
Die wirkliche Begründung, warum Modularisierung so wichtig ist, habe ich erst bei der Beschäftigung mit der kognitiven Psychologie gefunden. In diesem Artikel werde ich deshalb Modularisierung und kognitive Psychologie zusammenführen und Ihnen die entscheidenden Argumente an die Hand geben, warum Modularisierung uns bei der Softwareentwicklung tatsächlich hilft.
Parnas hat immer noch Recht!
In den letzten 20 bis 30 Jahren haben wir viele sehr große Softwaresysteme in Java, C++ und auch in C# und PHP entwickelt. Diese Systeme enthalten sehr viel Business Value und frustrieren Ihre Entwicklungsteams, weil sie nur noch mit immer mehr Aufwand weiterentwickelt werden können. Das inzwischen 50 Jahre alte Rezept von David Parnas, um einen Ausweg aus dieser Situation zu finden, heißt Modularisierung. Haben wir eine modulare Architektur, so heißt es, dann haben wir unabhängige Einheiten, die von kleinen Teams verstanden und zügig weiterentwickelt werden können. Zusätzlich bietet eine modulare Architektur die Möglichkeit, die einzelnen Module getrennt zu deployen, sodass unsere Architektur skalierbar wird. Genau diese Argumente tauschen wir in Diskussionen unter Architekt:innen und Entwickler:innen aus und sind uns doch immer wieder nicht einig, was wir genau mit Modularität, Modulen, modularen Architekturen und Modularisierung meinen.
In meiner Doktorarbeit habe ich mich mit der Frage beschäftigt, wie man Softwaresysteme strukturieren muss, damit Menschen bzw. unser menschliches Gehirn sich darin gut zurechtfinden. Das ist besonders deswegen wichtig, weil Entwicklungsteams einen Großteil ihrer Zeit mit dem Lesen und Verstehen von vorhandenem Code verbringen. Erfreulicherweise hat die kognitive Psychologie mehrere Mechanismen identifiziert, mit dem unser Gehirn komplexe Strukturen erfasst. Einer von ihnen liefert eine perfekte Erklärung für Modularisierung: Er heißt Chunking. Auf der Basis von Chunking können wir Modularisierung sehr viel besser beschreiben als durch Entwurfsprinzipien und Heuristiken, die sonst oft als Begründungen herangezogen werden [1]. Zusätzlich liefert uns die kognitive Psychologie zwei weitere Mechanismen: Hierarchisierung und Schemata, die weitere wichtige Hinweise für Modularisierung mitbringen.
Regelmäßig News zur Konferenz und der JAX-Community erhalten Stay tuned
Chunking ➔ Modularisierung
Damit Menschen in der Menge der Informationen, mit denen sie konfrontiert sind, zurechtkommen, müssen sie auswählen und Teilinformationen zu größeren Einheiten gruppieren. Dieses Bilden von höherwertigen Abstraktionen, die immer weiter zusammengefasst werden, nennt man in der kognitiven Psychologie Chunking (Abb. 1). Dadurch, dass Teilinformationen als höherwertige Wissenseinheiten abgespeichert werden, wird das Kurzzeitgedächtnis entlastet und weitere Informationen können aufgenommen werden.
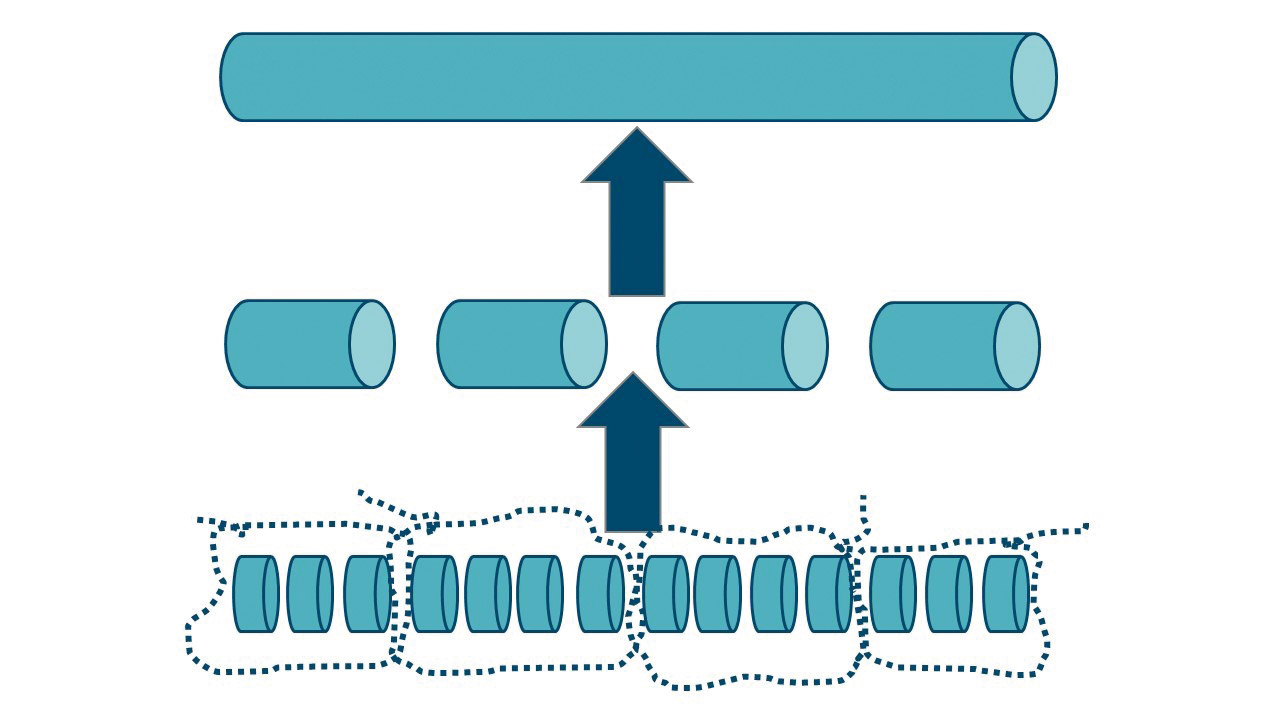
Abb. 1: Chunking
Als Beispiel soll hier eine Person dienen, die das erste Mal mit einem Telegrafen arbeitet. Sie hört die übertragenen Morsezeichen als kurze und lange Töne und verarbeitet sie am Anfang als getrennte Wissenseinheiten. Nach einiger Zeit wird sie in der Lage sein, die Töne zu Buchstaben – und damit zu neuen Wissenseinheiten – zusammenzufassen, sodass sie schneller verstehen kann, was übermittelt wird. Einige Zeit später werden aus einzelnen Buchstaben Wörter, die wiederum größere Wissenseinheiten darstellen, und schließlich ganze Sätze.
Entwickler:innen und Architekt:innen wenden Chunking automatisch an, wenn sie sich neue Software erschließen. Der Programmtext wird im Detail gelesen, und die gelesenen Zeilen werden zu Wissenseinheiten gruppiert und so behalten. Schritt für Schritt werden die Wissenseinheiten immer weiter zusammengefasst, bis ein Verständnis des Programmtexts und der Strukturen, in die er eingebettet ist, erreicht ist.
Diese Herangehensweise an Programme wird als Bottom-up-Programmverstehen bezeichnet und von Entwicklungsteams in der Regel angewendet, wenn ihnen ein Softwaresystem und sein Anwendungsgebiet unbekannt sind und sie sich das Verständnis erst erarbeiten müssen. Bei Kenntnis des Anwendungsgebiets und des Softwaresystems wird von Entwicklungsteams eher Top-down-Programmverstehen eingesetzt. Top-down-Programmverstehen bedient sich hauptsächlich der beiden strukturbildenden Prozesse Bildung von Hierarchien und Aufbau von Schemata, die in den folgenden Abschnitten eingeführt werden.
Eine andere Form des Chunking kann man bei Expert:innen beobachten. Sie speichern die neuen Wissenseinheiten nicht einzeln im Kurzzeitgedächtnis ab, sondern fassen sie direkt durch Aktivierung bereits gespeicherter Wissenseinheiten zusammen. Wissenseinheiten können allerdings nur aus anderen Wissenseinheiten gebildet werden, die für die Versuchsperson sinnvoll zusammengehören. Bei Experimenten mit Experten eines Wissensgebiets und Anfängern wurden den beiden Gruppen Wortgruppen aus dem Wissensgebiet des Experten präsentiert. Die Experten konnten sich fünfmal so viele Begriffe merken wie die Anfänger. Allerdings nur, wenn die Wortgruppen sinnvoll zusammengehörige Begriffe enthielten.
An Entwickler:innen und Architekt:innen konnten diese Erkenntnisse ebenfalls nachgewiesen werden. Chunking funktioniert auch bei Softwaresystemen nur dann, wenn die Struktur des Softwaresystems sinnvoll zusammenhängende Einheiten darstellt. Programmeinheiten, die beliebige Operationen oder Funktionen zusammenfassen, sodass für die Entwicklungsteams nicht erkennbar ist, warum sie zusammengehören, erleichtern das Chunking nicht. Der entscheidende Punkt dabei ist, dass Chunking nur dann angewendet werden kann, wenn sinnvolle Zusammenhänge zwischen den Chunks existieren.
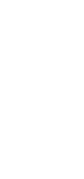
Module als zusammenhängende Einheiten
Für Modularisierung und modulare Architekturen ist es also essenziell, dass sie aus Bausteinen wie Klassen, Komponenten, Modulen, Schichten bestehen, die in sinnvoll zusammenhängenden Elementen gruppiert sind. In der Informatik gibt es eine Reihe von Entwurfsprinzipien, die diese Forderung nach zusammenhängenden Einheiten einlösen wollen:
-
Information Hiding (Geheimnisprinzip): David Parnas forderte 1972 als Erster, dass ein Modul genau eine Entwurfsentscheidung verbergen soll und die Datenstruktur zu dieser Entwurfsentscheidung in dem Modul gekapselt sein sollte (Kapselung und Lokalität). Parnas gab diesem Grundsatz den Namen Information Hiding [2].
-
Separation of Concerns: Dijkstra schrieb in seinem auch heute noch lesenswerten Artikel mit dem Titel „A Discipline of Programming“ [3], dass verschiedene Teile einer größeren Aufgabe möglichst in verschiedenen Elementen der Lösung repräsentiert werden sollten. Hier geht es also um das Zerlegen von zu großen Wissenseinheiten mit mehreren Aufgaben. In der Refactoring-Bewegung sind solche Einheiten mit zu vielen Verantwortlichkeiten als Code Smell unter dem Namen God Class wieder aufgetaucht.
-
Kohäsion: In den 1970er-Jahren arbeitete Myers seine Ideen über den Entwurf aus und führte das Maß Kohäsion ein, um den Zusammenhalt innerhalb von Modulen zu bewerten [4]. Coad und Yourdon erweiterten das Konzept für die Objektorientierung [5].
-
Responsibility-driven Design (Entwurf nach Zuständigkeit): In die gleiche Richtung wie das Geheimnisprinzip und die Kohäsion zielt Rebecca Wirfs-Brocks Entwurfsheuristik, Klassen nach Zuständigkeiten zu entwerfen: Eine Klasse ist eine Entwurfseinheit, die genau eine Verantwortung erfüllen und damit nur eine Rolle in sich vereinigen sollte [6].
-
Single Responsibility Principle (SRP): Als Erstes legt Robert Martin in seinen SOLID-Prinzipien fest, dass jede Klasse nur eine fest definierte Aufgabe erfüllen soll. In einer Klasse sollten lediglich Funktionen vorhanden sein, die direkt zur Erfüllung dieser Aufgabe beitragen. Effekt dieser Konzentration auf eine Aufgabe ist, dass es nie mehr als einen Grund geben sollte, eine Klasse zu ändern. Dafür ergänzt Robert Martin auf Architekturebene das Common Closure Principle. Klassen sollen in ihren übergeordneten Bausteinen lokal sein, sodass Veränderungen immer alle oder keine Klassen betreffen [7].
All diese Prinzipien wollen Chunking durch den inneren Zusammenhalt der Einheiten fördern. Modularität hat aber noch mehr zu bieten. Ein Modul soll nach Parnas außerdem mit seiner Schnittstelle eine Kapsel für die innere Implementierung bilden.
Module mit modularen Schnittstellen
Durch Schnittstellen kann Chunking erheblich unterstützt werden, wenn die Schnittstellen – welche Überraschung – sinnvolle Einheiten bilden. Die für Chunking benötigte Wissenseinheit kann in der Schnittstelle eines Moduls so gut vorbereitet werden, dass die Entwicklungsteams sich den Chunk nicht mehr durch die Analyse des Inneren des Moduls zusammensammeln müssen.
Eine gute zusammenhängende Schnittstelle entsteht, wenn man die Prinzipien aus dem letzten Abschnitt nicht nur beim Entwurf des Inneren eines Moduls anwendet, sondern auch für seine Schnittstelle [1], [7], [8]:
-
Explizite und kapselnde Schnittstelle: Module sollten ihre Schnittstellen explizit machen, d. h., die Aufgabe des Moduls muss klar erkennbar sein, und von der internen Implementierung wird abstrahiert.
-
Delegierende Schnittstellen und das Law of Demeter: Da Schnittstellen Kapseln sind, sollten die in ihnen angebotenen Dienste so gestaltet sein, dass Delegation möglich wird. Echte Delegation entsteht, wenn die Dienste an einer Schnittstelle Aufgaben komplett übernehmen. Dienste, die dem Aufrufer Interna zurückliefern, an denen der Aufrufer weitere Aufrufe ausführen muss, um zu seinem Ziel zu gelangen, verletzen das Law of Demeter.
-
Explizite Abhängigkeiten: An der Schnittstelle eines Moduls sollte direkt erkennbar sein, mit welchen anderen Modulen es kommuniziert. Erfüllt man diese Forderung, dann wissen Entwicklungsteams, ohne in die Implementierung zu schauen, welche anderen Module sie verstehen oder erzeugen muss, um mit dem Modul zu arbeiten. Dependency Injection passt direkt zu diesem Grundprinzip, denn es führt dazu, dass alle Abhängigkeiten über die Schnittstelle in ein Modul injiziert werden.
All diese Prinzipien haben als Ziel, dass Schnittstellen das Chunking unterstützen. Werden sie eingehalten, so sind Schnittstellen als eine Wissenseinheit schneller zu verarbeiten. Werden nun auch noch die Grundprinzipien der Kopplung beachtet, so haben wir für das Chunking beim Programmverstehen viel gewonnen.
Module mit loser Kopplung
Um ein Modul einer Architektur zu verstehen und ändern zu können, müssen sich Entwicklungsteams einen Überblick über das zu ändernde Modul selbst und seine benachbarten Module verschaffen. Wichtig sind dafür alle Module, mit denen das Modul zusammenarbeitet. Je mehr Abhängigkeiten es von einem Modul zum anderen gibt (Abb. 2), umso schwieriger wird es, die einzelnen Beteiligten mit der begrenzten Kapazität des Kurzzeitgedächtnisses zu analysieren und passende Wissenseinheiten zu bilden. Chunking fällt deutlich leichter, wenn weniger Module und Abhängigkeiten im Spiel sind.
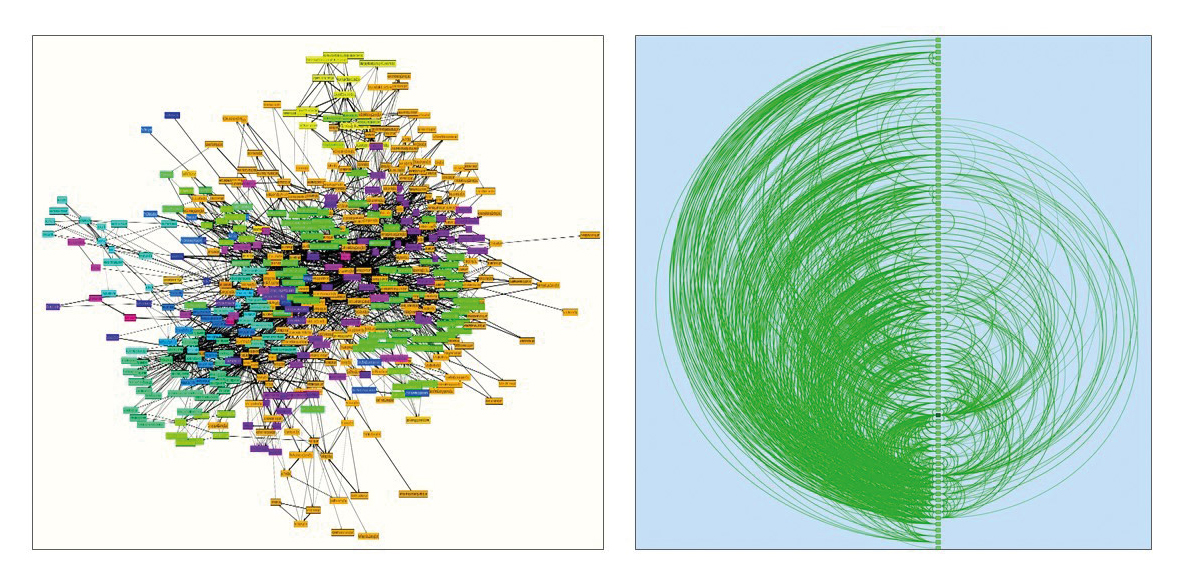
Abb. 2: Stark gekoppelte Klassen (links) oder Packages/Directories (rechts)
Lose Kopplung ist das Prinzip in der Informatik, das an diesem Punkt ansetzt [9], [10], [11]. Kopplung bezeichnet den Grad der Abhängigkeit zwischen den Modulen eines Softwaresystems. Je mehr Abhängigkeiten in einem System existieren, desto stärker ist die Kopplung. Sind die Module eines Systems nach den Prinzipien der letzten beiden Abschnitte zu Einheiten und Schnittstellen entwickelt worden, so sollte das System automatisch aus lose gekoppelten Modulen bestehen. Ein Modul, das eine zusammenhängende Aufgabe erledigt, wird dazu weniger andere Module brauchen als ein Modul, das viele verschiedene Aufgaben durchführt. Ist die Schnittstelle nach dem Law of Demeter delegierend angelegt, dann braucht der Aufrufer nur diese Schnittstelle. Er muss sich nicht von Schnittstelle zu Schnittstelle weiterhangeln, um schließlich durch viel zusätzliche Kopplung seine Aufgabe abzuschließen.
Chunking hat uns bis hierhin geholfen, Modularisierung für das Innere und das Äußere eines Moduls und für seine Beziehung zu betrachten. Spannenderweise spielt auch der nächste kognitive Mechanismus in das Verständnis von Modularisierung hinein.
Modularisierung durch Muster
Der effizienteste kognitive Mechanismus, den Menschen einsetzen, um komplexe Zusammenhänge zu strukturieren, sind sogenannte Schemata. Unter einem Schema werden Konzepte verstanden, die aus einer Kombination von abstraktem und konkretem Wissen bestehen. Ein Schema besteht auf der abstrakten Ebene aus den typischen Eigenschaften der von ihm schematisch abgebildeten Zusammenhänge. Auf der konkreten Ebene beinhaltet ein Schema eine Reihe von Exemplaren, die prototypische Ausprägungen des Schemas darstellen. Jeder von uns hat beispielsweise ein Lehrerschema, das abstrakte Eigenschaften von Lehrer:innen beschreibt und als prototypische Ausprägungen Abbilder unserer eigenen Lehrer:innen umfasst.
Haben wir für einen Zusammenhang in unserem Leben ein Schema, können wir die Fragen und Probleme, mit denen wir uns gerade beschäftigen, sehr viel schneller verarbeiten als ohne Schema. Schauen wir uns ein Beispiel an: Bei einem Experiment wurden Schachmeister:innen und Schachanfänger:innen für ca. fünf Sekunden Spielstellungen auf einem Schachbrett gezeigt. Handelte es sich um eine sinnvolle Aufstellung der Figuren, so waren die Schachmeister:innen in der Lage, die Positionen von mehr als zwanzig Figuren zu rekonstruieren. Sie sahen Muster von ihnen bekannten Aufstellungen und speicherten sie in ihrem Kurzzeitgedächtnis. Die schwächeren Spieler:innen hingegen konnten nur die Position von vier oder fünf Figuren wiedergeben. Die Anfänger:innen mussten sich die Position der Schachfiguren einzeln merken. Wurden die Figuren den Schachexpert:innen und Schachlaien allerdings mit einer zufälligen Verteilung auf dem Schachbrett präsentiert, so waren die Schachmeister:innen nicht mehr im Vorteil. Sie konnten keine Schemata einsetzen und sich so die für sie sinnlose Verteilung der Figuren nicht besser merken.
Die in der Softwareentwicklung vielfältig eingesetzten Entwurfs- und Architekturmuster nutzen die Stärke des menschlichen Gehirns, mit Schemata zu arbeiten. Haben Entwickler:innen und Architekt:innen bereits mit einem Muster gearbeitet und daraus ein Schema gebildet, so können sie Programmtexte und Strukturen schneller erkennen und verstehen, die nach diesen Mustern gestaltet sind. Der Aufbau von Schemata liefert für das Verständnis von komplexen Strukturen also entscheidende Geschwindigkeitsvorteile. Das ist auch der Grund, warum Muster in der Softwareentwicklung bereits vor Jahren Einzug gefunden haben.
In Abbildung 3 sieht man ein anonymisiertes Tafelbild, das ich mit einem Team entwickelt habe, um seine Muster aufzunehmen. Auf der rechten Seite von Abbildung 3 ist der Source Code im Architekturanalysetool Sotograph in diese Musterkategorien eingeteilt und man sieht sehr viele grüne und einige wenige rote Beziehungen. Die roten Beziehungen gehen von unten nach oben gegen die durch die Muster entstehende Schichtung. Die geringe Anzahl der roten Beziehungen ist ein sehr gutes Ergebnis und zeugt davon, dass das Entwicklungsteam seine Muster sehr konsistent einsetzt.
Abb. 3: Muster auf Klassenebene = Mustersprache
Spannend ist außerdem, welchen Anteil des Source Codes man Mustern zuordnen kann und wie viele Muster das System schlussendlich enthält. Lassen sich 80 Prozent oder mehr des Source Codes Mustern zuordnen, dann spreche ich davon, dass dieses System eine Mustersprache hat. Hier hat das Entwicklungsteam eine eigene Sprache erschaffen, um sich die Diskussion über seine Architektur zu erleichtern.
Die Verwendung von Mustern im Source Code ist für eine modulare Architektur besonders wichtig. Wir erinnern uns: Für das Chunking war es entscheidend, dass wir sinnvoll zusammenhängende Einheiten vorfinden, die eine gemeinsame Aufgabe haben. Wie, wenn nicht durch Muster, lassen sich die Aufgaben von Modulen beschreiben? Modularisierung wird durch den umfassenden Einsatz von Mustern vertieft und verbessert, wenn für die jeweiligen Module erkennbar ist, zu welchem Muster sie gehören, und die Muster konsistent eingesetzt werden.
Hierarchisierung ➔ Modularisierung
Der dritte kognitive Mechanismus, die Hierarchisierung, spielt beim Wahrnehmen und Verstehen von komplexen Strukturen und beim Abspeichern von Wissen ebenfalls eine wichtige Rolle. Menschen können Wissen dann gut aufnehmen, es wiedergeben und sich darin zurechtfinden, wenn es in hierarchischen Strukturen vorliegt. Untersuchungen zum Lernen von zusammengehörenden Wortkategorien, zur Organisation von Lernmaterialien, zum Textverstehen, zur Textanalyse und zur Textwiedergabe haben gezeigt, dass Hierarchien vorteilhaft sind. Bei der Reproduktion von Begriffslisten und Texten war die Gedächtnisleistung der Versuchspersonen deutlich höher, wenn ihnen Entscheidungsbäume mit kategorialer Unterordnung angeboten wurden. Lerninhalte wurden von den Versuchspersonen mit Hilfe von hierarchischen Kapitelstrukturen oder Gedankenkarten deutlich schneller gelernt. Lag keine hierarchische Struktur vor, so bemühten sich die Versuchspersonen, den Text selbstständig hierarchisch anzuordnen. Die kognitive Psychologie zieht aus diesen Untersuchungen die Konsequenz, dass hierarchisch geordnete Inhalte für Menschen leichter zu erlernen und zu verarbeiten sind und dass aus einer hierarchischen Struktur effizienter Inhalte abgerufen werden können.
Die Bildung von Hierarchien wird in Programmiersprachen bei den Enthalten-Sein-Beziehungen unterstützt: Klassen sind in Packages oder Directories, Packages/Directories wiederum in Packages/Directories und schließlich in Projekten bzw. Modulen und Build-Artefakten enthalten. Diese Hierarchien passen zu unseren kognitiven Mechanismen. Sind die Hierarchien an die Muster der Architektur angelehnt, so unterstützen sie uns nicht nur durch ihre hierarchische Strukturierung, sondern sogar auch noch durch Architekturmuster.
Schauen wir uns dazu einmal ein schlechtes und ein gutes Beispiel an: Stellen wir uns vor, ein Team hat für sein System festgelegt, dass es aus vier Modulen bestehen soll, die dann wiederum einige Submodule enthalten sollen (Abb. 4).
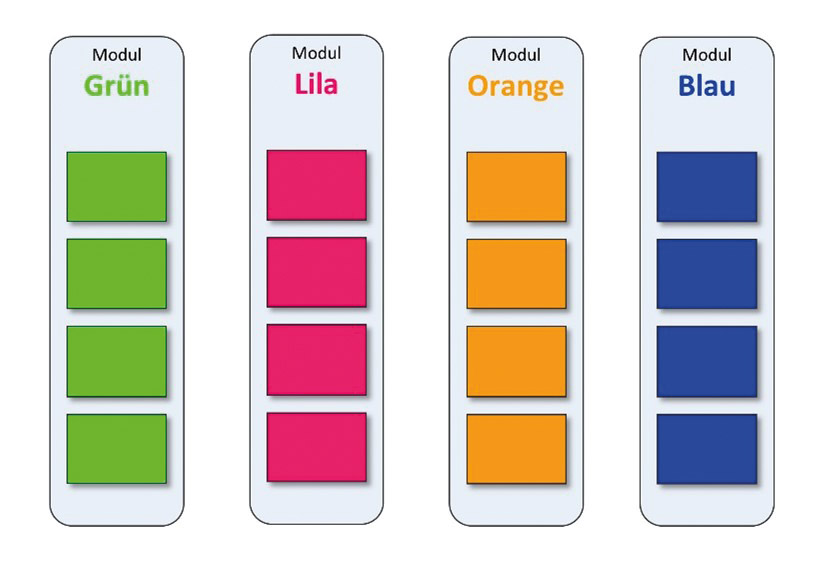
Abb. 4: Architektur mit vier Modulen
Diese Struktur gibt für das Entwicklungsteam ein Architekturmuster aus vier Modulen auf der obersten Ebene vor, in denen jeweils weitere Module enthalten sind. Stellen wir uns nun weiter vor, dass dieses System in Java implementiert und aufgrund seiner Größe in einem einzigen Eclipse-Projekt organisiert ist. In diesem Fall würde man erwarten, dass dieses Architekturmuster aus vier Modulen mit Submodulen sich im Package-Baum des Systems wiederfinden sollte.
In Abbildung 5 sieht man den anonymisierten Package-Baum eines Java-Systems, für das das Entwicklungsteam genau diese Aussage gemacht hatte: „Vier Module mit Submodulen, das ist unsere Architektur!“. In der Darstellung in Abbildung 5 sieht man Packages und Pfeile. Die Pfeile gehen jeweils vom übergeordneten Package zu seinen Kindern.
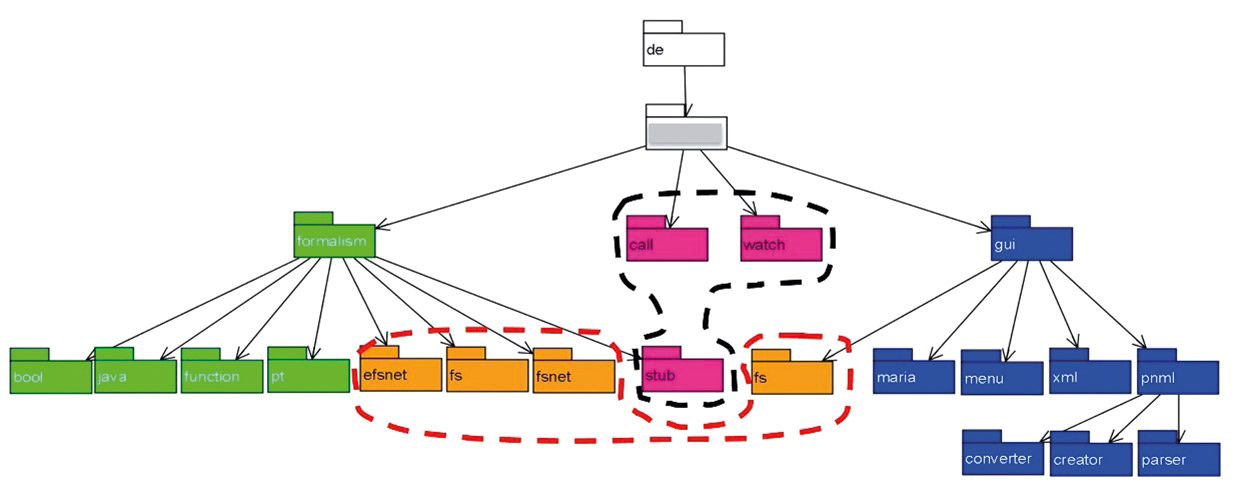
Abb. 5: Das geplante Architekturmuster ist schlecht umgesetzt
Tatsächlich findet man die vier Module im Package-Baum. In Abbildung 5 sind sie in den vier Farben markiert, die die Module in Abbildung 4 haben (grün, orange, lila und blau). Allerdings sind zwei der Module über den Package-Baum verteilt und ihre Submodule sind zum Teil sogar unter fremden Ober-Packages einsortiert. Diese Umsetzung im Package-Baum ist nicht konsistent zu dem von der Architektur vorgegebenen Muster. Sie führt bei Entwicklern und Architekten zu Verwirrung. Das Einführen von jeweils einem Package-Root-Knoten für die orange- und die lilafarbene Komponente würde hier Abhilfe schaffen.
Eine bessere Abbildung des Architekturmusters auf den Package-Baum sieht man in Abbildung 6. Bei diesem System ist das Architekturmuster symmetrisch auf den Package-Baum übertragbar. Hier können die Entwickler sich anhand der hierarchischen Struktur schnell zurechtfinden und vom Architekturmuster profitieren.
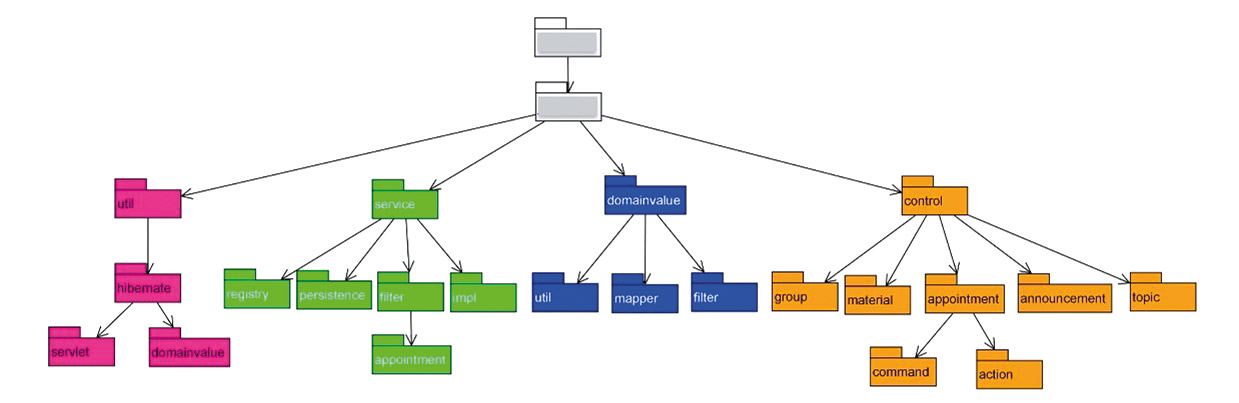
Abb. 6: Gut umgesetztes Architekturmuster
Wird die Enthalten-Sein-Beziehung richtig eingesetzt, so unterstützt sie unseren kognitiven Mechanismus Hierarchisierung. Für alle anderen Arten von Beziehungen gilt das nicht: Wir können beliebige Klassen und Interfaces in einer Source-Code-Basis per Benutzungs- und/oder per Vererbungsbeziehung miteinander verknüpfen. Dadurch erschaffen wir verflochtene Strukturen (Zyklen), die in keiner Weise hierarchisch sind. Es bedarf einiges an Disziplin und Anstrengung, Benutzungs- und Vererbungsbeziehung hierarchisch zu verwenden. Verfolgt das Entwicklungsteam von Anfang an dieses Ziel, so sind die Ergebnisse in der Regel nahezu zyklenfrei. Ist der Wert von Zyklenfreiheit nicht von Anfang an klar, entstehen Strukturen wie in Abbildung 7.
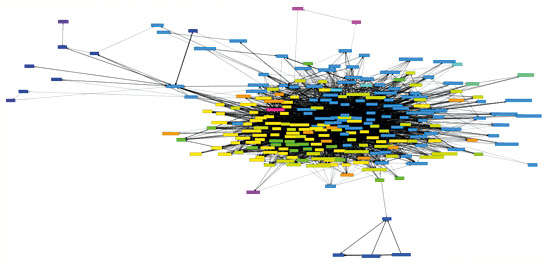
Abb. 7: Zyklus aus 242 Klassen
Der Wunsch, Zyklenfreiheit zu erreichen, ist aber kein Selbstzweck! Es geht nicht darum, irgendeine technisch strukturelle Idee von „Zyklen müssen vermieden werden“ zu befriedigen. Vielmehr wird damit das Ziel verfolgt, eine modulare Architektur zu entwerfen.
Achtet man bei seinem Entwurf darauf, dass die einzelnen Bausteine modular, also jeweils genau für eine Aufgabe zuständig sind, dann entstehen in der Regel von selbst zyklenfreie Entwürfe und Architekturen. Ein Modul, das Basisfunktionalität zur Verfügung stellt, sollte nie Funktionalität aus den auf ihm aufbauenden Modulen benötigen. Sind die Aufgaben klar verteilt, dann ist offensichtlich, welches Modul welches andere Modul benutzen muss, um seine Aufgabe zu erfüllen. Eine umgekehrte und damit zyklische Beziehung entsteht erst gar nicht.
Regelmäßig News zur Konferenz und der JAX-Community erhalten Stay tuned
Zusammenfassung: Regeln für Modularisierung
Mit den drei kognitiven Mechanismen Chunking, Schemata und Hierarchisierung haben wir das Hintergrundwissen bekommen, um Modularisierung in unseren Diskussionen klar und eindeutig zu verwenden. Eine gut modularisierte Architektur besteht aus Modulen, die den Einsatz von Chunking, Hierarchisierung und Schemata erleichtern. Zusammenfassend können wir die folgenden Regeln festlegen: Die Module einer modularen Architektur müssen
-
In ihrem Inneren ein zusammenhängendes, kohärentes Ganzes bilden, das für genau eine klar definierte Aufgabe zuständig ist (Einheit als Chunk),
-
Nach außen eine explizite, minimale und delegierende Kapsel bilden (Schnittstelle als Chunk),
-
Nach einheitlichen Mustern durchgängig gestaltet sein (Musterkonsistenz) und
-
Mit anderen Modulen minimal, lose und zyklenfrei gekoppelt sein (Kopplung zur Chunk-Trennung und Hierarchisierung).
Sind dem Entwicklungsteam diese Mechanismen und ihre Umsetzung in der Architektur klar, ist eine wichtige Grundlage für Modularisierung gelegt.
Links & Literatur
[1] Dieser Artikel ist ein überarbeiteter Auszug aus meinem Buch: Lilienthal, Carola: „Langlebige Softwarearchitekturen. Technische Schulden analysieren, begrenzen und abbauen“; dpunkt.verlag, 2019
[2] Parnas, David Lorge: „On the Criteria to be Used in Decomposing Systems in-to Modules“; in: Communications of the ACM (15/12), 1972
[3] Dijkstra, Edsger Wybe: „A Discipline of Programming“; Prentice Hall, 1976
[4] Myers, Glenford J.: „Composite/Structured Design“; Van Nostrand Reinhold, 1978
[5] Coad, Peter; Yourdon, Edward: „OOD: Objektorientiertes Design“; Prentice Hall, 1994
[6] Wirfs-Brock, Rebecca; McKean, Alan: „Object De-sign: Roles, Responsibilities, and Collaborations“; Pearson Education, 2002
[7] Martin, Robert Cecil: „Agile Software Development, Principles, Patterns, and Practices“; Prentice Hall International, 2013
[8] Bass, Len; Clements, Paul; Kazman, Rick: „Software Architecture in Practice“; Addison-Wesley, 2012
[9] Booch, Grady: „Object-Oriented Analysis and Design with Applications“; Addison Wesley Longman Publishing Co., 2004
[10] Gamma, Erich; Helm, Richard; Johnson, Ralph E.; Vlissides, John: „Design Patterns. Elements of Reusable Object-Oriented Software“; Addison-Wesley, 1994
[11] Züllighoven, Heinz: „Object-Oriented Construction Handbook“; Morgan Kaufmann Publishers, 2005




