestellungen ergeben sich auch am Ende des Entwicklungsprozesses. Wenn neue Funktionen nach ihrer Fertigstellung zunächst auf einen Releasetermin warten müssen, dann könnte eine Erhöhung der Releasefrequenz dieses Problem reduzieren. Wenn implementierte Funktionen länger darauf warten, bis eine Qualitätssicherung durchgeführt werden kann, dann hilft eine Beschleunigung der Entwicklung sicher nicht, um hier zu einer Verbesserung zu kommen. Lange Wartezeiten sind oftmals ein wichtiger Hinweis auf die bereits thematisierten Engstellen im System. Maßnahmen, die helfen, diese Engstellen zu beseitigen und somit die Wartezeiten zu reduzieren, haben einen direkten Einfluss auf den Flow, und zwar ohne, dass mehr Kapazität geschaffen oder härter gearbeitet werden muss.
Diese Beispiele verdeutlichen, wie wirksam der erste Weg von DevOps sein kann, aber auch die Herausforderungen, die damit verbunden sein können. Substanzielle Verbesserungen lassen sich oftmals erst durch grundlegende organisatorische Veränderungen erreichen.
Verschwendung vermeiden
Ein wesentliches Ziel der Flow-Optimierung ist es, Verschwendung zu minimieren. Ein Großteil davon entsteht durch Kontextwechsel. Im Flussdiagramm in Abbildung 3 bedeutet jeder Wechsel von der Wartephase zur aktiven Bearbeitung der Aufgabe einen Kontextwechsel. Während der Bearbeitung kann es zudem zu weiteren Unterbrechungen kommen, etwa durch andere Aufgaben oder Meetings. Je häufiger eine Aufgabe unterbrochen wird, desto mehr Verschwendung entsteht. Dafür gibt es verschiedene Ursachen:
- Wiederholtes Eindenken in einen Aufgabenkontext kostet zusätzliche Zeit.
- Die Wahrscheinlichkeit für Fehler und Informationsverluste wird durch Kontextwechsel erhöht.
- Die Koordination der noch nicht erledigten Aufgaben erfordert zusätzlichen Aufwand für Planung, Abstimmung und Synchronisation.
- Die mentale Belastung steigt, was zu verminderter Kreativität und Entscheidungsqualität führt.
- Wird eine Aufgabe durch andere Personen oder Teams weiterbearbeitet, entsteht oftmals auch Dokumentationsbedarf.
Stattdessen sollte das System so gestaltet sein, dass Aufgaben möglichst in einem Rutsch erledigt werden können. Dazu tragen einige der bereits genannten Strategien wie beispielsweise kleinere Arbeitspakete bei. Auch die Bearbeitung von Aufgaben im Pair Programming oder als Gruppe (Mob Programming) unterstützen dieses Ziel. Darüber hinaus können auch Fokuszeiten organisiert werden, in denen ein ungestörtes Arbeiten möglich ist. In diesen Zeitfenstern sollten keine Meetings, Telefonate oder E-Mail-Bearbeitung stattfinden.
Ein weiterer Aspekt ist der Umgang mit Abhängigkeiten. Während in vielen Organisationen versucht wird, diese Abhängigkeiten bestmöglich zu managen, schlägt der erste Weg vor, diese Abhängigkeiten nach Möglichkeit zu reduzieren. Dafür spielt vor allem die Zusammensetzung der Teams eine wichtige Rolle, was uns wieder zum Ursprung des Begriffs DevOps zurückführt.
Automatisierung
Ein weiterer zentraler Faktor bei der Optimierung des ersten Weges ist Automatisierung [11]. Sie kann insbesondere genutzt werden, um den Durchsatz am Engpass zu erhöhen, weil dadurch Prozesse nicht nur deutlich schneller ablaufen, sondern auch Abhängigkeiten von einzelnen Personen und damit Wartezeiten reduziert werden.
Automatisierung führt auch zu einer höheren Standardisierung von Routineabläufen. Dadurch sinkt nicht nur die Fehleranfälligkeit, weil mehrfach erprobte Prozesse reproduzierbar ausgeführt werden können; sie reduziert auch die Abhängigkeit von Spezialwissen, das oft nur bei einzelnen Personen vorhanden ist.
Eine häufige Herausforderung der Automatisierung ist der typischerweise höhere anfängliche Aufwand. Ein Deployment zu automatisieren, bedeutet mehr Aufwand, als das Deployment einmalig manuell auszuführen. Die Aktualisierung des Datenbankschemas zu automatisieren, kostet mehr Zeit, als diese Anpassung einmalig direkt auf der Datenbank auszuführen. Das führt oft zu dem Phänomen, dass Teams zwar Automatisierung als wichtig und richtig ansehen, ihre Umsetzung jedoch aus Zeitmangel stets auf später verschieben.
Deployment als None-Event
Bei vielen Teams ist das Deployment in die Produktivumgebung ein risikoreiches Unterfangen: Erst hier zeigt sich, ob Planung, Implementierung und Qualitätssicherung tatsächlich ihren Zweck erfüllt haben oder ob Dinge übersehen wurden. Das führt dazu, dass Teams Deployment-Events möglichst selten durchführen wollen. Verstärkt wird dieser Effekt noch dadurch, dass vor dem Deployment oftmals noch aufwendige, teils manuelle Validierungen ausgeführt werden müssen. Um den Aufwand zu reduzieren, wird deshalb weiter versucht, die Releasefrequenz zu reduzieren. Ähnlich wie in der klassischen Produktion, wo die Rüstkosten pro Teil dadurch reduziert werden sollen, indem man möglichst lange dasselbe Teil fertigt und damit große Losgrößen produziert.
Wie in der klassischen Fertigung gilt jedoch: Auch in der Softwareentwicklung sollten Losgrößen minimiert werden. Das gilt insbesondere für die Menge an Funktionalität, die in einem Release enthalten ist. Dieser Ansatz mag kontraintuitiv erscheinen, doch existieren zahlreiche Nachweis dafür, dass kleinere Losgrößen und damit häufigere Releases positive Effekte haben [12], [13]. Voraussetzung dafür ist allerdings, dass die Rüstkosten deutlich reduziert werden. Anstatt seltener zu releasen, muss am Deployment-Prozess an sich gearbeitet werden.
Es gibt vielfältige Strategien, die „Rüstkosten“ für das Deployment eines Softwareprodukts zu reduzieren:
- Minimierung des manuellen Aufwands durch Automatisierung
- Reduktion der Fehleranfälligkeit durch Standardisierung
- Beseitigung von Schwach- und Fehlerstellen durch kontinuierliche Überprüfung und Anpassung
- aus Fehlern lernen – sich Zeit nehmen, um aus Fehlern Erkenntnisse für Verbesserungen zu ziehen und diese sofort umzusetzen
- Trainieren der Fähigkeiten durch regelmäßiges Üben
- Reduktion der Komplexität durch kleinere und damit besser überschaubare Pakete
- besseres Monitoring, um Probleme früher zu erkennen
- erprobte Rollback-Strategien, um schnell auf Fehler reagieren zu können
- Nutzung von Feature-Flags o. Ä., um Funktionalität inkrementell auszurollen [14]
Viele dieser Strategien benötigen einiges an Vorarbeit und möglicherweise auch neues Wissen und Kompetenzen im Team. Diese Investition wird sich aber sehr schnell auszahlen. Deployments können so zu einem „None-Event“, zu etwas Alltäglichem werden, das idealerweise jederzeit und von jeder Person im Team ausgeführt werden kann.
Nicht alles kann getestet werden
Ein weiterer Aspekt, der den Flow behindert, ist dabei der Anspruch, dass ein Inkrement, das ausgeliefert werden soll, vollständig (Ende zu Ende) getestet sein muss. Dieser Anspruch lässt sich allerdings selbst mit einem hohen Grad an Testautomatisierung meist nicht vollständig erreichen. Statt diesen Anspruch aufrechtzuerhalten, sollten Teams nach anderen, effektiveren Möglichkeiten suchen. Schließlich ist das Ziel nicht, eine vollständige Testabdeckung zu erhalten, sondern das Risiko für Fehler im Produktivbetrieb auf ein Minimum zu reduzieren. Für die Erreichung dieses Ziels ist das Testen eben nur eine Möglichkeit; andere, meist kostengünstigere und zeitsparendere bleiben oftmals ungenutzt.
Hier ist es erneut entscheidend, das System als Ganzes zu betrachten. Während Softwareentwickler:innen sich klassischerweise nicht um den Aufwand von Freigabetests und die Zuverlässigkeit im Betrieb kümmern, sollte im Sinne des ersten Wegs bereits bei Planung und Implementierung darauf geachtet werden, Risiken im Produktivbetrieb zu minimieren. Folgende Überlegungen können dabei helfen:
- Wie können wir Probleme im Produktivbetrieb möglichst schnell erkennen, um rasch darauf zu reagieren und die Auswirkungen zu begrenzen? Welche Funktionen sollten wir dazu in unsere Software integrieren?
- Wie können wir im Fehlerfall möglichst schnell wieder einen funktionierenden Zustand des Softwaresystems erreichen? Können wir diesen Vorgang vielleicht sogar automatisieren, sodass die Software sich selbst zu jeder Tages- und Nachtzeit automatisch in einen funktionierenden Zustand versetzen kann?
- Wie können wir durch defensives Programmieren das Risiko für Fehler im Produktivbetrieb minimieren?
- Wie können wir durch eine enge Zusammenarbeit und die Nutzung verschiedener Kompetenzen bereits in der Entwicklung Probleme vorhersehen und so vermeiden?
- Wie können wir aus unseren Fehlern lernen und das so erworbene Wissen möglichst gut an alle Beteiligten verteilen?
- Wie können wir durch Reduktion der Komplexität unser System robuster und resilienter machen?
- Welche Fähigkeiten und Kompetenzen sollten wir im Team aufbauen, um Probleme besser vermeiden zu können?
- Welche sind die größten Risiken für Fehler im Betrieb und wie können wir sie minimieren?
- Wie können wir ein Arbeitsumfeld schaffen, das dazu beiträgt, dass alle Beteiligten sich unseren Qualitätszielen verpflichtet fühlen und die Möglichkeit haben, diese auch zu erfüllen?
Letztlich geht es darum, dass alle Beteiligten eine hohe Konfidenz besitzen, dass das neue Inkrement beim Anwender keine Probleme verursacht. Allein die Tatsache, dass diese Konfidenz bei einzelnen Personen nicht sehr hoch ist, kann als Gelegenheit genutzt werden, um Schwachstellen und potenzielle Risiken zu identifizieren und geeignete Gegenmaßnahmen einzuleiten. Das Ziel muss sein, dass das Team jederzeit bedenkenlos ein Release deployen kann.
Fazit
Zusammengefasst geht es beim ersten Weg darum, den Wertbeitrag des Softwareprodukts dadurch zu steigern, dass Verbesserungen einfacher, schneller und häufiger bis zum Endanwender ausgerollt werden können. Durch diese verkürzte Time to Market entstehen nicht nur frühere Feedbackzyklen, die schnelles Reagieren ermöglichen, sondern es kann auch ein früherer Return on Investment (ROI) realisiert werden, da die Investition weniger lange im System verweilt.
Systems Thinking, wie es der erste Weg vorstellt, erfordert mitunter tiefgreifende organisatorische Veränderungen. Um eine ganzheitliche Betrachtung des gesamten Value Streams zu unterstützen, wäre es wünschenswert, dass alle Beteiligten – von der Anforderungserhebung beim Anwender und der Definition der Produktstrategie bis zur Implementierung und dem Betrieb – eng zusammenarbeiten und idealerweise als ein Team agieren. Während das bei sehr kleinen Produkten noch realisierbar ist, stößt diese Idealvorstellung bei größeren Produkten schnell an Grenzen. Dann ist eine Aufteilung in separate Teams erforderlich. Anstatt Menschen entsprechend ihrer Kompetenzen und Aufgabenbereiche in reine Funktionsteams zu gliedern, sollten hier interdisziplinäre, vertikale Teams [15] gebildet werden, die idealerweise alle notwendigen Kompetenzen entlang der gesamten Wertschöpfungskette abdecken (Abb. 4). Jedes dieser Teams kümmert sich eigenständig um einen Teilbereich des Gesamtprodukts und verantwortet diesen von Anfang bis Ende.
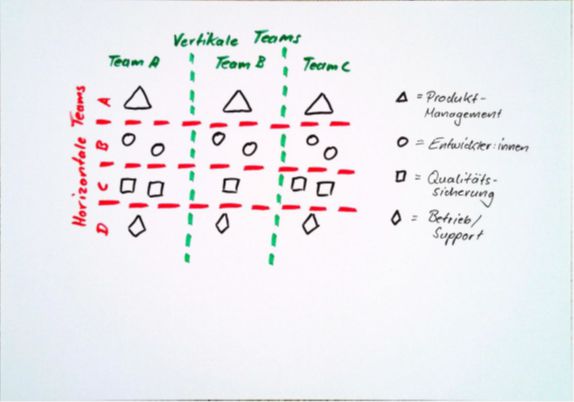
Abb. 4: Vertikale und horizontale Teams
Die gute Nachricht ist allerdings, dass diese oftmals tiefgreifenden Veränderungen nicht zwingend eine Voraussetzung für DevOps sein müssen. Vielmehr kann der erste Weg dazu beitragen, Hindernisse in der bestehenden Struktur zu identifizieren und diese schrittweise zu beseitigen. So kann zunächst der Austausch zwischen verschiedenen horizontalen Teams verbessert werden. In bestimmten Bereichen kann eine Neustrukturierung möglicherweise einfacher umgesetzt werden, wie beispielsweise die Aufhebung der Trennung zwischen Entwicklung und Qualitätssicherung. So entstehen Hybridmodelle, die je nach Erfordernissen weiterentwickelt oder auch beibehalten werden können.
Stay tuned
Regelmäßig News zur Konferenz und der Java-Community erhalten
Eine DevOps-Transformation beschreibt somit nicht einen definierten Zielzustand. Vielmehr startet sie immer mit dem Status quo. Von dort ausgehend gilt es, kontinuierlich nach Optimierungspotenzialen zu suchen und sie umzusetzen. Eine Organisation ist bereits dann auf einem guten Weg, den ersten Weg von DevOps zu meistern, wenn der Arbeitsfluss im System transparent gemacht wird, um so die aktuellen Engpässe zu identifizieren und Maßnahmen zu ergreifen, diese abzubauen.
Links & Literatur
[1] Kim, Gene et. al: „The DevOps Handbook: How to Create World-Class Agility, Reliability, & Security in Technology Organizations“; IT Revolution Press, 2016
[2] 2023 State of DevOps Report: https://cloud.google.com/blog/products/devops-sre/announcing-the-2023-state-of-devops-report
[3] 2024 State of DevOps Report: https://cloud.google.com/devops/state-of-devops
[4] Forsgren, Nicole, et. al: „Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations“; IT Revolution Press, 2018
[5] Kim, Gene, et. al: „The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win“; IT Revolution Press, 2013
[6] Goldratt, Eliyahu M.: „The Goal: A Process of Ongoing Improvement“, North River Press, 1984
[7] Ohno, Taiichi: „Toyota Production System: Beyond Large-Scale Production“; Productivity Press, 1988
[8] Poppendieck, Mary und Tom: „Lean Software Development: An Agile Toolkit“; Addison-Wesley, 2003
[9] Anderson, David J.: „Kanban: Successful Evolutionary Change for Your Technology Business“; Blue Hole Press, 2010
[10] Rother, Mike; Shook, John: „Learning to See: Value Stream Mapping to Add Value and Eliminate Muda“; Lean Enterprise Institute, 1999
[11] Humble, Jez; Farley, David: „Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation“; Addison-Wesley, 2010
[12] Reinertsen, D. G.: „The Principles of Product Development Flow: Second Generation Lean Product Development“; Celeritas Pub, 2009
[13] Humble, J.; Farley, D. „Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation“; Addison Wesley, 2010
[14] Hodgson, Pete: „FeatureToggles (aka Feature Flags)“: https://martinfowler.com/articles/feature-toggles.html
[15] Schissler, Thomas: „Horizontale vs. vertikale Teams – verschiedene Teamstrukturen im Vergleich“: https://www.agilemax.de/blogreader/Horizontale-vs-vertikale-Teams—verschiedene-Teamstrukturen-im-Vergleich




