Wir berichten hier über die Erfahrungen, die wir in einem gemeinsamen Projekt im öffentlichen Sektor gesammelt haben. Dort haben wir verschiedene Strategien für die Fehlerbehandlung bei der Verarbeitung asynchroner Nachrichten in unseren Consumern erarbeitet und verglichen. Neben der Minimierung unserer Betriebsaufwände mussten wir dabei wegen notorisch enger Zeitpläne auch unseren Entwicklungsaufwand minimieren. Deswegen haben wir zunächst nach einer Strategie gesucht, die in einem ersten Schritt als einzige „Catch all“-Strategie für alle Fehlerszenarien anwendbar ist: eine „Minimum Viable“-Fehlerstrategie.
Bei der Bewertung der Strategien haben wir die möglichen Fehlerszenarien nach zwei Dimensionen unterschieden, der Fehlerquelle und der Fehlerhäufigkeit.
Fehlerquelle:
- Der Producer erzeugt Nachrichten, die nicht dem Schnittstellenvertrag entsprechen, entweder syntaktisch oder semantisch.
- Der Consumer ist nicht in der Lage, alle Nachrichten, die dem Schnittstellenvertrag entsprechen, zu verarbeiten, z. B., wirft er unerwartete Ausnahmen.
- Die Infrastruktur arbeitet nicht erwartungsgemäß, z. B. fällt die Verbindung des Consumers zu seiner Datenbank aus.
Fehlerhäufigkeit:
- Der Fehler tritt nur selten und vereinzelt auf, z. B. als sporadischer Edge Case.
- Der Fehler ist ein generelles und länger andauerndes Problem, das viele Nachrichten betrifft.
Bei der schlussendlichen Bewertung der Strategien haben sich die Vor- und Nachteile dann oft als unabhängig von Fehlerquelle oder Fehlerhäufigkeit herausgestellt.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Kafka-Grundlagen
Um die verschiedenen Strategien der Fehlerbehandlung zu verstehen, ist es notwendig, die grundlegenden Konzepte von Kafka zu kennen. Diese erläutern wir hier kurz. Für Details verweisen wir z. B. auf den Artikel „Kafka 101: Massive Datenströme mit Apache Kafka“ [2].
Broker
Kafka bezeichnet sich als Event-Streaming-Plattform, die als Ersatz für traditionelle Message-Broker benutzt werden kann. Der Message-Broker dient dazu, asynchrone Nachrichten in Topics zu veröffentlichen. Nach einer konfigurierbaren Zeit, der Retention Time, löscht der Broker die Nachrichten.
Producer
Der Producer veröffentlicht Nachrichten mit einem Schlüssel in einem Kafka Topic. Der Broker teilt ein Topic in mehrere Partitionen auf und speichert eine Nachricht in genau einer Partition des Topics. Dabei berücksichtigt der Broker den Schlüssel der Nachricht und schreibt alle Nachrichten mit demselben Schlüssel auch in dieselbe Partition. Je Partition garantiert der Broker, dass die Reihenfolge der Nachrichten erhalten bleibt. Der Producer muss die Schlüssel der Nachrichten also so wählen, dass alle Nachrichten, deren Reihenfolge untereinander erhalten werden muss, denselben Schlüssel haben.
Consumer
Die an den Nachrichten interessierten Consumer registrieren sich für das Topic und können so die Nachrichten vom Broker lesen und verarbeiten. Dabei geben die Consumer die Consumer Group an, zu der sie gehören. Der Broker stellt dann sicher, dass jede Partition genau einem Consumer einer Consumer Group zugewiesen ist.
Problembeschreibung
In unserem Projekt nutzen wir Kafka (Kasten: „Kafka-Grundlagen“), um Änderungen an den Daten, die ein System verantwortet, als Events dieses Systems zu veröffentlichen. Im Domain-Driven Design spricht man hier von den Zustandsänderungen eines Aggregats [3]. Wir erzeugen und verarbeiten die Events im Publish-Subscribe-Modus. Da die Retention Time mit fünf Tagen als endlich vorgegeben ist, enthalten die Events nicht nur die geänderten Daten, sondern immer den kompletten neuen Zustand des Aggregats.
Bezüglich der Performance haben wir recht entspannte Anforderungen: Aus fachlicher Sicht ist es ausreichend, wenn die Events vor Ablauf der Retention Time verarbeitet werden. Dabei ist es jedoch wichtig, dass die Reihenfolge der Events mit demselben Schlüssel erhalten bleibt und kein Event übersprungen oder anderweitig nicht vollständig verarbeitet wird. Events mit demselben Schlüssel nennen wir abhängig.
Nach Mathias Verraes [4] gibt es zwei schwierige Probleme in verteilten Systemen. Die Einhaltung der Reihenfolge ist das erste. Dieses Problem haben wir gelöst, indem die Nachrichten, deren Reihenfolge untereinander erhalten werden muss, denselben Schlüssel bekommen. Das zweite schwere Problem ist die Exactly-once Delivery. Wir können es umgehen, indem wir unsere Consumer idempotent implementieren.
Codebeispiele
Im Folgenden illustrieren wir jede betrachtete Strategie mit einem Codebeispiel. Diese nutzen die MicroProfiles Reactive Messaging und Fault Tolerance. Als Implementierung für beide MicroProfiles benutzen wir die für Quarkus üblichen Bibliotheken von SmallRye. Die Codebeispiele sind auch auf GitHub [5] zu finden.
Bei der Nutzung der Codebeispiele sind zwei Aspekte zu berücksichtigen: die Commit Strategy [6] und die Failure Strategy [7]. Als Commit Strategy haben wir latest gewählt, da beim Default throttled der Timeout throttled.unprocessed-record-max-age.ms [8] während länger dauernder Retries einer fehlerhaften Nachricht erreicht werden kann. Als Failure Strategy haben wir eine eigene Strategie implementiert, die davon ausgeht, dass der Code, der die Nachricht empfängt, die Fehler direkt behandelt und daher keine separate Failure Strategy mehr notwendig ist (Listing 1).
public class CustomKafkaFailureHandler implements KafkaFailureHandler {
@ApplicationScoped
@Identifier("custom")
public static class Factory implements KafkaFailureHandler.Factory {
@Override
public KafkaFailureHandler create(
KafkaConnectorIncomingConfiguration config,
Vertx vertx,
KafkaConsumer<?, ?> consumer,
BiConsumer<Throwable, Boolean> reportFailure) {
return new CustomKafkaFailureHandler();
}
}
@Override
public <K, V> Uni<Void> handle(IncomingKafkaRecord<K, V> record,
Throwable reason, Metadata metadata) {
return Uni.createFrom()
.<Void>failure(reason)
.emitOn(record::runOnMessageContext);
}
Consumer herunterfahren
Der erste Halt auf unserer Reise führt uns zu einer äußerst einfach umzusetzenden Strategie: Consumer herunterfahren. Hierbei stoppt der Consumer die Verarbeitung und fährt den Prozess, in dem er läuft, herunter. Das macht er in dem Codebeispiel (Listing 2), indem er System.exit() aufruft. Alternativ könnte er z. B. in einer Kubernetes-Umgebung die Liveness-Probe [9] fehlschlagen lassen und so den Containermanager dazu veranlassen, den Prozess herunterzufahren. Diese Strategie, eingeschränkt auf den Kafka-Client des betroffenen Topics, bietet auch SmallRye Reactive Messaging an und nennt sie fail [10], [11].
@Incoming("aggregate-in")
public CompletionStage<Void> consume(Message<String> record) {
LOGGER.trace("Aggregate received: {}", record.getPayload());
try {
controller.process(record.getPayload());
return record.ack();
} catch (Exception e) {
LOGGER.error("Oops, something went terribly wrong with "
+ record.getPayload(), e);
System.exit(1);
return null; // never reached
}
}
Um diese Strategie universell einsetzen zu können, ist es hilfreich, einen Containermanager zu haben, der den heruntergefahrenen Prozess neu startet. So bekommen wir den Retry in Form eines Restart Loops [7] geschenkt.
Der Weg zur Korrektur ist je nach Fehlerursache unterschiedlich: Bei einem Fehler im Producer sendet dieser die korrigierte Nachricht sowie alle abhängigen Nachrichten erneut. Der Consumer muss dann die Offsets der fehlerhaften Nachricht und aller ursprünglichen abhängigen Nachrichten überspringen.
Bei einem Fehler im Consumer ist lediglich der Bugfix zu deployen, dann läuft der Consumer einfach weiter. Bei einem Fehler in der Infrastruktur ist nichts zu tun, der Consumer läuft einfach weiter, sobald der Fehler behoben wurde.
Vorteile:
- Die Strategie erhält die Reihenfolge.
- Der manuelle Aufwand für die Fehlerbehebung ist beim Team des Consumers unabhängig von der Anzahl fehlerhafter Nachrichten.
Nachteile:
- Der Microservice blockiert auch fehlerfreie Nachrichten.
- Die Strategie führt in überwachten Umgebungen wie Kubernetes zu einer Restart-Schleife. Die wiederum führt je nach Timeout, Restart Backoff, Restart Cutoff und Start-up-Zeit dazu, dass der Broker die Partitionen auf die restlichen Consumer umverteilt, sodass am Ende jeder Consumer versuchen wird, die fehlerhafte Nachricht zu verarbeiten, und dann herunterfährt. Das wiederum verursacht vermutlich einen erhöhten Ressourcenverbrauch. Durch das Herunterfahren weiterer Consumer werden auch immer mehr Nachrichten in anderen Partitionen blockiert.
- Die Strategie erfordert in nicht überwachten Umgebungen einen Mechanismus, um den Consumer nach der Fehlerbehebung wieder zu starten.
- Die Strategie erfordert einen zusätzlichen Mechanismus zum Überspringen von fehlerhaften und ggf. auch abhängigen Nachrichten.
- Bei Fehlern in der Nachricht müssen alle abhängigen Nachrichten vom Producer nochmals geschickt werden.
Dead Letter Queue
Die nächste Station unserer Reise ist ein Klassiker der Fehlerbehandlung von asynchronen Nachrichten: die Dead Letter Queue (DLQ). Im Zusammenhang mit Kafka wird diese Strategie oft auch als Dead Letter Topic bezeichnet, bei der Umsetzung mittels Datenbank auch als Dead Letter Table. Tritt ein Fehler beim Verarbeiten einer Nachricht im Consumer auf, sortiert der Consumer die betroffene Nachricht in die namensgebende Warteschlage für „tote“ Nachrichten aus. Anschließend macht er mit der Verarbeitung der nächsten Nachricht weiter (Listing 3). Als Alternative zu einer eigens implementierten Fehlerbehandlung bietet SmallRye die Dead Letter Queue auch als Failure Strategy an [10], [12].
@Incoming("aggregate-in")
public CompletionStage<Void> consume(Message<String> record) {
LOGGER.trace("Aggregate received: {}", record.getPayload());
try {
controller.process(record.getPayload());
} catch (Exception e) {
LOGGER.error("Oops, something went terribly wrong with "
+ record.getPayload(), e);
deadLetterEmitter.send(record);
}
return record.ack();
}
Der Weg zur Korrektur ist wieder von der Fehlerursache abhängig. Bei einer semantisch oder syntaktisch fehlerhaften Nachricht schickt der Producer eine korrigierte Nachricht. Die fehlerhafte Nachricht in der DLQ muss daraufhin übersprungen werden. Bei einem Fehler des Consumers muss der Bugfix deployt werden, anschließend müssen die Nachrichten der DLQ wieder eingelesen werden. Auch nach Behebung eines Infrastrukturproblems muss die DLQ wieder eingelesen werden.
Vorteile:
- Blockiert nur Nachrichten, bei denen ein Fehler auftritt, d. h. keine Verzögerung nicht betroffener Nachrichten und maximaler Durchsatz.
- Gute Skalierung auch bei vielen fehlerhaften Nachrichten.
- Falls der Fehler nicht in der Nachricht lag, kann die DLQ nach dem Bugfix erneut eingelesen werden.
- Der manuelle Aufwand für die Fehlerbehebung ist beim Team des Consumers unabhängig von der Anzahl fehlerhafter Nachrichten.
- Bei einer Implementierung der DLQ mittels Datenbank kann man die Retention Time von Kafka umgehen, wodurch man mehr Zeit für die Fehlerbehebung hat.
Nachteile:
- Erfordert einen separaten (u. U. manuellen) Mechanismus zum Einlesen der DLQ nach dem Bugfix.
- Wirft die Reihenfolge der Nachrichten durcheinander.
- DLQ muss eine Kapazität wie das ursprüngliche Topic haben, falls der Fehler einen Großteil der Nachrichten betrifft.
- Die Strategie erfordert einen zusätzlichen Mechanismus zum Überspringen von fehlerhaften und ggf. auch abhängigen Nachrichten.
- Bei Fehlern in der Nachricht müssen alle abhängigen Nachrichten vom Producer nochmals geschickt werden.
DLQ Advanced
Mit Blick auf unsere Problemstellung hat die einfache Dead Letter Queue ein entscheidendes Problem: Sie kann die Reihenfolge von Nachrichten nicht erhalten. Unsere Reise führt deswegen tiefer in die Welt der DLQs. Die Idee: Eine erweiterte Dead Letter Queue nimmt nicht nur Nachrichten auf, die bei der Verarbeitung Probleme machen, sondern auch alle von ihr abhängigen Nachrichten. Dazu muss lediglich der Schlüssel der fehlerhaften Nachricht gespeichert werden. Anschließend können alle abhängigen Nachrichten durch den gleichen Schlüssel identifiziert und ebenfalls in die DLQ geleitet werden (Listing 4).
@Incoming("aggregate-in")
public CompletionStage<Void> consume(KafkaRecord<String, String> record) {
LOGGER.trace("Aggregate received: {}", record.getPayload());
try {
if(controller.shouldSkip(record.getKey())) {
LOGGER.warn("Record skipped: " + record);
deadLetterEmitter.send(record);
} else {
controller.process(record.getPayload());
}
} catch (Exception e) {
LOGGER.error("Oops, something went terribly wrong with "
+ record.getPayload(), e);
controller.addKeyToSkip(record.getKey());
deadLetterEmitter.send(record);
}
return record.ack();
}
Der Weg zur Korrektur ist zunächst identisch mit dem der einfachen DLQ. Im Detail wird es jedoch kompliziert. Um die Reihenfolge beim Wiedereinlesen der DLQ weiterhin zu erhalten, muss ihr Einlesen mit dem Einlesen des regulären Topics koordiniert werden. Benutzt man ein Kafka Topic als DLQ, stellen sich weitere Probleme, wie die Verteilung von Schlüsseln in zwei Topics auf unterschiedliche Consumer und die Vermischung von korrigierten und nicht korrigierten Nachrichten in der DLQ. Die Realisierung als Dead Letter Table in der Datenbank löst manche dieser Probleme, verursacht aber auch neue. Wegen dieser steigenden Komplexität haben wir zu diesem Zeitpunkt ein Zwischenfazit gezogen, um nach weiteren Alternativen zu suchen.
Vorteile:
- Die Strategie erhält die Reihenfolge.
- Blockiert nur fehlerhafte und davon abhängige Nachrichten, d. h. keine Verzögerung nicht betroffener Nachrichten und maximaler Durchsatz.
- Bei einer Implementierung der DLQ mittels Datenbank kann man die Retention Time von Kafka umgehen, womit man mehr Zeit für die Fehlerbehebung hat.
Nachteile:
- Erfordert einen zusätzlichen Mechanismus zum Überspringen von fehlerhaften und ggf. auch abhängigen Nachrichten.
- Erfordert komplexen (u. U. manuellen) Mechanismus zum Einlesen und Synchronisieren der DLQ nach dem Bugfix mit dem ursprünglichen Topic.
- Die DLQ muss eine Kapazität wie das ursprüngliche Topic haben, falls der Fehler einen Großteil der Nachrichten betrifft.
- Der manuelle Aufwand für die Fehlerbehebung ist beim Team des Consumers unabhängig von der Anzahl fehlerhafter Nachrichten.
Pausieren und Wiederholen
Die Dead Letter Queue ist eine naheliegende Lösung, wenn man von Fehlern ausgeht, die einzelne Nachrichten betreffen. Je mehr Nachrichten betroffen sind – egal, ob durch die Reihenfolge oder die gemeinsame Fehlerursache –, desto komplexer und aufwendiger wird die Lösung. Man kann sich dem Problem einer allgemeinen Fehlerbehandlung aber auch von einem anderen Szenario her nähern: dem Ausfall der Infrastruktur. Dabei spielt es keine Rolle, ob dieser Fehler den Ausfall einer notwendigen Datenbank, des Kafka-Clusters oder der Netzwerkverbindung betrifft. Entscheidend ist: Der Fehler betrifft vermutlich alle Nachrichten. Er lässt sich also nicht durch eine Quarantäne einzelner Nachrichten begrenzen. Die klassische Lösung für diesen Fall kennt jeder von automatischen Telefonansagen: „Bitte versuchen Sie es später noch einmal!“
Der erste Teil dieser Taktik besteht im Pausieren der Arbeit. Beim kompletten Herunterfahren des Consumers provozieren wir jedoch ein kostspieliges Rebalancing durch den Broker (siehe oben). Man kann aber auch das Konsumieren pausieren, solange man nicht den gesamten Consumer anhält. Das verhindert, dass der Broker die Pause als Ausfall des Consumers wertet und ein Rebalancing einleitet.
Der zweite Teil der Taktik ist das Wiederholen (engl. Retry) der Aktion, bei der ein Fehler aufgetreten ist. In unserem Fall bedeutet das auf oberster Abstraktionsebene immer das Konsumieren einer Nachricht. Wenn man außerdem die fehlerhafte Nachricht nicht committet, wird sie der Consumer nach der Pause einfach erneut einlesen und versuchen, sie zu verarbeiten.
Listing 5 zeigt, wie man beide Schritte mit der Retry-Annotation des MicroProfile Fault Tolerance umsetzt. Hiermit pausiert der Consumer für alle Partitionen, die ihm der Broker zugewiesen hat. Alternativ kann man dem Broker auch das Pausieren [13] einer einzelnen Partition direkt mitteilen und später die Verarbeitung mittels resume [14] wieder aufnehmen.
@Incoming("aggregate-in")
@Retry(delay = 2000L, jitter = 400L, maxRetries = -1, maxDuration = 0)
@ExponentialBackoff(maxDelay = 2, maxDelayUnit = ChronoUnit.HOURS)
public CompletionStage<Void> consume(Message<String> record) {
LOGGER.trace("Aggregate received: {}", record.getPayload());
try {
controller.process(record.getPayload());
return record.ack();
} catch (Exception e) {
LOGGER.error("Oops, something went terribly wrong with "
+ record.getPayload(), e);
return record.nack€;
}
}
Der Weg zur Korrektur ist wie immer abhängig von der tatsächlichen Fehlerursache. Da Infrastrukturprobleme meist externe Probleme sind, muss das Entwicklerteam bei der Lösung der Fehlerursache oft gar nicht aktiv werden. Tritt ein Infrastrukturproblem auf, können alle Consumer in einer Consumer Group unabhängig voneinander die Arbeit einstellen und in den Wiederholungsmodus wechseln. Sobald das Problem gelöst ist, sorgt das automatische Wiederholen für den Wiederanlauf aller Consumer.
Falls der Fehler beim Producer liegt, muss dieser wie bei allen anderen Strategien auch eine korrigierte Nachricht sowie eventuell weitere abhängige Nachrichten erneut schicken. Der Consumer muss alle vom Fehler betroffenen Nachrichten konsumieren und ignorieren. Bis dahin werden je nach gewählter Umsetzungsvariante entweder alle Nachrichten blockiert, die in der Partition mit der fehlerhaften Nachricht landen oder die in den Partitionen landen, die dem Consumer zugewiesen sind. Für abhängige Nachrichten wird die Partition quasi zu einer erweiterten Dead Letter Queue, die beim Wiedereinlesen allerdings keine Synchronisation benötigt. Ob und wie viele unabhängige Nachrichten vom Pausieren betroffen sind, hängt vom Verhältnis der Anzahl der Kafka-Schlüssel zur Anzahl der Partitionen und ggf. auch von der Anzahl der Consumer ab.
Falls der Fehler im Consumer liegt, blockieren die Partitionen, die von dem Fehler aktuell betroffen sind. Wie stark das Pausieren den Durchsatz bremst, hängt von der Schwere des Fehlers, möglichen Zusammenhängen mit den Kafka-Schlüsseln sowie vom Zufall ab. Sobald ein Bugfix deployt wurde, laufen die pausierten Partitionen durch das automatische Wiederholen ohne operativen Eingriff selbstständig wieder an.
Vorteile:
- Pausiert nur betroffene Partitionen eines Consumers bzw. nur einen Consumer. Die Granularität hängt von der Anzahl der Consumer und der Anzahl der Partitionen ab.
- Die Umsetzungsvariante mit der Retry-Annotation ist einfacher als das Pausieren einzelner Partitionen.
- Verhindert Ressourcenverschwendung durch unnötiges Rebalancing.
- Bei notwendigem Rebalancing (z. B. Consumer stürzt ab, neue Consumer kommen zwecks Skalierung hinzu) wird der neue Consumer automatisch die fehlerhafte Partition wieder pausieren.
- Das System macht automatisch weiter, nachdem das Problem behoben ist, z. B. durch Deployment eines Bugfixes. Auch bei sporadischen Problemen, die sich selbst nach kurzer Zeit lösen, macht das System automatisch weiter. Das Team profitiert dabei vom Prinzip der Selbstheilung.
- Der manuelle Aufwand für die Fehlerbehebung ist beim Team des Consumers unabhängig von der Anzahl fehlerhafter Nachrichten.
Nachteile:
- Falls es mehr Kafka-Schlüssel als Partitionen gibt (was der Normalfall sein dürfte), werden auch Schlüssel angehalten, die sich zufällig in derselben Partition befinden, aber nicht betroffen sind.
- Bei der Umsetzungsvariante mit der Retry-Annotation werden auch Nachrichten in Partitionen angehalten, die nicht die fehlerhafte Nachricht enthalten, falls es weniger Consumer als Partitionen gibt.
- Erfordert zusätzlichen Mechanismus zum Überspringen von fehlerhaften und ggf. auch abhängigen Nachrichten.
- Bei Fehlern in der Nachricht müssen alle abhängigen Nachrichten vom Producer nochmals geschickt werden.
Einfach loggen
Zunächst dachten wir nach dem produktiven Einsatz unseres Systems einige Wochen lang, wir könnten es uns auf der Insel „Pausieren und Wiederholen“ gemütlich machen. Dann mussten wir jedoch einen Abstecher zu einer weiteren Strategie unternehmen, die wir ursprünglich als absurd angesehen und daher direkt aussortiert hatten. Mittlerweile haben wir sie jedoch für spezielle Fälle zu schätzen gelernt. Diese Fälle zeichnen sich dadurch aus, dass ein Sachbearbeiter im ursprünglichen System Daten manuell korrigieren muss. Das verringerte den Durchsatz bei der Strategie „Pausieren und Wiederholen“ so deutlich, dass wir die Nachricht nun mittels einfachem Loggen behandeln. Dabei haben wir sichergestellt, dass nur einzelne Nachrichten so behandelt werden, und setzen diese Strategie somit nicht als Catch-all-Strategie ein.
Diese Strategie loggt die fehlerhafte Nachricht und bzw. oder ihre Metadaten, zählt gegebenenfalls eine Metrik hoch und verarbeitet dann die nächste Nachricht (Listing 6). Auch diese Strategie bietet SmallRye an und nennt sie ignore [10], [15].
@Incoming("aggregate-in")
public CompletionStage<Void> consume(Message<String> record) {
LOGGER.trace("Aggregate received: {}", record.getPayload());
try {
controller.process(record.getPayload());
} catch (Exception e) {
LOGGER.error("Oops, something went terribly wrong with "
+ record.getPayload(), e);
}
return record.ack();
}
Der Weg zur Korrektur ist hier unabhängig von der Fehlerursache manuell: Die Logmeldung oder die erhöhte Metrik stößt einen manuellen Prozess an, der die Fehlerursache beheben und dann die geloggten und damit nicht verarbeiteten Nachrichten reproduzieren muss. Aufgrund des hohen manuellen Aufwands sollte diese Strategie nur für Fehlerursachen angewandt werden, die einzelne Nachrichten betreffen. Insbesondere scheidet sie damit für Infrastrukturprobleme aus.
In unserem Projekt setzen wir diese Strategie für Nachrichten ein, die der Producer fehlerhaft erstellt hat. Nachdem der Fehler im Producer behoben wurde, lässt der manuelle Prozess die Nachricht und alle davon abhängigen Nachrichten erneut erzeugen.
Vorteil:
- Überspringt nur Nachrichten, bei denen ein Fehler auftritt, und vermeidet damit eine Verzögerung nicht betroffener Nachrichten. Die Strategie maximiert also den Durchsatz.
Nachteile:
- Wirft die Reihenfolge der Nachrichten durcheinander.
- Verliert Nachrichten, falls die Fehlerursache im Consumer oder in der Infrastruktur liegt.
Fazit
Unsere Reise durch die Untiefen der asynchronen Fehlerbehandlung zeigt, dass je nach konkreter Problemstellung verschiedene Optionen infrage kommen, die auf den ersten Blick absurd erscheinen. Ganz prinzipiell kann man die von uns gefundenen Optionen nach der Granularität des Eingriffs und der Komplexität ihrer Umsetzung sortieren (Abb. 1).
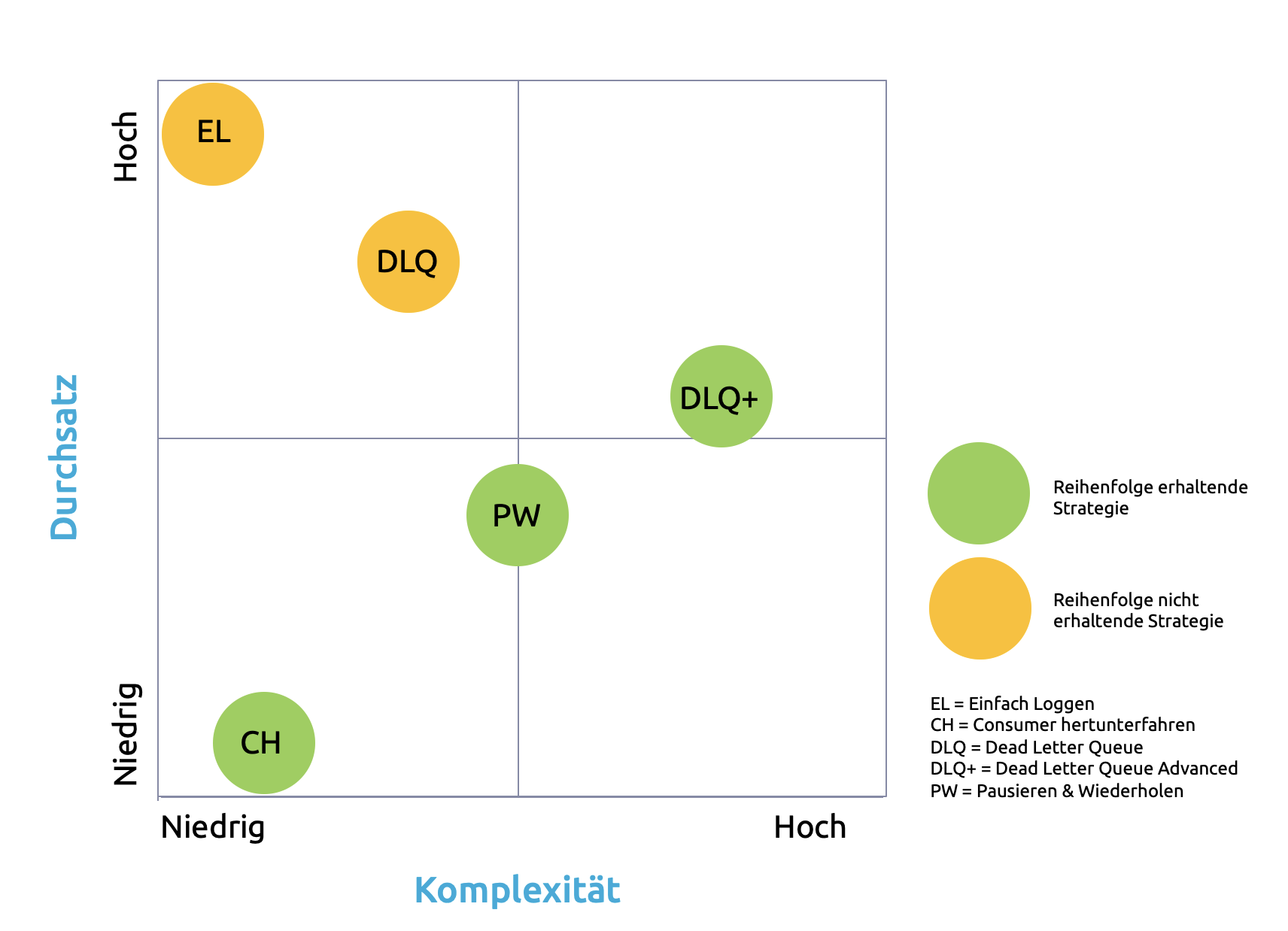
Abb. 1: Strategien im Überblick
Einfach loggen bedeutet de facto keinen Eingriff und ermöglicht so einen hohen Durchsatz. Zudem ist es bestechend simpel. Der Preis ist das Risiko des Verlusts der korrekten Reihenfolge und kompletter Nachrichten. Die klassische Dead Letter Queue verhindert den Datenverlust durch einen minimalen Eingriff, kann aber die Reihenfolge auch nicht sicherstellen. Sie ist dafür auch etwas komplexer, als nur zu loggen. Die erweiterte Dead Letter Queue greift exakt so viel ein wie notwendig, um Datenverlust zu verhindern und die Reihenfolge zu erhalten. Dafür muss man sich aber um eine Reihe von Detailproblemen kümmern. Diese Option ist deshalb die komplexeste. Bei Pausieren und Wiederholen werden u. U. auch unabhängige Nachrichten angehalten, allerdings selten das gesamte Topic. Datenverlust und Reihenfolge sind kein Thema. Die Komplexität ist moderat und beschränkt sich größtenteils auf das Wissen über die Konfiguration von Kafka selbst. Die einfachste Option, die Datenverlust vermeidet und die Reihenfolge einhält, ist das komplette Herunterfahren des Consumers. Das bedeutet aber in den meisten Fällen auch den niedrigsten Durchsatz während eines Fehlers.
Selbstverständlich kann man all diese Lösungen durch weitere kleinere Lösungen ergänzen. Auch wenn wir auf der Suche nach einer Catch-all-Strategie waren: Oft ist es besser, Probleme dort zu lösen, wo sie auftreten. Das heißt, dass z. B. eine Datenbankausnahme auch einfach das Wiederholen des Datenbankaufrufs auslösen kann, statt die Verarbeitung der Nachricht sofort abzubrechen. Für bestimmte fachliche Spezialfälle mögen sogar einfaches Loggen und eine manuelle Lösung durch den Fachbereich akzeptabel sein.
Für unser Projekt haben wir uns am Ende für Pausieren und Wiederholen entschieden. Die erweiterte Dead Letter Queue wurde uns zu komplex und wir waren uns nicht sicher, ob wir trotz dieser Komplexität nicht immer noch manuell in die Produktion würden eingreifen müssen. Pausieren und Wiederholen waren dagegen vergleichsweise simpel zu verstehen und dabei nicht zu restriktiv. Vor allem aber faszinierte uns, dass wir damit effektiv manuelle Eingriffe in der Produktion vermeiden konnten. Das automatische Wiederholen bedeutete letztlich den Beginn einer geradezu magischen neuen Eigenschaft unseres Systems: der Selbstheilung.
Links & Literatur
[1] https://6sense.com/tech/queueing-messaging-and-background-processing/apache-kafka-market-share
[2] https://entwickler.de/software-architektur/kafka-101/
[3] https://www.dddcommunity.org/library/vernon_2011/
[4] https://twitter.com/mathiasverraes/status/632260618599403520
[5] https://github.com/HilmarTuneke/kafka-fehlerbehandlung
[7] https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#restart-policy
[11] https://quarkus.io/blog/kafka-failure-strategy/#the-fail-fast-strategy
[12] https://quarkus.io/blog/kafka-failure-strategy/#the-dead-letter-topic-strategy
[15] https://quarkus.io/blog/kafka-failure-strategy/#the-ignore-strategy