Natürlich sollten sich IT-Experten mit Hypes wie Microservices [1] [2] [3] [4] kritisch auseinandersetzen. Am Ende gibt es nur vorteilhafte oder weniger vorteilhafte Entscheidungen für ein bestimmtes Projekt. Die individuellen Vor- und Nachteile in dem jeweiligen Projekt sollten im Mittelpunkt stehen. Es ist schließlich kaum sinnvoll, coole Ansätze zu wählen, die dem Projekt nicht helfen. Genauso wenig sinnvoll ist es, uncoole Ansätze von vornherein auszuschließen, obwohl sie vielleicht ein konkretes Problem lösen.
Aber ein Hype entsteht nicht einfach so. Um die Vorteile besser zu verstehen, ist es sinnvoll, den Ursprung des Hypes nachzuvollziehen. Dazu zunächst ein Blick auf die Situation vor der Zeit der Microservices: Damals gab es nur Deployment-Monolithen. Einige dieser Monolithen hatten so große Mengen Code, dass allein das Kompilieren teilweise 10 oder 20 Minuten dauerte und nochmal so lange, bis die Anwendung gestartet war. Dazu kommen noch die Zeiten für Unit- und andere Tests. Und für die Tests muss die Anwendung möglicherweise mehrmals gestartet werden. Irgendwann ist dann eine produktive Arbeit kaum noch möglich, weil Programmierer so lange warten müssen, bis die Ergebnisse ihrer Arbeit sichtbar sind.
Wenn man den Code tatsächlich weiterentwickelt und testet, sind solche Zeiten kaum akzeptabel. Eine Änderung dauert einfach viel zu lange. Dazu kommen dann noch komplexe Integrationen mit anderen Systemen oder komplizierte Laufzeitumgebungen, wie beispielsweise Application Server. Sie gilt es, zu konfigurieren, was die Zyklen weiter verlängert und den Weg in die Produktion noch schwieriger macht.
Ich habe in meinen ersten Vorträgen über Microservices das Publikum gefragt, ob es Projekte mit zu großen Deployment-Einheiten kennen würde oder welche mit zu kleinen. Damals gab es scheinbar viele Projekte mit zu großen, aber praktisch kaum Projekte mit zu kleinen Deployment-Einheiten. Zumindest damals war eine Verkleinerung der Deployment-Einheiten sicher sinnvoll.
Der Ursprung
Eine gute Quelle zum Ursprung des Hypes und der Geschichte der Microservices ist Wikipedia [5]. Demnach gab es 2011 einen Softwarearchitekturworkshop, bei dem mehrere Teilnehmer einen neuen Architekturstil beschrieben. 2012 wurde dann im nächsten Workshop aus dieser Serie der Begriff „Microservice“ erfunden. Beteiligt waren dabei beispielsweise Adrian Cockcroft (Netflix), James Lewis (Thoughtworks) oder Fred George (Freelancer). Alle drei hatten bereits sehr viel Erfahrung und arbeiteten an wichtigen Projekten. Sie haben den Microservices-Ansatz sicher nicht gewählt, um einen neuen Hype zu erzeugen, sondern um reale Probleme zu lösen.
Die konkreten Probleme in ihren Projekten glichen sich, aber es gab auch Unterschiede: Während beispielsweise für Netflix eine Cloud-Strategie sehr wichtig war, ist das bei den anderen Projekten nicht so stark der Fall gewesen. Einige der Projekte müssen skalieren, aber teilweise in unterschiedlichen Bereichen: Skalierung der Teamgröße oder der Software auf mehrere Server.
Die Lösungen unterscheiden sich daher: Netflix setzt auf synchrone Kommunikation und Services, die so groß sind, dass ein Team mit der Entwicklung ausgelastet ist. Fred George hingegen empfiehlt asynchrone Kommunikation und Microservices, die höchstens einige hundert Zeilen groß sind und sehr einfach neu geschrieben werden können.
Es gab also nie das eine wahre Microservices-Konzept, sondern schon von Anfang an verschiedene Ansätze, die unterschiedliche Probleme lösen. Auch heute ist es noch so, dass der Microservices-Ansatz sehr unterschiedlich interpretiert und umgesetzt wird.
Module
Aber worum geht es bei Microservices überhaupt? Im Kern sind Microservices eine andere Art von Modulen und stehen damit in Konkurrenz zu Modularisierungsansätzen wie JARs, Maven-Projekten oder Java Namespaces. Eine Aufteilung wie in Abbildung 1 kann also als Microservices umgesetzt werden – oder mit einem anderen Modularisierungsansatz.
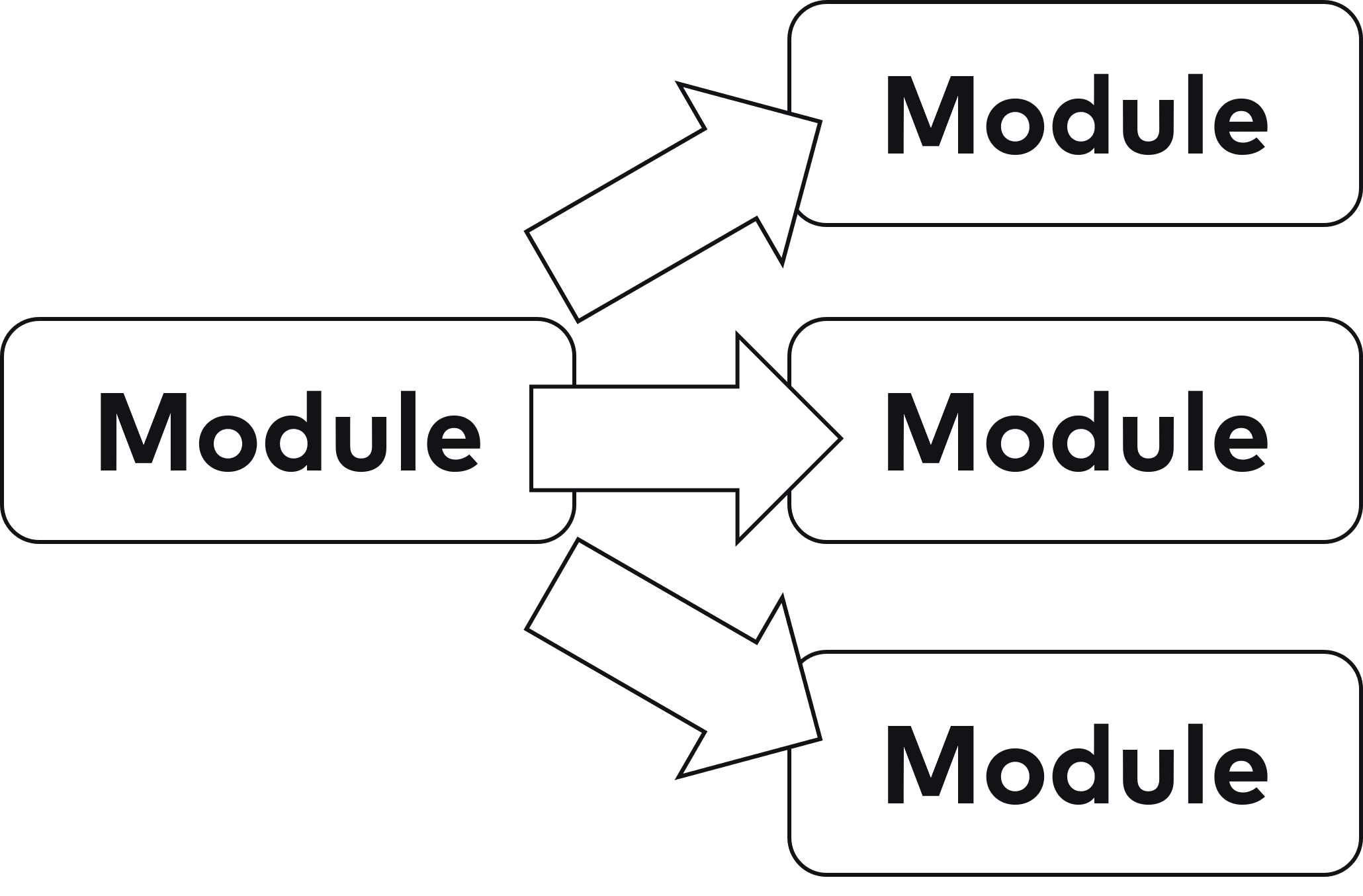
Zwischen Microservices und anderen Optionen gibt es wesentliche Unterschiede:
- In einem Deployment-Monolith kann es schnell passieren, dass man in neuem Code irgendeine vorhandene Klasse nutzt, die in irgendeinem Package abgelegt ist. Dadurch kann eine Abhängigkeit zwischen Packages entstehen, die eigentlich nicht gewünscht ist. Diese Abhängigkeit ist nicht beabsichtigt. Sie fällt vielleicht noch nicht einmal auf, weil sie im Code versteckt ist und Abhängigkeiten zwischen Packages nicht offensichtlich sind. Das führt dazu, dass ein Deployment-Monolith nach einiger Zeit eine Vielzahl von unerwünschten Abhängigkeiten hat. Natürlich kann z. B. ein Architekturmanagementwerkzeug das vermeiden. Wenn aber keine Vorkehrungen getroffen worden sind, ist das Abhängigkeitschaos in der Architektur unaufhaltsam. Sind die Module hingegen Microservices, kommunizieren sie untereinander durch eine explizite Schnittstelle z. B. per REST. Also muss man eine Abhängigkeit von einem Microservice zu einem anderen explizit einführen, indem man die Schnittstelle nutzt. Dadurch können sich Abhängigkeiten nicht einfach so einschleichen, weil man irgendeine Klasse aus Versehen nutzt.
- Für den Betrieb sind die einzelnen Module sichtbar, weil sie getrennte Prozesse sind. Bei einem Deployment-Monolithen sind hingegen alle Module in einem einzigen Prozess untergebracht. Das bedeutet, dass neben Deployment auch andere Betriebsaspekte wie Metriken und Sicherheit sich an einzelnen Modulen orientieren können.
Weil Microservices die Frage nach einer sinnvollen Aufteilung eines Systems stellen, sind durch Microservices Module wieder in den Kern der Diskussion zurückgekehrt. Daraus ist die Idee des modularen Monolithen entstanden, denn ein Deployment-Monolith kann natürlich auch in Module aufgeteilt sein. Er sollte sogar modularisiert sein, schließlich wäre ein System ohne Module kaum zu warten. Wenn der Microservices-Hype dazu beigetragen hat, dass Module als grundlegendes Architekturkonzept wieder mehr beachtet werden, ist das schon viel wert. Und wenn es dann noch eine Abwägung zwischen verschiedenen Modularisierungsansätzen gibt, ist das super.
Damit ergibt sich eine wichtige Frage: Wenn so viele Deployment-Monolithen schlecht strukturiert sind – warum sollte dann der nächste Deployment-Monolith besser strukturiert sein? Es geht dabei nicht darum, Deployment-Monolithen generell als schlecht abzuqualifizieren. Schließlich gibt es gut strukturierte Deployment-Monolithen. Aber bei der Vielzahl schlecht strukturierter Deployment-Monolithen muss man die Frage stellen und auch beantworten – beispielsweise durch den Einsatz eines Architekturmanagementwerkzeugs. Microservices haben zumindest den Vorteil, dass die Aufteilung erzwungen wird.
Domain-driven Design
Natürlich stellt sich die Frage, wie eine vernünftige Aufteilung in Module erreicht werden kann. Merkmale einer guten Aufteilung wie lose Kopplung sind jedem bekannt – aber sie zu erreichen, ist gar nicht so einfach. Eine Möglichkeit ist DDD.
Domain-driven Design (DDD) [6] hat seine erste Blüte circa 2005 erlebt. Damals ist es als eine Anleitung zum Entwurf objektorientierter Systeme wahrgenommen worden. Klassen wurden Repositories, Services, Entitys oder Aggregates. DDD hat so beim feingranularen Entwurf der Systeme auf Klassenebene geholfen.
Dieser Bereich ist aber nur ein Teil von DDD, das taktische Design. Heutzutage steht das strategische Design viel mehr im Mittelpunkt. Dabei geht es um die Aufteilung von Systemen in Bounded Contexts. Ein Bounded Context hat ein eigenes Domänenmodell, das von den anderen Domänenmodellen getrennt ist. So könnte es ein Domänenmodell für die Lieferung von Bestellungen geben und ein anderes für die Bezahlung. Diese beiden Domänenmodelle sind völlig unterschiedlich: So geht es bei der Bezahlung um Bezahlmöglichkeiten, die Bonität eines Kunden oder die Preise und Steuersätze von Waren. Bei der Lieferung stehen Logistikdienstleister, die Lieferadresse des Kunden oder die Größe oder das Gewicht der Waren im Mittelpunkt. Am Beispiel der Ware wird klar, dass die Domänenmodelle zwar Domänenobjekte mit derselben Bezeichnung haben, aber unterschiedliche Facetten dieser Domänenobjekte modellieren – Preise und Steuersätze in dem einen Bounded Context, Größe und Gewicht in dem anderen.
Diese grobgranulare Modularisierung und Entkopplung ist vielleicht der wichtigste Trend, den Microservices in Gang gesetzt haben. Datenbanken mit Hunderten von Tabellen, die jede auch noch eine Vielzahl von Spalten haben, ist ein Hinweis, dass ein Domänenmodell viel zu komplex geworden ist und aufgeteilt werden muss. Da können Bounded Contexts helfen. Natürlich gilt das auch, wenn gar keine Microservices genutzt werden. Also haben auch in diesem Bereich Microservices eine Diskussion in Gang gesetzt, die über Microservices hinaus relevant ist.
Langfristige Architektur
Viele Systeme überleben länger als ursprünglich geplant. Systeme müssen daher so aufgebaut werden, dass sie auch langfristig wartbar und erweiterbar bleiben. Üblicherweise versuchen Teams daher, eine „saubere“ Architektur zu definieren und durchzusetzen. Sehr viele Projekte fangen mit solchen Überlegungen an. Die Anzahl von Projekten, die am Ende mit den Konzepten auch erfolgreich ein langfristig wartbares System erstellt haben, ist allerdings gering. Daher wäre es vielleicht sinnvoll, einen anderen Ansatz auszuprobieren.
Manchmal versuchen Architekten daher, Änderungsschwerpunkte zu identifizieren, die dann besonders flexibel umgesetzt werden. Aber eine Abschätzung der Änderungshäufigkeiten kann nur auf historischen Daten beruhen. Die Zukunft ist jedoch prinzipiell schwer vorhersagbar. Oft haben Architekturen daher genau an der falschen Stelle Flexibilitäten, die dann nur die Komplexität des Systems unnötig erhöhen. Und an den Stellen, die tatsächlich geändert werden, fehlt die Flexibilität dann. Am Ende ist das System sogar noch schwieriger zu ändern.
Mit Microservices kann ein anderer Ansatz umgesetzt werden: Die fachliche Aufteilung nach Bounded Contexts ist fundamental. Bezahlung und Lieferung von Waren wird immer ein Teil eines E-Commerce-Systems sein. Und wenn das nicht mehr der Fall sein sollte, ist die Umstellung der Software vermutlich noch das kleinste Problem. Fachlich kann diese Aufteilung also auch langfristig stabil bleiben. DDD zielt zwar gar nicht auf langfristige Stabilität, sondern auf eine fachlich korrekte Aufteilung. Aber genau das ist vielleicht der beste Weg, um langfristig eine gute fachliche Architektur zu erreichen.
Für Technologien muss es aber auch einen Weg geben, das System langfristig anpassbar zu halten. Schließlich wird jede Technologie, für die sich ein Projekt entscheidet, früher oder später veraltet sein. Und irgendwann gibt es keine Sicherheitsupdates mehr. Spätestens dann ist eine Migration auf eine neue Technologie zwingend. Das System sollte in kleine Einheiten aufgeteilt werden, die unabhängig voneinander auf eine neue Version einer Technologie oder eine neue Technologie migriert werden können. So können große und risikoreiche Technology-Updates vermieden werden.
In anderen Bereichen gibt es erfolgreiche Ansätze, um alte und neue Technologien miteinander zu kombinieren. Modulare Synthesizer bestehen aus Modulen, die kombiniert werden können, um Töne zu erzeugen. Ein Standard für die Module ist Eurorack [7]. Er definiert die Kommunikation zwischen den Modulen zum Beispiel zur Kontrolle der Module und für das Timing sowie natürlich für das Audiosignal. Außerdem definiert der Standard Aspekte für den Betrieb wie die Größe der Module und die Versorgungsspannungen. Den Standard gibt es seit 1996. Mittlerweile gibt es 5 000 teilweise radikal unterschiedliche Module, die alle miteinander kombiniert werden können. Natürlich werden in den Modulen teilweise Technologien eingesetzt, die es 1996 – vor fast 25 Jahren – noch nicht gab. So können also moderne und alte Technologien problemlos kombiniert werden.
Microservices erlauben einen ähnlichen Ansatz: Ein Microservices-System muss lediglich die Kommunikation standardisieren – beispielsweise mit REST oder mit einem Messagingsystem. Außerdem muss der Betrieb durch entsprechende Regeln sichergestellt werden: So können die Microservices als Docker-Container umgesetzt werden und standardisierte Schnittstellen für Metriken oder Logging haben.
So ermöglicht ein Microservices-System heterogene Technology-Stacks, denn in den Docker-Containern können beliebige Technologien genutzt werden. Das unterstützt das Update auf eine neue Technologie: Das Update kann schrittweise für jeden einzelnen Microservice erfolgen. Das Vorgehen verringert das Risiko: Wenn es Schwierigkeiten mit der neuen Technologie gibt, tritt sie nur bei den bereits aktualisierten Microservices auf und man kann zunächst mit einem einzigen Microservice beginnen. Microservices, bei denen ein Update gar nicht lohnt, müssen nicht auf die aktuelle Technologie migriert werden, was Aufwand spart.
Eine solche schrittweise Migration kann nur funktionieren, wenn heterogene Technologiestacks möglich sind. Das ist aber eigentlich nur bei Microservices der Fall, sodass die bessere Unterstützung von Technologieupdates ein entscheidender Unterschied ist.
Continuous Delivery
Die kontinuierliche Auslieferung von Software (Continuous Delivery) [8] hat offensichtliche Vorteile. So ist eine Änderung viel schneller in Produktion, wenn die Software regelmäßig ausgeliefert wird. Daher verbessert sich die Time to Market. Mittlerweile belegt aber eine Studie [9], dass es noch viele weitere Vorteile gibt. So können Teams, die oft deployen, den Ausfall eines Service schneller beheben. Da ein Deployment auch einen erneuten Aufbau eines Service darstellt, ist dieses Ergebnis nicht so überraschend. Ebenso wenig überraschend ist es, dass Deployments weniger häufig fehlschlagen, wenn man oft deployt. Schließlich sind die deployten Änderungen nicht nur kleiner, sondern die Teams haben auch mehr Übung beim Deployment.
Aber Continuous Delivery hat weitere Vorteile: Teams, die oft deployen, investieren 50 Prozent ihrer Zeit in die Arbeit an neuen Dingen, während das bei anderen Teams nur 30 Prozent sind. Dafür arbeiten sie weniger an Sicherheitsproblemen, Fehlern oder der Unterstützung von Endnutzern. Continuous Delivery verbessert also die Produktivität der Teams. Die Studie belegt sogar, dass Unternehmen mit Continuous Delivery erfolgreicher am Markt sind und weniger mit Burn-out zu kämpfen haben. Der Grund für diese Vorteile ist vermutlich, dass durch die Erhöhung der Deployment-Geschwindigkeit die aktuellen Probleme im Softwareentwicklungsprozess offensichtlich werden und dann wegoptimiert werden können. Außerdem muss bei einem häufigen Deployment klar sein, unter welchen Bedingungen Änderungen in Produktion kommen. Zusätzlich muss der Prozess einfach ausführbar und zuverlässig sein. Eine solche Umgebung ist sicher für Mitarbeiter ebenfalls angenehmer.
Die Studie zeigt auch, wie oft Teams deployen sollten: Low Performer deployen zwischen einmal im Monat und einmal alle sechs Monate, während Elite Performer mehrmals pro Tag deployen.
Ein Projekt, das einmal im Quartal deployt, sollte also so umgestellt werden, dass es mehrfach täglich deployt, um so die vielen positiven Effekte von Continuous Delivery auszunutzen. In einem beispielhaften Szenario folgten auf die Entwicklungsphase zehn Wochen lang Tests und dann ein Release über das Wochenende. Wenn man in diesem Szenario die Tests beispielsweise durch Automatisierung um den Faktor 100 beschleunigt, dauern sie noch vier Stunden. Das Deployment würde nach einer Beschleunigung um den Faktor vier noch zwei Stunden dauern. Dann wäre man bei sechs Stunden für ein Deployment. Um mehrmals pro Tag zu deployen, müsste man noch einen Faktor von zwei oder drei erreichen. Abbildung 2 zeigt die benötigte Zeit in Relation.
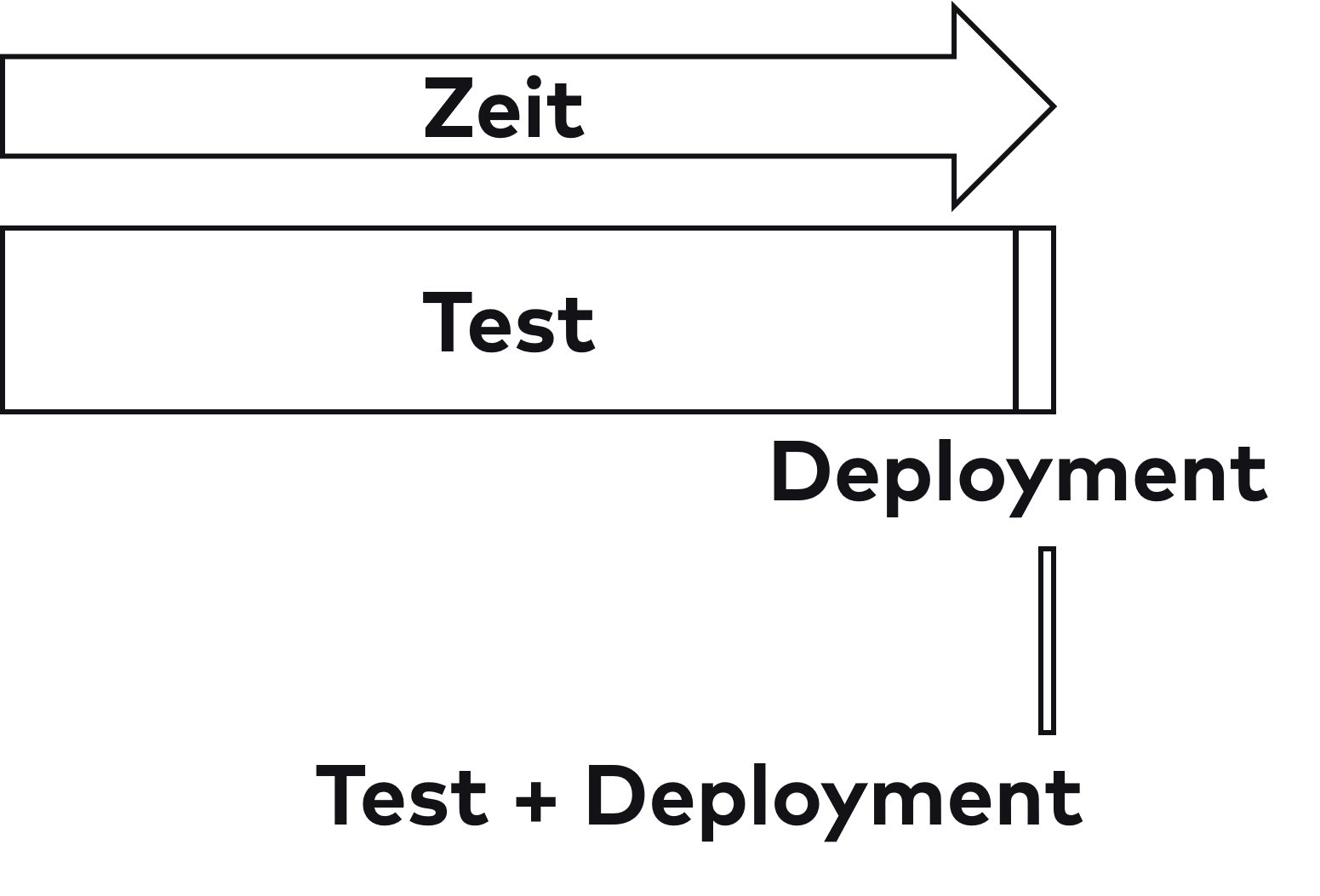
Wegen der erforderlichen extremen Beschleunigungsfaktoren ist es kaum vorstellbar, dass eine Strategie, die nur auf die Optimierung und Automatisierung der vorhandenen Prozesse setzt, zum gewünschten Erfolg führt. Tatsächlich zeigt die schon zitierte Studie, dass Verbesserungen in unterschiedlichen Bereichen notwendig sind, um die Geschwindigkeit der Deployments zu erhöhen. Zu den Maßnahmen zählt auch eine entkoppelte Architektur. Ein Ansatz dafür sind Microservices. Ohne eine Aufteilung in getrennt deploybare Module scheint das Ziel von mehreren Deployments pro Tag kaum erreichbar, obwohl es derart viele positive Auswirkungen hat. Durch Automatisierung und Optimierung allein kann man Tests kaum so stark beschleunigen. Wenn man aber die Architektur so ändert, dass ein Teil des Systems getrennt getestet und deployt werden kann, wird das Problem einfacher lösbar.
Dieses Szenario zeigt außerdem, dass die komplette Deployment-Pipeline der Microservices unabhängig sein muss – also auch und insbesondere die Tests. Ersetzt man in dem Szenario die Architektur durch Microservices, bleibt aber beim monolithischen Testansatz, ändert sich nichts.
Auf der einen Seite zeigt Continuous Delivery, dass Microservices in Isolation nicht alle Probleme lösen, sondern viele Optimierungen beispielsweise durch Automatisierungen möglich sind. Auf der anderen Seite sind hohe Deployment-Geschwindigkeiten bei komplexen Systemen wohl nur erreichbar, wenn man das System in getrennt deploybare Einheiten wie Microservices aufteilt.
Organisation
Microservices sind zwar ein Architekturansatz, aber sie können auch Auswirkungen auf die Organisation haben. Klassische Organisationen bilden oft Teams nach technischer Qualifikation, also beispielsweise ein UI-Team und ein Backend-Team. Das Gesetz von Conway besagt allerdings, dass die Architektur des Systems die Kommunikationsstrukturen kopiert. Demnach würde diese Aufteilung zur Folge haben, dass es eine UI-Komponente und eine Backend-Komponente gibt. Das passt nicht zu der fachlichen Aufteilung, die DDD predigt. Daher gibt es in der Microservices-Welt das Inverse Conway Maneuver (etwa: umgekehrtes Conway-Manöver). Fachliche Komponenten wie ein Bounded Context werden dann einem Team zugewiesen. So folgt die Organisation in Teams der angestrebten fachlichen Architektur. Natürlich wäre ein solches Vorgehen auch ohne Microservices denkbar. Aber durch Microservices kommt zu der fachlichen Unabhängigkeit der Bounded Contexts eine technische Unabhängigkeit hinzu: Jeder Microservice kann getrennt von den anderen Microservices deployt werden und andere Technologien nutzen (Abb. 3).
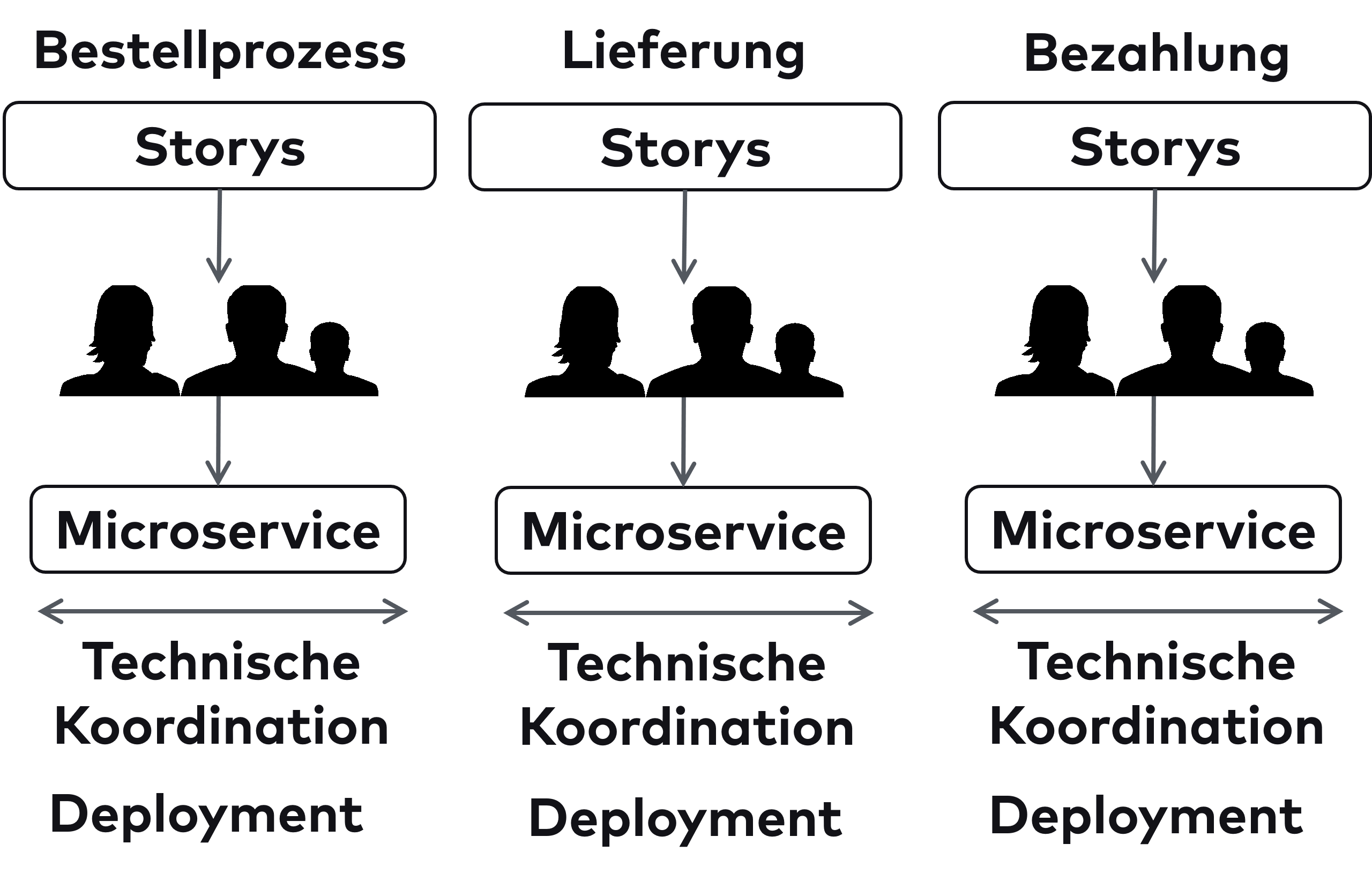
Es gibt neben Microservices und dem Inverse Conway Maneuver mehrere Ansätze, die im Kern alle dasselbe aussagen:
- DDD fordert, dass ein Bounded Context von einem Team entwickelt werden soll. Strategic Design beschreibt nicht nur, wie Bounded Contexts zusammenhängen, sondern auch mögliche Teambeziehungen.
- Agilität fordert crossfunktionale Teams. Die Teams sollen möglichst viele Fähigkeiten haben, um so möglichst unabhängig voneinander arbeiten zu können. Außerdem sollen sie sich selbst organisieren, also möglichst viele Entscheidungen selbst treffen.
- Das auf der DevOps-Studie basierende Buch „Accelerate“ [10] empfiehlt eine lose gekoppelte Architektur, um die Teams zu skalieren. Die Teams sollten die Werkzeuge wählen. Der Fokus muss auf Entwicklern und Ergebnissen liegen, nicht auf Technologien oder Werkzeugen. Microservices können das unterstützen, weil sie lose gekoppelt sind und in jedem Microservice andere Technologien genutzt werden können. Andere Ansätze wären aber auch denkbar.
Microservices haben also die Idee, dass Organisation und Architektur zusammengehören, nicht eingeführt, sondern diese Idee wird von unterschiedlichen Bereichen ins Spiel gebracht.
Microservices können unabhängige und selbstorganisierte Teams ermöglichen. Die Teams können trotz Microservices in ihrer Handlungsfähigkeit eingeschränkt sein. Wichtig ist, den Teams zu vertrauen. Nur dann wird man ihnen zugestehen, Entscheidungen selbst zu treffen. Dieser Aspekt ist vielleicht sogar wichtiger als die Umstellung der Architektur auf Microservices.
Natürlich gibt es neben der Skalierung der Organisation genügend andere Gründe für die Nutzung von Microservices. Es ist also auf keinen Fall so, dass Microservices nur für große, komplexe Systeme sinnvoll sind, sondern sie können, beispielsweise wegen der Vorteile beim Continuous Delivery, auch in kleineren Projekten sinnvoll sein.
Fazit
Microservices sind ein Hype, der mittlerweile aber abgeklungen ist und sich eher ins Gegenteil verkehrt hat. Unabhängig davon, ob man Microservices nutzt oder nicht, hat sich durch Microservices die Diskussion über Architektur geändert:
- Module und Domain-driven Design sind wieder zu wichtigen Themen geworden. Das ist sicher gut, weil eine vernünftige Modularisierung zentral für eine gute Wartbarkeit eines Systems ist.
- Für eine langlebige Architektur bieten Microservices wegen der heterogenen Technologiestacks eine gute Alternative.
- Continuous Delivery ist eine wichtige Möglichkeit, um Softwareentwicklung zu optimieren. Zumindest in einigen Fällen kann die notwendige Deployment-Geschwindigkeit nur erreicht werden, wenn man Microservices als Architekturkonzept nutzt; aber Microservices sind nur eine von vielen Optimierungen, die man ergreifen sollte.
- Die Beziehung zwischen Organisation und Architektur wird nicht nur durch Microservices in den Mittelpunkt gestellt.
So geben Microservices einige interessante Denkanstöße, die auch ohne eine vollständige Microservices-Architektur sinnvoll sein können. Denn am Ende geht es nie darum, einem Hype hinterherzulaufen, sondern immer nur um sinnvolle Architekturentscheidungen.
————-
Links & Literatur
[1] Wolff, Eberhard: „Microservices: Grundlagen flexibler Softwarearchitekturen“, dpunkt, 2015.
[2] Wolff, Eberhard: „Microservices. Ein Überblick“, https://microservices-buch.de/ueberblick.html
[3] Wolff, Eberhard: „Das Microservices-Praxisbuch: Grundlagen, Konzepte und Rezepte“, dpunkt, 2018.
[4] Wolff, Eberhard: „Microservices Rezepte – Technologien im Überblick“, https://microservices-praxisbuch.de/rezepte.html
[5] https://en.wikipedia.org/wiki/Microservices#History
[6] Evan, Eric: „Domain-Driven Design Referenz“, https://ddd-referenz.de
[7] https://en.wikipedia.org/wiki/Eurorack
[8] Wolff, Eberhard: „Continuous Delivery: Der pragmatische Einstieg“, 2. Aufl., dpunkt, 2016.
[9] https://cloud.google.com/devops/state-of-devops/
[10] Forsgren, Nicole; Humble, Jez; Kim, Gene: „Das Mindset von DevOps. Accelerate: 24 Schlüsselkompetenzen, um leistungsstarke Technologieunternehmen zu entwickeln und zu skalieren“, Vahlen, 2019.
Sessions zu Microservices:
● Spaß mit Microservices: Transaktionen
● You don’t want no microservices!
● Evolving APIs and how to implement them