
Die Idee der Code Smells ist über zwanzig Jahre alt, aber immer noch aktuell. Der Begriff wurde von Kent Beck geprägt und erlangte durch das Buch „Refactoring“ [2] von Martin Fowler eine weite Verbreitung. Fowler und Beck haben 22 Smells identifiziert und für deren Beseitigung einen umfangreichen Refactoring-Katalog erstellt. Laut der Software Craftsmanship Community gehört dieses Buch zu den Klassikern, die jeder Entwickler gelesen haben sollte, denn es verändere die Art und Weise, wie wir Software entwickeln [3]. Auch in dem Standardwerk „Clean Code“ von Robert C. Martin sind Code Smells ein fester Bestandteil. „Uncle Bob“ listet in seinem Buch nicht nur die Smells von Fowler und Beck auf, sondern ergänzt sie um seine eigenen Erfahrungen.
Fünf Kategorien
Die klassischen 22 Smells von Fowler und Beck werden ohne eine Kategorisierung oder Beziehung zueinander vorgestellt. Da einige Code Smells eng miteinander verwandt sind und die gleichen Symptome zeigen, haben Lassenius und Mäntylä in einer wissenschaftlichen Ausarbeitung vorgeschlagen, eine Kategorisierung einzuführen [4]. Das Ergebnis waren folgende fünf Kategorien: Bloaters, Change Preventers, Dispensables, Couplers und Object Orientation Abuser. Diese Kategorisierung ist mittlerweile sehr verbreitet und Code Smells lassen sich damit sehr einfach erklären. Abbildung 1 zeigt die fünf Kategorien mit der Einordnung der Code Smells, die wir in diesem Artikel näher betrachten werden.
Das Ziel ist es, eine Übersicht über die große Anzahl von Code Smells zu bekommen und erste Hinweise mitzunehmen, anhand welcher Kriterien wir sie jeweils wiedererkennen.
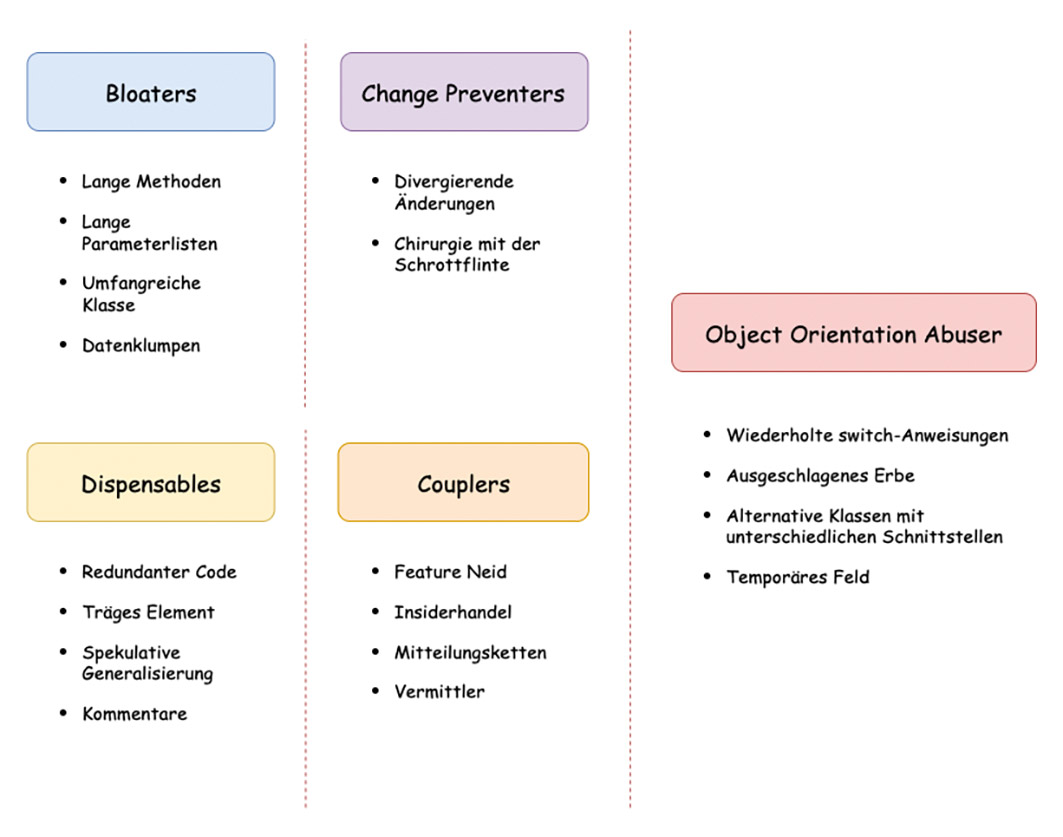
Abb. 1: Fünf Kategorien von Code Smells
Bloaters
Die Kategorie Bloaters umfasst Smells, die den Code aufblähen. Es handelt sich dabei um Strukturen, durch die der Code sehr groß und unbeweglich wird. Solche Strukturen entstehen nicht zwingend von Anfang an, sondern über eine gewisse Zeit, gerade, wenn technische Schulden nicht abgebaut werden. Ab einer bestimmten Größe des Codes wird es für Entwickler sehr schwer, Erweiterungen oder Modifikationen daran durchzuführen. Für sehr umfangreiche Codestrukturen ohne Modularität ist es schwierig bis unmöglich, sie unter Test zu bringen. Die Smells dieser Kategorie lassen sich aufgrund ihrer großen Präsenz sehr einfach erkennen.
Eine davon ist die „lange Methode“. Es ist deutlich einfacher, die Logik einer kurzen Methode als die einer langen im Kopf zu behalten. Eine Methode sollte keine 100 Zeilen und bestenfalls keine 20 Zeilen groß sein, hier waren sich Kent Beck und Robert C. Martin bereits vor zwanzig Jahren einig [5]. Ihre Empfehlung liegt bei ca. fünf Zeilen pro Methode. Fakt ist: Je kleiner die Methoden sind, desto einfacher sind sie zu verstehen und desto einfacher lassen sie sich erweitern. Dies hat sich in vielen Projekten bewährt. In der Praxis, gerade in Legacy-Systemen, kommen leider schon mal Methoden mit 1 000 Zeilen vor. Hierbei handelt es sich dann um einen sehr übelriechenden Code, der nach Verbesserung geradezu schreit.
Durch lange Methoden entstehen indirekt auch lange Parameterlisten, da die benötigten Werte auf irgendeinem Weg in die Methode gelangen müssen. Keine wirkliche Alternative ist die Verwendung globaler Daten, denn auch hier muss der Entwickler die Herkunft der Daten interpretieren und verstehen. Je länger die Parameterliste, desto höher die Komplexität. Aus Testsicht sind lange Parameterlisten sehr schwierig, denn es muss jede mögliche Konstellation mit Tests abgedeckt werden. Hier wird empfohlen, ab drei Parametern darüber nachzudenken, ob man zum Beispiel ein Parameterobjekt einführt [5].
Die „umfangreiche Klasse“, auch als „Gottobjekt“ bekannt, bezeichnet eine Klasse, die zu viel weiß oder zu viel tut. Da in so einem Konstrukt die Übersicht schnell verloren geht, schleichen sich auch gern Redundanzen ein. Ein bekanntes Prinzip, um diesem Code Smell entgegenzuwirken, ist das Single Responsibility Principle (SRP). Jede Klasse sollte nur eine Verantwortlichkeit haben.
Bei „Datenklumpen“ handelt es sich um verschiedene Datenelemente, die häufig zusammen auftreten, in Feldern, aber auch in Parameterlisten. Das Konstrukt ist meistens durch gleiche Präfixe oder Suffixe erkennbar (Abb. 2). Ein sehr einfacher Test, um Datenklumpen zu identifizieren, ist es, ein Feld aus dem Klumpen zu löschen. Wenn die Felder nicht für sich alleine stehen können, dann handelt es sich um einen Datenklumpen. Dieser Code Smell würde auch in die Kategorie „Object Orientation Abuser“ passen, denn aus jedem Datenklumpen wird eine eigene Klasse extrahiert.
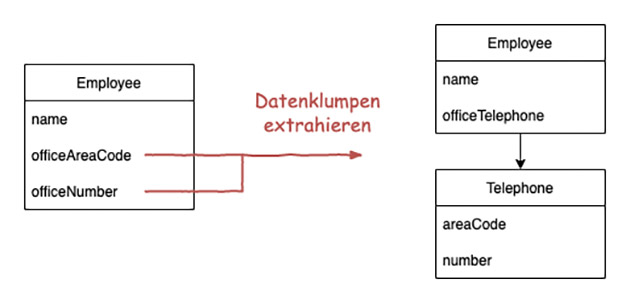
Abb. 2: Datenklumpen extrahieren
Change Preventers
Code Smells dieser Kategorie verhindern bzw. verlangsamen jegliche Erweiterung von Software. Bei einer Änderung an einer Stelle ist zwingend auch eine Änderung an einer anderen Stelle notwendig. Damit erhöht sich der Aufwand von Anpassungen drastisch. Diese Kategorie enthält zwei Code Smells, die zwar eng miteinander verwandt, aber im Grunde das genaue Gegenteil voneinander sind.
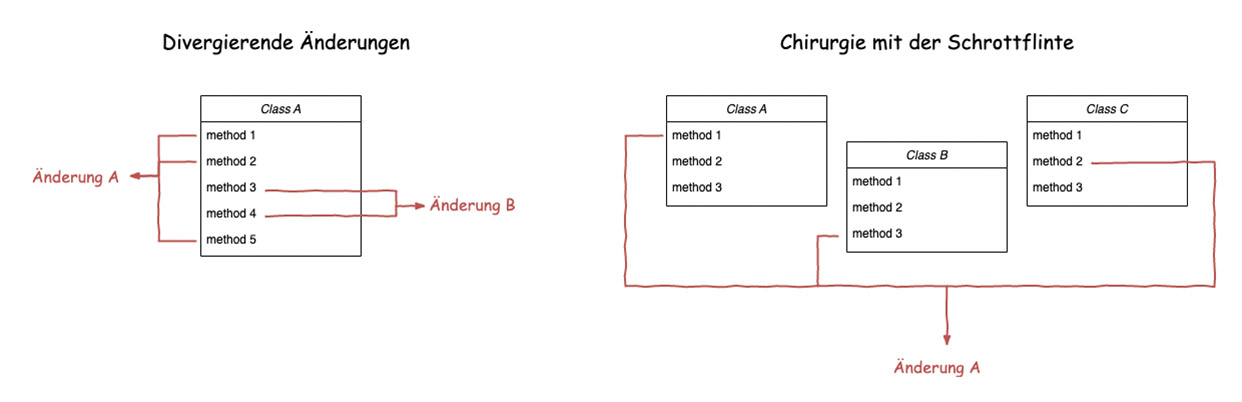
Abb. 3: Change Preventers
Wenn eine Klasse oder Methode aus verschiedenen Gründen und auf verschiedene Art und Weise immer wieder geändert wird, dann handelt es sich dabei um den Code Smell „divergierende Änderungen“. Eine Klasse wird zum Beispiel an drei Stellen geändert, um eine Datenbankänderung durchzuführen. Die gleiche Klasse muss aber auch an vier ganz anderen Stellen geändert werden, um einen neuen Datentyp einzuführen. Bei diesem Code wird das Single Responsibility Principle (SRP) verletzt. Die Klasse enthält mehrere Zuständigkeiten und sollte aufgeteilt werden.
Genau das Gegenteil von divergierenden Änderungen ist die sogenannte „Chirurgie mit der Schrotflinte“ (engl. Shotgun Surgery). Hierbei müssen bei jeder Änderung zwingend auch Anpassungen an weiteren Stellen durchgeführt werden. Die Modifikationen für die Änderung sind weit verstreut, dadurch kann es äußerst aufwendig sein, alle relevanten Stellen zu identifizieren. Um diese komplexe Struktur aufzulösen, sollte man zuallerst die schlecht voneinander getrennte Programmlogik bündeln und im Anschluss in eigene Strukturen extrahieren. Denn das oberste Ziel sollte sein, eine Änderung immer nur an einer einzigen Stelle durchführen zu müssen.
Dispensables
Die Kategorie „Dispensables“ repräsentiert entbehrlichen und sinnlosen Code. Hierzu gehören Code Smells wie „redundanter Code“, „träges Element“, „spekulative Generalisierung“ und „Kommentare“. Das Fehlen dieser Konstrukte würde den Code deutlich sauberer und leichter verständlich machen.
Redundanter Code kann in verschiedenen Ausprägungen vorkommen. Wenn es sich bei der Redundanz um komplett identischen Code handelt, dann lässt sich dieser sehr einfach identifizieren und beseitigen. Mittlerweile kann auch die IDE sehr gut unterstützen, um identischen Code über das gesamte Projekt zu finden. Handelt es sich bei den Redundanzen jedoch um ähnlichen, aber nicht vollständig identischen Code, dann kann das Identifizieren und Beseitigen schon aufwendiger werden. Eines der wichtigsten Prinzipien für sauberen Code ist das DRY-Prinzip (Don’t Repeat Yourself). Die Kernaussage ist, redundanten Code zu vermeiden.
Wenn eine Klasse zu wenig tut, sollte ihre Daseinsberechtigung hinterfragt werden. Es könnte sein, dass sie in der Vergangenheit mehr Verantwortung hatte und durch eine Überarbeitung zu einem „trägen Element“ (engl. lazy class) geworden ist. Hierbei muss man konsequent sein und das Ziel haben, unnötige Komplexität zu entfernen.
Die „spekulative Generalisierung“ entsteht, wenn Entwickler mit der Prämisse „Früher oder später brauchen wir die Funktionalität“ programmieren. Es wird Funktionalität umgesetzt, die nicht verwendet wird. Dies erhöht die Komplexität des Gesamtsystems unnötig und sollte vermieden werden. Hier gelten die zwei Prinzipien: KISS – Keep it Simple, Stupid und YAGNI – You ain’t gonna need it.
Zu Kommentaren haben Fowler und Beck eine klare Meinung: Es handele sich um Deodorant für Code Smells und sei damit selbst ein solcher [2]. Wenn Entwickler übelriechenden Code schreiben und ihnen das bewusst ist, sprühen sie etwas Deodorant drüber, indem ein Kommentar dazu verfasst wird. Daher sollten Kommentare immer kritisch betrachtet werden: Was will man damit verbergen?
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Couplers
Die Code Smells dieser Kategorie führen zu einer übermäßigen Kopplung zwischen Klassen. Für die leichte Wandelbarkeit einer Software strebt man jedoch eine möglichst lose Kopplung zwischen Bausteinen an sowie eine hohe Kohäsion (starke Bindung) innerhalb eines Bausteins [6]. Enge Kopplung führt dazu, dass Änderungen in einer Klasse automatisch auch Änderungen in einer anderen Klasse verursachen.
Zu dieser Kategorie gehören Smells wie „Featureneid“, Insiderhandel, Mitteilungsketten und Vermittler. Die letzten beiden entstehen, wenn die enge Kopplung durch eine übermäßige Delegation ersetzt wird.
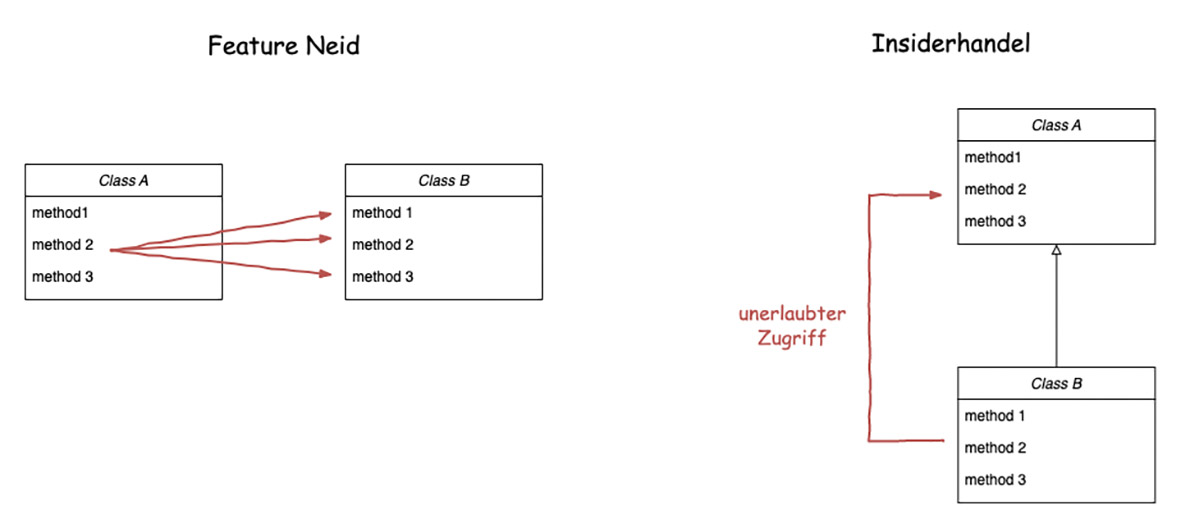
Abb. 4: Featureneid und Insiderhandel
Wenn eine Methode mehr an den Daten einer anderen Klasse interessiert ist als an den Daten der eigenen Klasse, dann sprechen wir von Featureneid (Abb. 4). Ein typisches Szenario ist beispielsweise, wenn eine Methode eine Berechnung durchführen will und dafür ein Dutzend Getter-Methoden einer anderen Klasse aufruft, um sich die Daten für die Berechnung zu holen. Bei so viel Neid sollte hinterfragt werden, ob die Methode in der richtigen Klasse ist.
Beim Insiderhandel tuscheln zwei Klassen hinter dem Rücken der offiziellen Schnittstelle. Diese Kopplung ist nicht auf Anhieb ersichtlich und nur schwer zu entdecken, da die Absprachen der Klassen heimlich erfolgen. Bei der Vererbung ist dieses Konstrukt oft zu beobachten, wenn die Unterklasse mehr über die Basisklasse weiß als notwendig. Daraufhin verschafft sich die Unterklasse einen Vorteil, in dem sie mit den Daten der Basisklasse arbeitet. In diesem Fall sollte die Vererbungshierarchie hinterfragt werden.
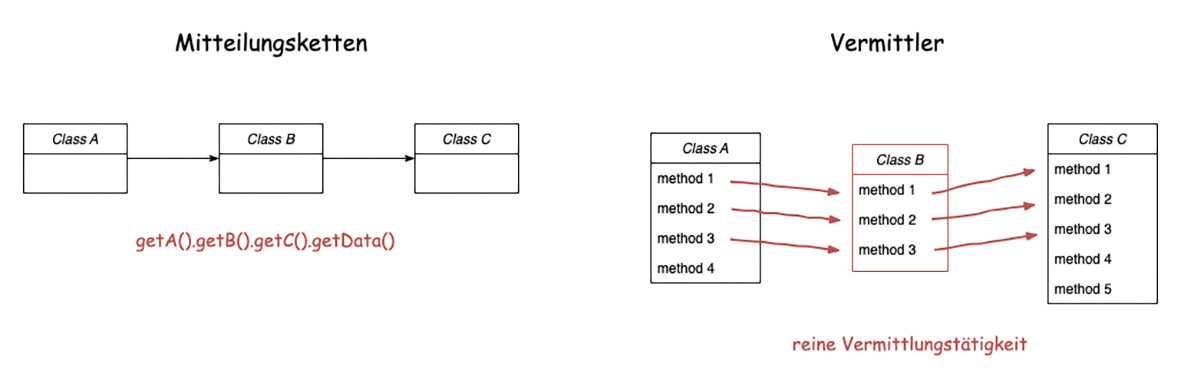
Abb. 5: Mitteilungsketten und Vermittler
Eine Mitteilungskette (Abb. 5) entsteht, wenn ein Objekt A die Daten von Objekt D benötigt und dies nur durch unnötige Navigation durch die Objekte B und C erreicht. Objekt A fragt nach Objekt B, danach das Objekt C und anschließend Objekt D mit den relevanten Daten.
A.getB().getC().getD().getTheNeededData()
Jede Änderung an den Beziehungen der beteiligten Objekte zwingt den Aufrufer ebenfalls zu einer Änderung. Durch die Refactoring-Maßnahme „Delegation verbergen“ kann die Mitteilungskette verkürzt werden. Bei Delegation verbergen muss der Aufrufer (Objekt A) nicht zwingend alle Objekte kennen, wenn zum Beispiel Objekt B die Verbindung zu Objekt C und D verbirgt.
A.getB().getTheNeededDataThroughCandD()
Somit muss bei Änderungen nicht immer der Aufrufer (Objekt A) geändert werden. Durch solch eine Maßnahme könnte aber auch der Code Smell „Vermittler“ entstehen. Wenn eine Klasse hauptsächlich aus einfachen Delegationen besteht und sonst keinen eigenen Mehrwert bietet, dann sprechen wir von einem Vermittler. Der Vermittler ist an der Stelle eine unnötige Komplexität, wir sollten versuchen, darauf zu verzichten.
Object-oriented Abuser
Diese Kategorie enthält übelriechenden Code, bei dem die objektorientierten Prinzipien falsch oder unvollständig umgesetzt wurden. Vererbung und Polymorphie sind die grundlegenden Konzepte der Objektorientierung. Wenn diese Konzepte falsch angewendet werden, so leiden darunter hauptsächlich die Wartbarkeit und Wiederverwendbarkeit. Object-oriented Abuser enthält Code Smells wie wiederholte Switch-Anweisung, alternative Klassen mit unterschiedlichen Schnittstellen und temporäres Feld.
Wenn sich Switch-Anweisungen mit identischer Steuerungslogik wiederholen, dann ist dies ein Anzeichen für das Fehlen von objektorientiertem Design. Die gleiche Fallunterscheidung anhand eines Typs ist an verschiedenen Stellen im Code verteilt. Möchte man einen weiteren Typ für die Fallunterscheidung hinzufügen, so muss man zwingend alle Switch-Anweisungen finden und dort die Erweiterung durchführen. Das ist sehr mühsam, unübersichtlich und fehleranfällig, doch das Problem lässt sich sehr elegant durch Polymorphie lösen. Wir schauen uns im nächsten Abschnitt diesen Code Smell anhand eines Beispiels etwas genauer an.
Beim ausgeschlagenen Erbe (engl. Refused Bequest) übernimmt eine Unterklasse nicht alle Daten oder Funktionen der Oberklasse, sondern unterstützt nur bestimmte Aspekte. Dazu kann es kommen, wenn die Vererbung verwendet wird, um bestimmte Aspekte der Oberklasse wiederzuverwenden, ohne dass die zwei Objekte etwas miteinander zu tun haben. Bei diesem Code Smell sollte die Vererbungshierarchie hinterfragt werden.

Klassen untereinander austauschen zu können, ist ein großer Vorteil der objektorientierten Programmierung. Dies wird durch die Verwendung von Schnittstellen erreicht. Um Klassen untereinander auszutauschen, sollte man aber auch die gleichen Schnittstellen verwenden. Der Code Smell „alternative Klassen mit unterschiedlichen Schnittstellen“ kann entstehen, wenn beim Erstellen einer Klasse eine äquivalente Klasse übersehen wird. Dann wird eine ähnliche Klasse mit einer anderen Schnittstelle erzeugt. Die Schnittstellen müssen in so einem Fall vereinheitlicht werden.
Ein nur temporär genutztes Feld in einer Klasse kann zu großer Verwirrung führen. Der Entwickler muss die Fragen „Wo wird es verwendet?“ und „Warum wird es nur da verwendet?“ klären. Das erhöht unnötig die Komplexität, denn die Erwartungshaltung ist, dass ein Objekt alle seine Felder benötigt und benutzt und das nicht nur unter bestimmten Konstellationen. Ein temporäres Feld sollte am besten in eine eigene Klasse extrahiert werden und sämtlicher Code, der mit dem Feld arbeitet, sollte auch umgezogen werden.
Der Weg zu besserem Code
Das Erkennen von übelriechendem Code ist erst die halbe Miete. Uns ist dadurch zwar bewusst, welche Konstrukte überarbeitet werden sollten, doch nun stellt sich die Frage, wie wir übelriechenden Code beseitigen, ohne die Funktionalität der Software zu gefährden.
Ein Refactoring sollte immer in kleinen Schritten durchgeführt werden. Ein großes Big Bang Refactoring geht selten gut. Bei der Überarbeitung ist eine entsprechende Testabdeckung sehr wichtig. Dies kann jedoch eine Herausforderung sein, speziell im Umfeld von Legacy Code. Aber auch für Legacy-Systeme gibt es Ansätze, um die Testabdeckung aufzubauen, z. B. kann man mit der umgedrehten Testpyramide beginnen und diese mit der Zeit drehen.
Fowler und Beck haben für jeden identifizierten Code Smell eine Anleitung verfasst, welche Schritte notwendig sind, um ihn aufzulösen. Wir schauen uns weiter unten in Listing 1 exemplarisch so ein Vorgehen an. Da die Ausprägungen von Code Smells sehr unterschiedlich sein können, ist nicht immer eine Anleitung notwendig, gerade wenn es sich um einfache Smells handelt. Erfahrungsgemäß lassen sich diese bereits durch folgende toolgestützte Refactoring-Maßnahmen beseitigen:
- Methode/Variable verschieben
- Methode/Variable umbenennen
- Methode/Variable extrahieren
- Methode/Variable inline platzieren
Diese Maßnahmen werden von der Entwicklungsumgebung (IDE) unterstützt. Es lohnt sich, diese Unterstützung der IDE im Detail zu kennen und zu verwenden, denn das gibt dem Entwickler eine zusätzliche Sicherheit beim Refactoring.
Anhand des Beispiels in Listing 1 schauen wir uns den Code Smell „wiederholte Switch-Anweisungen“ etwas genauer an. Wir analysieren zum einen die übelriechenden Stellen im Code und schauen, wie wir ihn mit Hilfe der Anleitung aus dem Refactoring-Katalog [2] verbessern können. Bei dem Beispiel handelt es sich um das Parrot-Refactoring Kata [7], das in verschiedenen Programmiersprachen existiert.
Die Klasse Parrot (engl. für Papagei) enthält zwei Methoden mit den redundanten Switch-Anweisungen. Die Methode getSpeed bestimmt die Geschwindigkeit des Papageis und die Methode getPlumage den Zustand des Federkleides. Es gibt die drei Papageientypen „European“, „African“ und „Norwegian Blue“, die unterschiedliche Ausprägungen für Geschwindigkeit und Gefieder haben. Würde ein neuer Papageientyp hinzukommen, so müsste man alle Fallunterscheidungen anpassen. Dies widerspricht dem Open Closed Principle (OCP) und lässt sich mit Polymorphie sehr gut lösen.
public class Parrot {
// ...
double getSpeed(ParrotTypeEnum type) {
switch (type) {
case EUROPEAN:
return getBaseSpeed();
case AFRICAN:
return getBaseSpeed() - getLoadFactor() * numberOfCoconuts;
case NORWEGIAN_BLUE:
return (isNailed) ? 0 : getBaseSpeed(voltage);
}
throw new RuntimeException("Should be unreachable");
}
String getPlumage(ParrotTypeEnum type) {
switch (type) {
case EUROPEAN:
return "average";
case AFRICAN:
return numberOfCoconuts > 2 ? "tired" : "average";
case NORWEGIAN_BLUE:
return voltage > 100 ? "scorched" : "beautiful";
}
throw new RuntimeException("Should be unreachable");
}
// ...
}
Bedingung durch Polymorphie ersetzen
Im Folgenden schauen wir uns in Kürze die Anleitung aus dem Refactoring-Katalog von Fowler und Beck an. Es handelt sich dabei um ein bewährtes Vorgehen zum Auflösen unseres Code Smells „wiederholte Switch-Anweisungen“.
- Klassen für die Polymorphie erstellen
- Fabrikfunktionen zur Rückgabe der richtigen Instanzen erstellen
- Im aufrufenden Code die Fabrikmethoden verwenden
- Methoden in der Unterklasse überschreiben
- Verschieben der bedingten Funktionen aus der Basisklasse in die Unterklassen
Das ganze Refactoring ist auf sehr kleine Schritte aufgeteilt. Nach jedem Schritt wird geprüft, ob der Code kompilierbar ist und die automatisierten Tests noch funktionieren.
Im ersten Schritt werden die Klassen für die Polymorphie erstellt. Das Ergebnis sind die Klassen EuropeanParrot, AfricanParrot und NorwegianParrot, die von der Oberklasse Parrot erben. Im zweiten Schritt werden die entsprechenden Fabrikfunktionen erstellt und im nächsten Schritt in die aufrufenden Stellen eingebunden. Die ersten drei Schritte haben nur die neue objektorientierte Klassenstruktur erzeugt. Die gesamte Logik ist weiterhin in der Oberklasse Parrot und wird von den Unterklassen verwendet. Dies hat den großen Vorteil, dass eine neue Klassenstruktur in bestehenden Code eingeführt werden kann, ohne die Funktionalität zu beeinträchtigen.
Im vierten Schritt überschreiben die Unterklassen die Methoden getSpeed und getPlumage und rufen vorerst über super (Listing 2) die Methoden der Oberklasse auf, in der noch immer die Switch-Anweisungen ausgeführt werden.
public class AfricanParrot extends Parrot {
// ...
@Override
public double getSpeed() {
return super.getSpeed();
}
@Override
public double getPlumage() {
return super.getPlumage();
}
}
Erst im fünften Schritt wird die Logik aus den Switch-Anweisungen in die entsprechenden Unterklassen verschoben, und das Refactoring ist fast vollbracht. Zum Schluss haben die Methoden getSpeed und getPlumage in der Parrot-Klasse keine Funktionalität mehr und können damit abstract werden. Das Ergebnis aller Schritte inklusive der Bereinigung zum Schluss zeigt Listing 3.
public abstract class Parrot {
public static Parrot createEuropeanParrot() {
return new EuropeanParrot();
}
public static Parrot createAfricanParrot( int numberOfCoconuts) {
return new AfricanParrot(numberOfCoconuts);
}
public static Parrot createNorwegianBlueParrot(double voltage,
boolean isNailed) {
return new NorwegianBlueParrot(voltage, isNailed);
}
public abstract double getSpeed();
public abstract double getPlumage();
// ...
}
public class AfricanParrot extends Parrot {
// ...
@Override
public double getSpeed() {
return Math.max(0, getBaseSpeed() - getLoadFactor() * numberOfCoconuts);
}
@Override
public String getPlumage() {
return numberOfCoconuts > 2 ? "tired" : "average";
}
// ...
}
public class EuropeanParrot extends Parrot{
// ...
@Override
public double getSpeed() {
return getBaseSpeed();
}
@Override
public String getPlumage() {
return "average";
}
// ...
}
public class NorwegianBlueParrot extends Parrot{
// ...
@Override
public double getSpeed() {
return (isNailed) ? 0 : getBaseSpeed(voltage);
}
@Override
public String getPlumage() {
return voltage > 100 ? "scorched" : "beautiful";
}
// ...
}
Dieses Vorgehen zeigt uns, wie iterativ eine komplexe Strukturänderung im Code erfolgen kann. Auch wenn die Schritte teilweise zu kleinteilig wirken, sind sie in der Praxis, wenn der Code deutlich umfangreicher ist, genau richtig. Nur durch solche kleinen Schritte und die ständige Ausführung der Tests kann ein komplexes Refactoring ohne Seiteneffekte erfolgreich durchgeführt werden.
Fazit
In diesem Artikel haben wir anhand von fünf Kategorien 18 Code Smells betrachtet. Um die schlechten Gerüche im Code wieder loszuwerden, sollte als Erstes die Testabdeckung sichergestellt werden. Weitere Sicherheit bieten toolgestützte Refactorings, mit denen bereits gute Ergebnisse erzielt werden. Bei komplexen Code Smells lohnt es sich, auf bewährtes Vorgehen zurückzugreifen. Ein Beispiel hierfür haben wir uns im Detail angeschaut.
Mit der Metapher Code Smells steht uns seit mehr als zwanzig Jahren ein Werkzeug zur Verfügung, mit dem wir schlechten Code identifizieren und bereinigen können. Wir sollten von diesen Erfahrungen profitieren und nicht alle Fehler selbst machen. Sich mit den Code Smells auseinanderzusetzen, hat zwei wesentliche Vorteile. Zum einen erkennen wir leichter die Strukturen, die überarbeitet werden sollten, und zum anderen entwickeln wir ein besseres Bewusstsein dafür, welche Fehler wir vermeiden sollten, wenn wir neuen Code schreiben. Beide Aspekte führen zu dem Ergebnis, dass die Qualität der Software besser wird.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Links & Literatur
[1] https://de.wikipedia.org/wiki/Refactoring
[2] Fowler, Martin: „Refactoring: Improving the Design of Existing Code“; Addison-Wesley, 2018
[3] Mancuso, Sandro: „The Software Craftsman: Professionalism, Pragmatism, Pride“, Pearson Education, 2014
[4] Mäntylä, M. V. and Lassenius, C.: „Subjective Evaluation of Software Evolvability Using Code Smells: An Empirical Study“, Journal of Empirical Software Engineering, vol. 11, no. 3, 2006, pp. 395–431.
[5] Martin, Robert C.: „Clean Code: A Handbook of Agile Software Craftsmanship“, Prentice Hall, 2008
[6] Starke, Gernot: „Effektive Softwarearchitekturen: Ein praktischer Leitfaden“, Hanser Fachbuch, 2002
[7] https://github.com/emilybache/Parrot-Refactoring-Kata.git




