Quelle: Shutterstock
von Lars Röwekamp
Die Vorteile Microservices-basierter Architekturen sind hinlänglich bekannt. Ist erst einmal ein passender Schnitt gefunden – Domain-driven Design lässt grüßen –, können die einzelnen Services mehr oder minder unabhängig voneinander entwickelt, getestet und deployt werden. Dies erhöht die Agilität der Teams und vermindert die Umsetzungsdauer neuer Features (a.k.a. Time to Market).
Eine wesentliche Grundvoraussetzung für den Erfolg einer Microservices-basierten Architektur ist dabei die konsequente Trennung der Services und ihrer Ressourcen. Getreu dem Motto „share nothing“ wird nicht nur der Sourcecode voneinander getrennt, sondern auch die zugehörige Datenhaltung. Nur wenn auch dieser Schritt konsequent gegangen wird, kann tatsächlich von einer losen Kopplung und einer damit einhergehenden Unabhängigkeit der Services gesprochen werden.
Was ist nun aber, wenn sich ein Use Case über mehrere Services und somit auch über mehrere Datenquellen aufspannt? Nehmen wir als Beispiel eine stark vereinfachte Variante eines Check-out-Prozesses innerhalb eines Webshops. Im Rahmen des Check-outs, also des Verkaufs von Produkten an einen Kunden, wird die Anzahl der Produkte innerhalb des Lagersystems um die gekaufte Menge reduziert. In einem monolithischen System würde dies transaktional erfolgen. In einem Microservices-basierten System dagegen würde es wahrscheinlich einen Check-out-Service und einen Inventory Service inkl. eigener Datenhaltung geben. Durch die Auftrennung der Datenhaltung und damit auch der Datenbank ist die Umsetzung der benötigten Transaktion nicht so ohne Weiteres realisierbar. Wir brauchen einen Plan B.
Versuch 1: Transaktionen vermeiden
Die aus technologischer Sicht einfachste Variante, mit dem eben beschriebenen Problem umzugehen, ist, die Services so zu schneiden, dass sich Transaktionen grundsätzlich nur innerhalb eines Service abspielen. Was sich in der Theorie denkbar einfach anhört, hat in der Praxis enorme Konsequenzen. Zwar vermeiden wir durch den Ansatz die Notwendigkeit des Aufteilens einer Transaktion auf mehrere Services, sorgen aber auf der anderen Seite für unnatürliche Service-Grenzen.
Nehmen wir noch einmal das Beispiel von oben. Um die notwendige Transaktion zu realisieren, müssten wir die beiden Services Checkout und Inventory zu einem CheckoutAndInventory Service zusammenlegen. Die erhofften Vorteile der Microservices-basierten Architektur gingen so verloren. Wir enden aus fachlicher Sicht in einem zu großen Service. Der Service hätte durch den Wegfall von Seperation of Concerns und Single Responsibility mehr als nur einen fachlichen Verantwortlichen und würde wahrscheinlich eine Größe einnehmen, die nicht mehr von nur einem agilen Team gemanagt werden kann.
Natürlich könnte man ggf. auch noch einmal die Grenzen der Services prüfen und den fachlichen Schnitt derart verschieben, dass zwar die notwendige Transaktion Teil eines der beiden Services wird, ansonsten aber weiterhin zwei Services bestehen bleiben. Dies ist dann eine Option, wenn die Services eher auf Entitäten aufbauen als auf Use Cases und somit von Anfang an ein ungünstiger Service-Schnitt gewählt wurde. In unserem Fall stellt das nicht wirklich eine Option dar. Was also tun?
Your Coffee Shop Doesn’t Use Two-Phase Commit
Als Erstes sollten wir uns einmal die Frage stellen, ob wir denn tatsächlich eine Transaktion benötigen. Was für eine dumme Frage, wird sich jetzt sicherlich der eine oder andere Leser denken. Natürlich brauchen wir eine Transaktion. Schließlich finden schreibende Zugriffe auf zwei Tabellen statt. Und wenn es eins zu vermeiden gilt, dann ist das doch wohl ein inkonsistenter Zustand in unserer Datenbank! Aus technologischer Sicht ist diese Aussage sicherlich korrekt. Aber stimmt sie auch aus fachlicher Sicht? Ist die Welt tatsächlich so transaktional, wie wir sie in unseren Systemen immer darstellen? Zu dieser Frage hat sich bereits vor fünfzehn Jahren Gregor Hohpe Gedanken gemacht und in seinem Artikel „Your Coffee Shop Doesn’t Use Two-Phase Commit“ [1] am Beispiel des Kaffeebestellvorgangs innerhalb der Starbucks-Läden beeindruckend erläutert, um wie viel besser Systeme skalieren könnten, wenn man auf die strenge Einhaltung von Transaktionen verzichtet und stattdessen lediglich garantiert, dass die Konsistenz der Daten zu einem bestimmten Zeitpunkt sichergestellt ist. Eventual Consistency – also letztendliche Datenkonsistenz – ist hier das Zauberwort der Stunde.
Okay, mag sich jetzt der deine oder andere denken, wir reden hier über Kaffee. Was ist aber mit dem obigen Beispiel des Shopsystems? Oder gar mit einem Bankensystem, bei dem Geld von Konto A nach Konto B transferiert wird?
Nehmen wir zunächst das Beispiel des Shopsystems. Aus fachlicher Sicht stellt sich weniger die Frage, ob der Produktzähler im Inventory Service zu jedem Zeitpunkt auf dem aktuellen Stand ist, sondern vielmehr, ob das bestellte Produkt an den Kunden in einer vordefinierten Zeit geliefert werden kann oder nicht. Falls das auch dann gewährleistet werden kann, wenn bei einem Lagerbestand von null z. B. auf eingehende Retouren zurückgegriffen werden kann oder Lieferanten eine kurzfristige Lieferung bei Nachbestellung garantieren, dann bringt die Sicherstellung der Konsistenz zwischen Check-out und Inventory Service nicht wirklich einen fachlichen Mehrwert. Natürlich muss letztendlich („eventual“) sichergestellt werden, dass spätestens zum Zeitpunkt einer Inventur die Produktzähler im Inventory Service mit dem tatsächlichen Lagerbestand übereinstimmen. Für unseren Bestellprozess ist das aber nicht wirklich essenziell. Tatsächlich wird sich diese Tatsache in vielen Shopsystemen zunutze gemacht, um den Check-out-Prozess zu beschleunigen und so für den Nutzer eine bessere Usability zu erreichen.
Schauen wir uns nun das Beispiel des Bankensystems an. Wer schon einmal Geld von einem Konto auf ein anderes überwiesen hat, der weiß, dass dies definitiv kein transaktionaler Vorgang ist. In der Regel erfolgt die Abbuchung auf dem eigenen Konto sehr zeitnah. Die Wertstellung auf dem Gegenkonto kann dagegen bis zu mehreren Tagen dauern. Auch hier gilt wieder, dass lediglich sichergestellt sein muss, dass die Wertstellung letztendlich erfolgt, wir also garantieren können, dass es nach einer endlichen und fachlich vertretbaren Zeit zu einem konsistenten Zustand der Daten innerhalb des Systems kommt. Was wäre aber, wenn in der Zwischenzeit das Zielkonto gesperrt oder gar geschlossen würde? Bei einer klassischen Transaktion käme es hier zu einem Rollback. In unserem Fall muss sichergestellt sein, dass der Betrag dem Ausgangskonto wieder gutgeschrieben wird.
Für die eben gezeigten Beispiele lassen sich Transaktionen also durchaus vermeiden, indem fachliche Alternativen umgesetzt werden. Was aber, wenn es dennoch den Bedarf für Transaktionen gibt, die über Service-Grenzen hinausgehen?
Versuch 2: fachliche Transaktionen
Wir haben im obigen Beispiel des Bankensystems gesehen, dass die ursprüngliche Transaktion in mehrere Schritte aufgeteilt wurde, die zeitlich versetzt abgearbeitet werden können. Gleichzeitig wurde sichergestellt, dass am Ende entweder alle angedachten Schritte ordnungsgemäß ausgeführt wurden oder alternativ eine Kompensation – in unserem Beispiel eine Rückbuchung des Betrags auf das Ausgangskonto bei gesperrten Zielkonto – erfolgt.
Hinter diesem Pattern, das auch als SAGA-Pattern [2] bekannt ist, verbirgt sich folgende Idee: Es gilt, fachliche Transaktionen oder Invarianten, die sich über unterschiedliche Services erstrecken, auf mehrere, technisch lokale Transaktionen mit fester Ablaufreihenfolge zu verteilen.
Jede gelungene lokale Transaktion triggert den nächsten Schritt der Aufrufkette und somit die nächste lokale Transaktion an. Jede misslungene lokale Transaktion hingegen muss dafür sorgen, dass alle anderen bisher abgelaufenen lokalen Transaktionen der Aufrufkette kompensiert, also wieder rückgängig gemacht werden.
Nehmen wir uns noch einmal einen Use Case aus unserem Webshop mit folgender Invariante vor: Eine Bestellung kann nur dann erfolgreich aufgegeben werden, wenn die Summe aller offenen Bestellungen des Kunden kleiner oder gleich seines Kreditvolumens ist. Während die Bestellung selbst innerhalb des Order Service abgehandelt wird, findet die Prüfung und Aktualisierung des Kreditrahmens innerhalb des Customer Services satt. In einem ersten Schritt legt der Order-Service eine Bestellung mittels lokaler Transaktion innerhalb seiner Datenbank an, gibt diese aber noch nicht frei. Der Status der Bestellung steht entsprechend auf „pending“. Im Anschluss signalisiert der Order-Service, z. B. durch ein Domänen-Event, den erfolgreichen Abschluss dieses Schritts. Das Domänen-Event wiederum ist das Signal für den nächsten Service in der Aufrufkette – nämlich den Customer-Service, der seinen Teil der verteilten fachlichen Transaktion ausführen soll. Die Verfügbarkeit der notwendigen Bestellsumme wird geprüft und durch eine lokale Transaktion innerhalb des Customer-Service reserviert. Auch dieser Schritt wird wieder mit einer Erfolgsmeldung an die Außenwelt, also die anderen Services beendet. Dadurch weiß der Order-Service, dass er im Rahmen einer weiteren lokalen Transaktion den Status der Bestellung von „pending“ auf „approved“ setzen kann (Abb. 1).
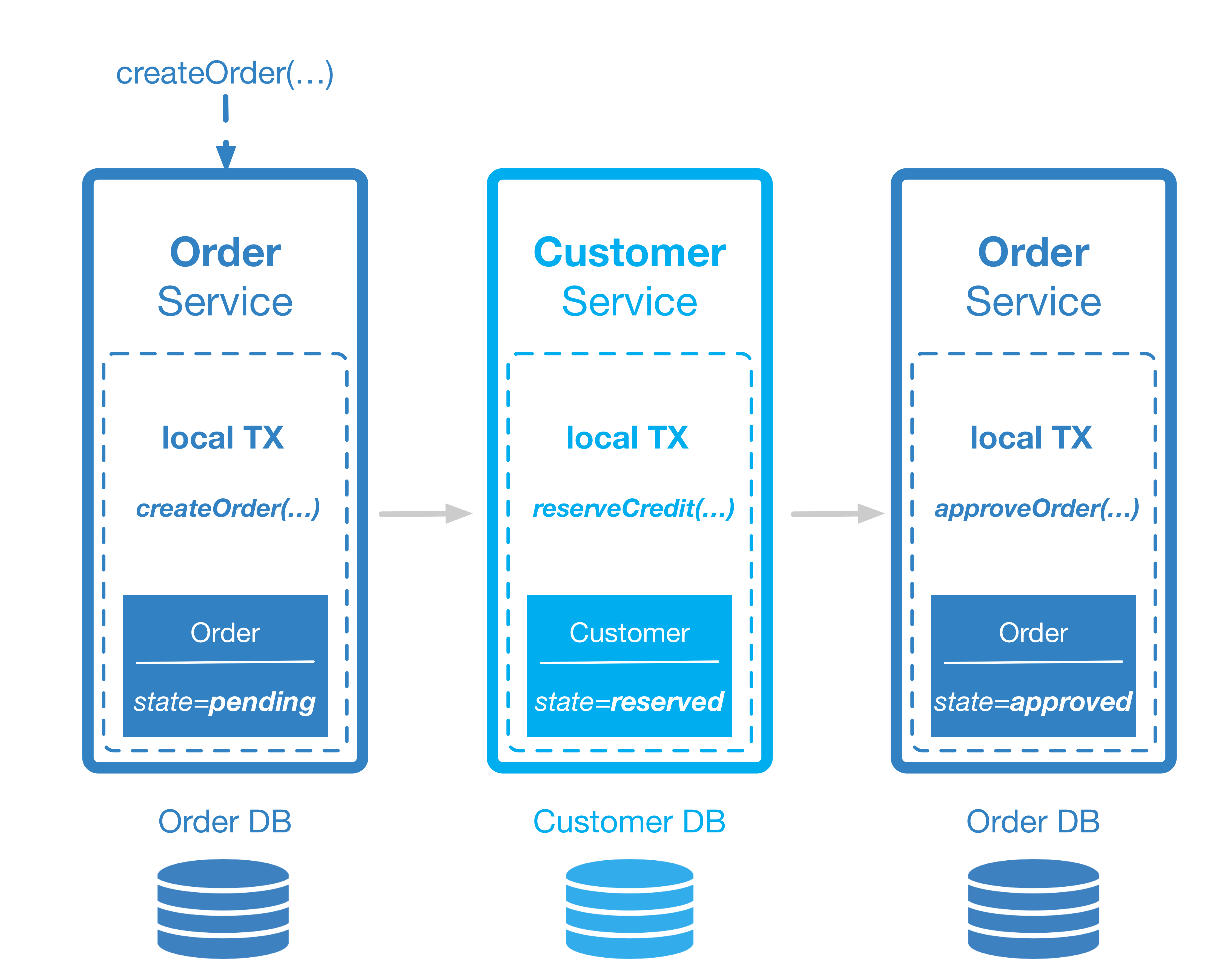
Abbildung 1: Saga-Pattern in Aktion
So weit, so gut. Was aber, wenn innerhalb des beschriebenen Ablaufs nicht alles so läuft wie geplant? Was wäre, wenn zum Beispiel der Verfügungsrahmen des Kunden nicht ausreichend ist oder der Bestellstatus, aus welchen Gründen auch immer, nicht auf „approved“ gesetzt werden kann? In diesem Fall müsste die Aufrufkette Schritt für Schritt wieder zurückgegangen werden und für jede bis dato stattgefundene lokale Transaktion eine lokale Kompensation stattfinden (Abb. 2).
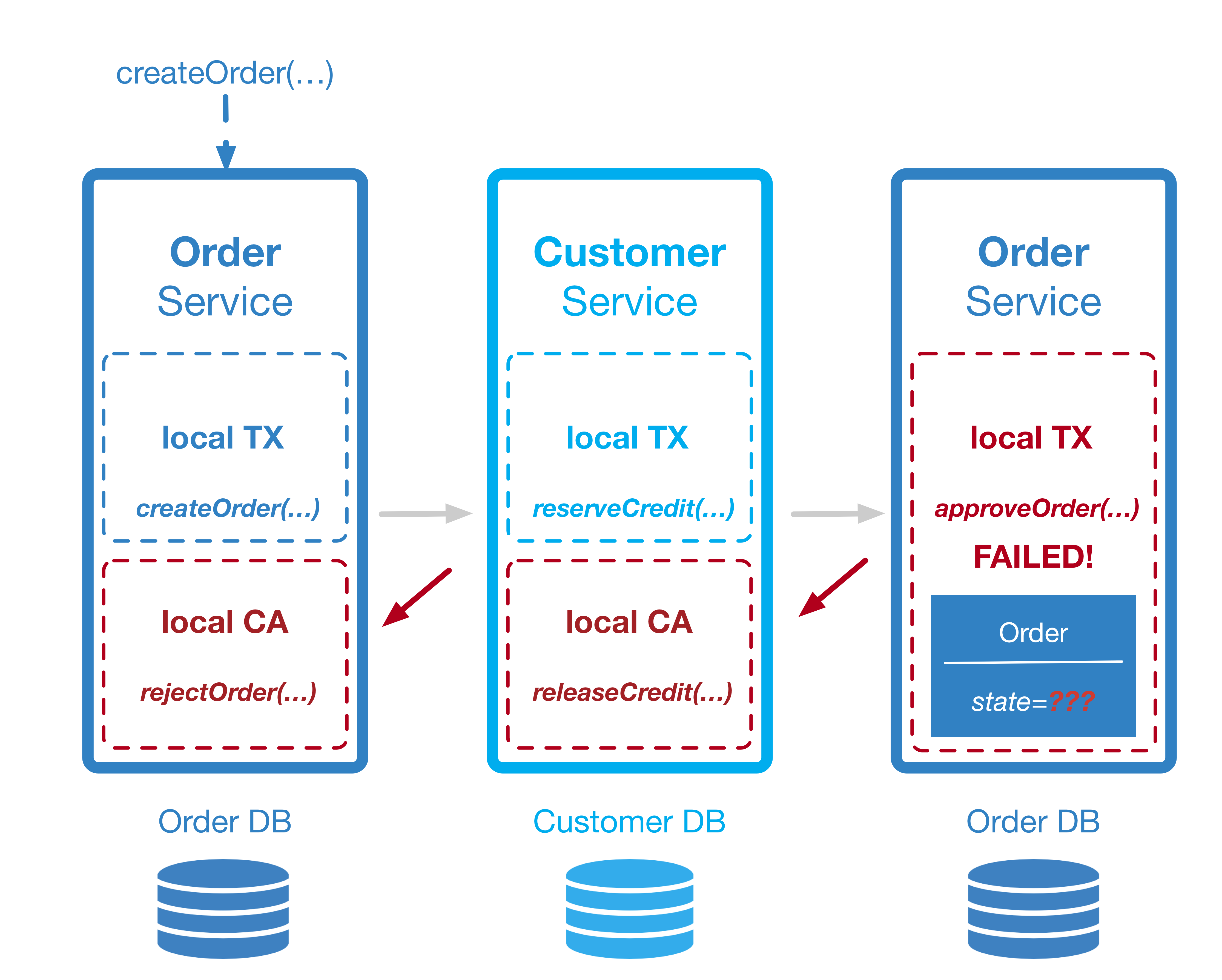
Abbildung 2: Transaktion und Kompensation
Was in der Theorie recht einfach klingt, kann in der Praxis beliebig komplex werden. Was passiert zum Beispiel, wenn in einem der Schritte eine E-Mail versandt wurde? Diese lässt sich nicht einfach via lokalem Rollback rückgängig machen. Stattdessen müsste eine zweite E-Mail versandt werden, die dem Adressaten verdeutlicht, dass der Inhalt der ersten E-Mail nicht mehr valide ist. In Shopsystemen wird zum Beispiel aus Gründen der User Experience (schnelle Reaktionszeit) häufig eine Bestellung bestätigt, ohne 100% zusichern zu können, dass diese am Ende auch wirklich ausgeliefert werden kann. Das ergibt durchaus Sinn, da durch Retouren und ausstehende Lieferungen weniger der tatsächliche Lagerbestand von Interesse für die Verfügbarkeit ist, als vielmehr der wahrscheinliche Lagerbestand zum Zeitpunkt des geplanten Versands. Eine angemessene Überbuchung ist somit fachlich sinnvoll.
In der Regel erhält der Shopbesucher neben der reinen Bildschirmdarstellung der Bestellbestätigung auch eine entsprechende E-Mail. Sollte nun einer der wenigen Fälle eintreten, in denen die Ware am Ende tatsächlich nicht geliefert werden kann, wird eine zweite E-Mail hinterhergeschickt. Die beinhaltet dann im günstigsten Fall neben der negativen Meldung der Nichtverfügbarkeit des Artikels gleich alternative Produktangebote evtl. sogar mit Sonderrabatten versehen, um so das negative Kauferlebnis am Ende doch noch positiv zu gestalten.
Der Microservices Track auf der JAX 2019
Wer soll da noch durchsteigen?
Bereits die kleinen oben aufgezeigten Beispiele lassen vermuten, dass die Verteilung einer fachlichen Transaktion auf mehrere Services und somit auf mehrere lokale Transaktionen keine triviale Herausforderung darstellt. Das gilt insbesondere dann, wenn man neben den Transaktionen selbst und ihrem Zusammenspiel auch die für sie jeweils notwendigen Kompensationen in Betracht zieht. Ganz zu schweigen von möglichen Kompensationen der Kompensationen, also Fallback-Szenarien für den Fall, dass nicht nur die Transaktion, sondern auch deren Kompensation fehlschlägt. Für die Steuerung des Ablaufs innerhalb des SAGA-Patterns kommen prinzipiell zwei Varianten infrage: Choreografie und Orchestrierung.
Bei der Choreografie sendet ein Service nach erfolgreicher Abarbeitung seiner lokalen Transaktionen eine Erfolgsmeldung via Domänen-Event. Interessierte Services, also die jeweils nächsten in der Ablaufsteuerung, registrieren sich für dieses Event und werden so zur Laufzeit durch das Auftreten des Events aktiviert. Der Gesamtablauf ergibt sich implizit durch den Fluss der Events und die Reaktion der Services auf ebendiese. Der Vorteil dieses Vorgehens liegt klar auf der Hand. Zum einen ist die Ablaufsteuerung relativ einfach zu implementieren, da die Services lediglich in der Lage sein müssen, Events zu erzeugen bzw. auf diese zu reagieren. Durch die Verwendung von Events ist zusätzlich eine lose Kopplung der Services untereinander garantiert. Die Services rufen sich niemals direkt auf und müssen sich gegenseitig nicht kennen. Nachteile ergeben sich insbesondere dann, wenn die fachliche Transaktion komplexer wird. Es findet sich nirgends im Code explizit der gewünschte Ablauf. Und auch die Komplexität des Domänenmodells erhöht sich, da für die Kommunikation zwischen den Services Domänen-Events benötigt werden. Dadurch, dass diese Events und deren Bedeutung sowohl vom Sender als auch dem Empfänger gekannt werden müssen, ergeben sich zyklische Abhängigkeiten der Services untereinander. Abbildung 3 zeigt die Choreografie eines Bestellprozesses, bei dem im Rahmen der fachlichen Transaktion zunächst die Kundendaten verifiziert werden (Customer Services). Im Anschluss erfolgt die Reservierung des zu bestellenden Produkts (Inventory Service) sowie die abschließende Zahlung (Accounting Service).
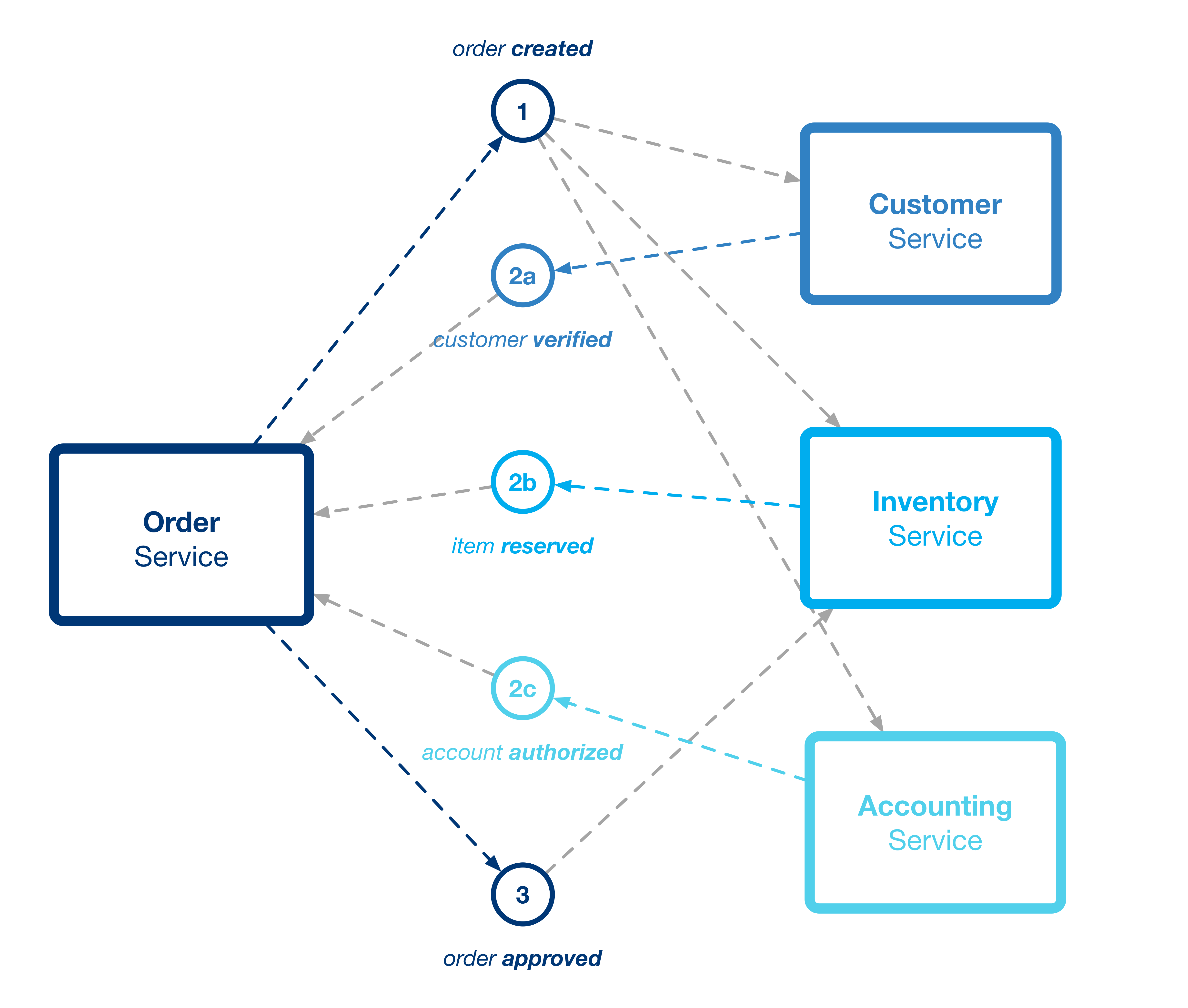
Abbildung 3: Implizite Ablaufsteuerung via Choreografie
Bei der Orchestrierung übernimmt eine zentrale Instanz die Steuerung des Ablaufs. Derjenige Service, der die Transaktion anstößt, erzeugt eine Instanz eines SAGA-Koordinators. Dieser Koordinator orchestriert den Ablauf der fachlichen Transaktion, d. h., er kümmert sich um den Aufruf der involvierten Services bzw. deren Logik sowie ggf. um notwendige Kompensationen. Der Aufruf der involvierten Services erfolgt dabei nicht über Domänen-Events, sondern über Commands. In unserem Beispiel würde der SAGA-Koordinator, der innerhalb des Order-Service beheimatet wäre, also nicht ein Event „Order mit dem Status pending wurde angelegt“ in den Raum werfen. Stattdessen würde er gezielt das Command „verify customer“ absetzen, das zur Validierung des Kunden innerhalb des Kundenservices führt (Abb. 4).
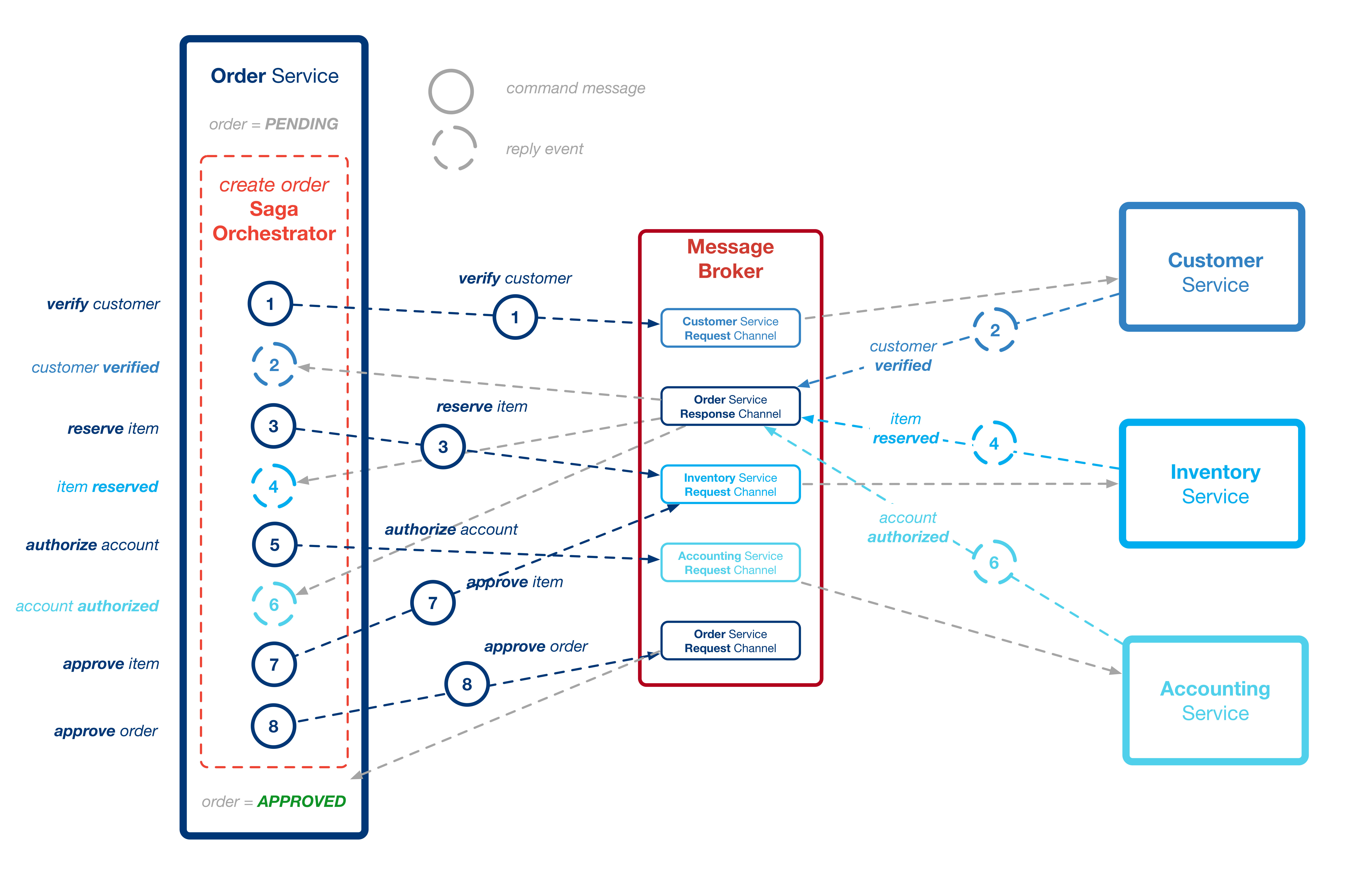
Abbildung 4: Orchestrierung
Das klingt zunächst einmal sehr ähnlich, ist es aber nicht. Da der angesprochene Service über sein Standard-API aufgefordert wird, einen seiner Dienste auszuführen, benötigt er keinerlei Wissen über den Aufrufer bzw. dessen Domäne. Bei Domänen-Events dagegen muss der Empfänger wissen, was das Event eines anderen Service fachlich bedeutet und wie er darauf regieren muss. Durch die Orchestrierung lösen wir also die zyklische Abhängigkeit auf und verlagern das Wissen über den Prozess an eine zentrale Stelle, nämlich in den SAGA-Koordinator.
Fazit
Soll eine Microservices-basierte Architektur zum Erfolg führen, setzt dies eine strikte Trennung der Ressourcen voraus. Das gilt auch für die Datenbank, was automatisch zu Problemen führt, wenn sich Use Cases, die zu einer verteilten Änderung von Daten führen, über mehr als einen Service erstrecken. Eine Möglichkeit, mit diesem Problem umzugehen, besteht im Hinterfragen der fachlichen Notwendigkeit der Transaktion. In der Praxis zeigt sich häufig, dass eine Transaktion nicht wirklich notwendig ist, sondern lediglich die letztendliche Sicherstellung der Konsistenz der Daten (eventual consistency).
In den Fällen, in denen tatsächlich eine Transaktion benötigt wird, lässt sich dies mit Hilfe des SAGA-Patterns realisieren, bei dem die verteilte, fachliche Transaktion in mehrere, technisch lokale Transaktionen aufgeteilt wird – inklusive Kompensation für den Fehlerfall. Die Koordination des verteilten Ablaufs der fachlichen Transaktion kann dabei entweder implizit via Choreografie, unter Verwendung von Domain Events, erfolgen oder aber explizit via Orchestrierung unter Zuhilfenahme eines SAGA-Koordinators und passender Commands. Sowohl die Choreografie als auch die Orchestrierung haben ihre Vor- und Nachteile, sodass es gilt, von Fall zu Fall bewusst abzuwägen.
Bei beiden Ansätzen geht es im Grunde genommen darum, die aktuelle fachliche Transaktion mit Hilfe diverser Status und deren Übergänge in den Griff zu bekommen. Das legt natürlich nahe, das Rad nicht neu zu erfinden, sondern für die Umsetzung auf entsprechend leichtgewichtige State- oder Workflow-Engines zu setzen. Aber das ist ein Thema für eine andere Kolumne. In diesem Sinne: Stay tuned and engage!
Cheat-Sheet: Die neuen JEPs im JDK 12

Unser Cheat-Sheet definiert für Sie, wie die neuen Features in Java 12 funktionieren. Von JEP 189 „Shenandoah“ bis JEP 346 „Promptly Return Unused Committed Memory from G1“ fassen wir für Sie zusammen, was sich genau ändern wird!
Links & Literatur
[1] https://www.enterpriseintegrationpatterns.com/docs/IEEE_Software_Design_2PC.pdf
[2] https://microservices.io/patterns/data/saga.html