

Wer sind wir? Die LucaNet AG hat sich auf den Bereich Finanzsoftware für Konzerne für deren Konsolidierung, Planung, Analyse und Reporting spezialisiert. Seit 1999 entwickelt LucaNet die Softwarelösungen stetig weiter und versucht, den stets wachsenden Anforderungen der Kunden gerecht zu werden und die bestmögliche Performance zu liefern. Die Softwarelösung der LucaNet AG ist eine Client-Server-Anwendung, in der je nach Unternehmensgröße bis zu mehreren Hundert Personen parallel auf einem sehr komplexen Datenmodell arbeiten, das die ganze Zeit im Speicher gehalten wird.
Der Monolith
Am Anfang steht immer eine Idee. Dann schreibt man etwas Software und daraus entwickelt sich eine Applikation gemäß den Paradigmen und Möglichkeiten der Zeit. In den folgenden Jahren werden mehr und mehr Features entwickelt, um die schnell wachsenden Kundenanforderungen zu bedienen. Es bleibt keine Zeit (oder es wird sich keine Zeit genommen) für Wartungsarbeiten oder ein klassisches Refactoring. Die Kunden sind zufrieden mit dem Umfang und der Leistungsfähigkeit der Anwendung – warum sollte man also etwas anders machen? Einige Jahre und viele Personenjahre Aufwand später ist aus der kleinen Applikation eine ausgewachsene Businessanwendung geworden. Unzählige Lines of Code, Klassen, Module usw., die zwar wunderbar funktionieren, aber nur von wenigen „alten Hasen“ wirklich verstanden und gewartet werden können. Aber auch eine ganze Reihe von Hacks und Bugfixes, die das ursprüngliche Architekturpattern unterwandern. Häufig fällt in so einem Umfeld die Floskel „Das ist historisch gewachsen“. Das Muster dürfte den meisten von euch bekannt vorkommen. Denn diese Situation gibt es bei (fast) jedem Softwaresystem, das sehr erfolgreich ist und über viele Jahre weiterentwickelt wurde.
Doch warum nennen wir so etwas Monolith? Das Wort Monolith kommt aus dem Griechischen und heißt so viel wie „einheitlicher Stein“, und wir finden die Analogie sehr passend für Softwaresysteme, die von außen betrachtet undurchdringbar und schwer veränderlich sind. Daraus resultiert auch, dass sich einzelne Teile nur schwer aktualisieren lassen und so gut wie unmöglich herauszutrennen sind.
Regelmäßig News zur Konferenz und der JAX-Community erhalten Stay tuned
Alles neu?
Wir sind alle Entwickler und Technologieenthusiasten und daher kommen wir sehr schnell zu der Überzeugung, dass mit Framework X oder Technologie Y alle Probleme schnell gelöst werden und damit auch ganz neuen Herausforderungen und Anforderungen leicht entsprochen werden kann. Einige wollen auch dafür eigene Technologien entwickeln, was gar nicht mal ungewöhnlich ist – man liest und hört nur sehr wenig von diesen Ansätzen. Die meisten Seniorentwickler schreiben die gleiche Art von Anwendung oder lösen die gleiche Art von Problemen Tag für Tag, Jahr um Jahr. Das ist manchmal langweilig, und was gibt es Spannenderes, als ein eigenes Framework zu schreiben? Vielleicht sogar mit der Absicht, es danach als Open-Source-Software zu veröffentlichen? Die Antwort ist: Wahrscheinlich ist es superspannend, aber bringt es unsere Anwendung wirklich weiter? Und viel wichtiger: Lösen wir damit überhaupt die aktuellen Probleme?
Um diese Fragen zu beantworten, müssen die Anwendung und ihre Architektur erst einmal überprüft werden. Bei einer solchen Architekturreview, die idealerweise von Externen durchgeführt wird, hat sich in der Praxis ATAM [1] als Methode bewährt. Dieser Artikel ist zu kurz, um auf ATAM einzugehen, aber ganz kompakt formuliert, definiert man via Szenarien Qualitätsanforderungen an den Sollzustand der Architektur und vergleicht diesen dann mit dem Istzustand des Systems. Das klingt erst einmal furchtbar aufwendig und teuer, daher wird die Investition oft gescheut. Jedoch stehen die Kosten aus unserer Erfahrung in keinem Verhältnis zu den Kosten (über den Lifecycle) einer nicht passenden Architektur oder Technologiewahl. Ähnlich wie bei Fahrzeugen sollte daher ein regelmäßiger TÜV der Architektur zu einer reifen Produktentwicklung dazugehören.
Den Monolithen erwürgen
Wenn man bei der Review zu der Erkenntnis gelangt, dass die aktuelle Architektur nicht mehr lange weiterentwickelt und gewartet werden kann, muss man handeln. Aus der Definition oben lässt sich schon ableiten, dass man den Monolithen nicht einfach in ein paar Teile zerlegen und diese dann separat weiterentwickeln kann. Es ist aber auch so gut wie nie möglich, die Entwicklung an dem aktuellen System zu stoppen, zwei bis drei Jahre lang eine neue Architektur zu entwickeln, um dann das neue System präsentieren zu können. Wir müssen also das bestehende System, den Monolithen, zumindest vorübergehend in das neue Gesamtsystem integrieren.
Bei der Umstellung von Monolithen auf Microservices gibt es das sogenannte Strangler Pattern (Kasten: „Strangler Pattern ) [2]. LucaNet entwickelt ein Produkt, das auch on-premise, das heißt direkt beim Kunden, installiert werden kann. Hier kommt für uns ein Microservices-Ansatz nicht infrage. Die Strategie für die Umstellung ist, dass das Produkt technologisch und architektonisch so einfach wie möglich gehalten wird. Das Produkt muss von der Kunden-IT, aber natürlich auch durch uns leicht integrierbar und leicht zu betreiben sein. Das Pattern ist trotzdem sehr interessant, und wir werden es leicht abgewandelt in unsere Strategie einbringen.
Strangler Pattern
Das Strangler Pattern beschreibt kurz gesagt ein Vorgehen, bei dem Stück für Stück Teile eines Monolithen herausgetrennt und als Microservices in die Gesamtarchitektur eingebracht werden. Für unser Vorhaben wandeln wir dieses Vorgehen leicht ab. Den Monolithen selbst können wir nicht umbauen und nur schwer verändern. Wir werden den neu zu entwickelnden Server vor den Monolithen setzen und alle Requests darüber laufen lassen. Damit können transparent Funktionen in den neuen Server eingebaut werden und die alten Funktionen werden einfach nicht mehr angesteuert. An einem bestimmten Punkt in der Entwicklung wird der alte Monolith schließlich überflüssig sein – er wurde quasi Stück für Stück „erwürgt“ (engl. to strangle).
Das grundsätzliche Vorgehen war damit recht schnell gesetzt. Es wird ein neues User Interface entwickelt und der bisherige Monolith muss um notwendige Schnittstellen für den Zugriff erweitert werden. An dieser Stelle kommt dafür nur REST infrage, da wir damit im Front-end komplett technologieunabhängig sind. Das neue Frontend soll natürlich nicht einfach an das bestehende Backend angebunden werden, da wir sonst so gut wie keine Fortschritte gemacht haben. Schlimmstenfalls ist eine weitere Komponente von dem Big Ball of Mud abhängig.
Evolution statt Revolution
Es müssen jetzt zwei Dinge gleichzeitig entwickelt werden: zum einen das neue Frontend und zum anderen die entsprechenden Schnittstellen im Backend. Damit beides wirklich parallel und ohne große Störungen geschehen kann, haben wir uns für einen API-First-Ansatz entschieden. Da jetzt schon klar ist, dass der Monolith nicht so bleibt, wie er ist, muss er vom Frontend entkoppelt werden. Auch muss das neue JavaScript Frontend von einem Server ausgeliefert werden. Die erste Entscheidung war also auch eine der wichtigsten: Welchen Server bzw. welches Framework sollen wir verwenden (Kasten: „Entscheidungsprozess“)?
Entscheidungsprozess
Als Entwickler sind wir bei der Technologiewahl schnell bei den neuesten Technologien und Frameworks (aka „der neueste heiße Scheiß“). Anders als bei Start-ups, kleineren Projekten oder reinen Webapplikationen müssen wir hier von vornherein über viel größere Zeithorizonte nachdenken. Einer der wichtigsten Punkte bei der Szenariendefinition für die neue Architektur war Langlebigkeit, die zukünftige Architektur soll mindestens zehn Jahre halten. Natürlich kann heute nicht alles für die nächsten zehn Jahre antizipiert werden, aber die Architektur muss in der Lage sein, Veränderungen zu unterstützen [3], dabei aber so stabil bleiben, dass wir nicht befürchten müssen, dass es das Framework in drei Jahren nicht mehr gibt, die Maintainer keine Lust mehr haben oder ein Versionswechsel ein halbes Jahr Arbeit nach sich zieht. Häufig bedeutet das, je langweiliger die Technologie, desto besser. Außerdem sollten bei der Technologiewahl auch der Einsatz und die Wahrung von konzeptionellen Standards Berücksichtigung finden. Jakarta EE (früher Java EE) und insbesondere der MicroProfile-Standard erfüllen den Anspruch von Stabilität, Flexibilität und – entsprechend den Architekturzielen – auch der Nachhaltigkeit. Mittlerweile gibt es einige sehr spannende Umsetzungen des MicroProfile-Standards, weshalb die Lösung gar nicht so langweilig sein muss.
Wir haben uns nach der Evaluation für Quarkus [4] entschieden. Auch wenn das ein relativ neuer Server ist, haben uns hier mehrere Aspekte überzeugt. Zum Teil machte die Entscheidung aus, dass Quarkus ein MicroProfile-Server ist, wir uns also nicht direkt an ein Produkt binden, sondern an einen Standard. Im schlimmsten Fall können wir einen anderen MicroProfile-Server (z. B. Payara, Open Liberty, … ) nehmen und unsere Anwendung mit wenigen Anpassungen damit laufen lassen. Weiterhin ist die Dokumentation dieses Servers exzellent und die Verwendbarkeit denkbar einfach. Es wurde auch nicht alles neu erfunden, sondern man hat sich dediziert für ausgereifte Bibliotheken und Frameworks, wie z. B. Vert.x, entschieden. Das ermöglicht uns wiederum, bei einem potenziellen Serverwechsel diese Bibliotheken oder Frameworks als Third-party Dependency einzubinden, falls wir deren Features verwenden.
Die nächste große Herausforderung ist die Tatsache, dass wir auch bisher keine Microservices hatten bzw. das Produkt direkt beim Kunden im eigenen Datacenter läuft. Die Idee ist, dass wir den MicroProfile-Server zwischen das Frontend und den Monolithen setzen. Quarkus fungiert nun als Anti-corruption Layer (Kasten: „Anti-corruption Layer). Egal wie sehr sich die Schnittstellen im Monolithen ändern werden, nach außen hin wird immer noch das gleiche REST-Interface bedient. Wir können mit diesem Ansatz die Frontend-Entwicklung sogar beschleunigen, indem wir eine Pseudoimplementierung der Schnittstelle Testdaten ausliefern lassen. Das Frontend kann also schon alle Methoden mit unterschiedlichen Parametern aufrufen und wir erhalten in einem sehr begrenzten Umfang Testdaten als Antwort.
Anti-corruption Layer
Das Konzept des Anti-corruption Layers kommt ursprünglich aus dem Domain-driven Design [5]. Hier geht es darum, einen Bounded Context von einem anderen Bounded Context abzugrenzen. Der Anti-corruption Layer sorgt dann dafür, dass Änderungen in Bounded Context A keine ungewollten Änderungen im Bounded Context B verursachen.
Wir wollen mit dem Anti-corruption Layer nicht nur einzelne Bounded Contexts voneinander abgrenzen, sondern den bisherigen Monolithen über neue Schnittstellen isolieren. Mit diesem neuen Layer sind wir auch in der Lage, das Backend jederzeit teilweise oder sogar ganz auszutauschen. Features können so jeweils Stück für Stück in Quarkus selbst wandern und dadurch die Aufrufe in den Monolithen überflüssig machen (Abb. 1). Das hat für uns den weiteren Vorteil, dass wir bei der Entwicklung bereits Erfahrungen mit dem neu zu entwickelnden Backend sammeln können, ohne ein Risiko für den Kunden zu generieren. Somit steuern wir nicht auf ein Big Bang Release zu, sondern erarbeiten eine Umstellung auf ein gut getestetes Backend. Die Umstellung selbst wurde bis dahin vielfach getestet, was uns zusätzliche Sicherheit für den finalen Schritt gibt.
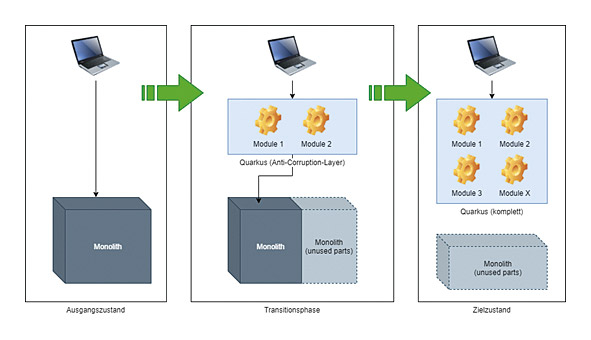
Abb. 1: Schrittweise Ablösung des Monolithen
Nieder mit dem Monolithen
Was bedeutet das jetzt alles für die Entwicklung des neuen Backend? Die größte Herausforderung für uns ist, die Architektur möglichst einfach zu konzipieren. Weiter oben wurde bereits festgestellt, dass ein Microservices-Ansatz derzeit für uns nicht infrage kommt. Entwickeln wir jetzt den nächsten Big Ball of Mud? Sicher nicht. Unsere Architekturstrategie für die Zukunft sieht einen modularen Monolithen vor, dessen einzelne Module vollständig voneinander getrennt sind. Das soll so weit gehen, dass es möglich sein muss, die Module auf verschiedene einzelne Server aufzuteilen. Dieses Vorgehen hat gleich mehrere Vorteile:
-
Wir verhindern einen neuen Big Ball of Mud
-
Einzelne Module sind einfacher zu verstehen, einfacher zu debuggen und zu warten
-
Jedes Modul kann von einem anderen Team entwickelt werden, ohne dass sich die Teams in die Quere kommen
-
Es bietet die Option, in Zukunft evtl. auf eine Microservices-/SCS-Architektur umzusteigen
Trotz der sehr guten Quarkus-Dokumentation gibt es leider nur sehr wenige Informationen darüber, wie dieser MicroProfile-Server für mehr als einen Microservice eingesetzt werden kann. Die Standardtutorials zeigen, wie schön einfach sich einzelne Services oder kleine Anwendungen ohne Untermodule bauen lassen, aber so gut wie nie, wie eine mögliche Projektstruktur für eine größere Anwendung aussieht. Den Proof of Concept für unsere Zwecke zu erstellen, hat uns etwas Zeit gekostet, deshalb wollen wir unsere Ergebnisse gern hier teilen.
Der zukünftige Server soll neben dem Backend auch das neue Frontend ausliefern. Getreu dem Motto „KISS – Keep it simple, stupid“ sparen wir uns damit ein weiteres Stück Komplexität in der Auslieferung und im Betrieb. Das Projekt-Set-up soll so einfach wie möglich bleiben und dabei gut erweiterbar sein. Als Build-Tool haben wir uns für Maven entschieden. Hier ist eine Projektstruktur durch das Konzept „Convention over Configuration“ vorgegeben und kann nur schwierig geändert werden, was wir als großen Vorteil ansehen. Gradle ist in einigen Punkten flexibler, hat aber damit auch den Nachteil, dass der Code für den Build selbst ebenfalls über die Jahre aus dem Ruder laufen kann.
Jedes funktionale Modul im Projekt entspricht in unserem Beispiel dann eins zu eins einem Maven-Modul. In der einfachsten Ausführung haben wir drei Module: Frontend, Backend und Runnable. Das Frontend-Modul enthält sämtlichen Code für das Frontend und produziert ebenfalls ein jar, damit dieses später als Dependency referenziert werden kann. Das Backend-Modul enthält entsprechend den Code für das Backend. Das Runnable-Modul ist ein reines Metamodul, es ist nur dafür da, das Executable Jar (Native Executable, Docker-Container) am Ende zusammenzubauen. In der Beispielgrafik (Abb. 2) sieht man schon, wie sich weitere Backend-Module in die Struktur einfügen.
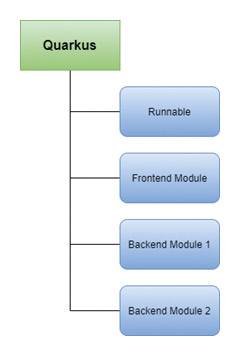
Abb. 2: Projektstruktur in der Übersicht
Frontend
Die erste Frage, die sich bei dem Frontend-Modul stellt, ist: „Muss man Node, npm/yarn etc. separat installiert haben?“ Einfacher ist es natürlich, wenn jeder Entwickler einfach das Projekt auschecken und direkt damit arbeiten kann. Das macht die automatische Integration, zum Beispiel mit Jenkins, einfacher, weil auch hier Node.js etc. nicht extra installiert werden müssen, was auch potenzielle Fehler durch unterschiedliche Versionen in Development und Build von vornherein verhindert. Da wir ja alles so einfach wie möglich haben wollen, werden wir diesen Build-Prozess ebenfalls integrieren. Hierbei hilft uns das Frontend-Maven-Plug-in [6]. Dieses Plug-in unterstützt die Verwendung von yarn, npm, bower und anderen gängigen Tools im Frontend-Development-Bereich. Mit dessen Hilfe können wir jetzt die Struktur des Front-end-Moduls (Abb. 3) so gestalten, dass ein Frontend-Entwickler sich dort zu Hause fühlt und alle notwendigen Build-Tools zur Verfügung hat. Je nach Betriebssystem wird in unserem Fall die richtige Node.js-Version heruntergeladen und es werden sämtliche Dependencies mit npm aufgelöst und in ein separates Verzeichnis gepackt.
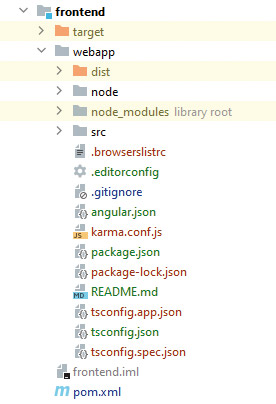
Abb. 3: Frontend-Projektstruktur in IntelliJ
An dieser Stelle ist es wichtig zu erwähnen, dass man beide Verzeichnisse unbedingt der .gitignore-Datei hinzufügen sollte, damit nicht aus Versehen bis zu mehreren Hundert Megabyte an Bibliotheken eingecheckt werden. Auch wollten wir verhindern, dass die Dependencies ständig aufgelöst und heruntergeladen werden, da dies eine Weile dauern kann. Hierfür verwenden wir verschiedene Maven-Profile (Listing 1). Ein Profil genau für den eben beschriebenen Schritt und eins zum reinen Bauen der Sources. Das spart uns bei der täglichen Arbeit eine Menge Zeit. Bei der Backend-Entwicklung braucht man häufig den Frontend-Part gar nicht oder nicht aktuell und kann ihn beim Build weglassen, indem die entsprechenden Profile nicht angegeben bzw. aktiviert werden.
<profiles>
<profile>
<id>Install node and npm</id>
<activation>
<property>
<name>ui.deps</name>
</property>
</activation>
<build>
<plugins>
<plugin>
<groupId>com.github.eirslett</groupId>
<artifactId>frontend-maven-plugin</artifactId>
<version>${version.frontend-maven-plugin}</version>
<executions>
<execution>
<id>install node and npm</id>
<goals>
<goal>install-node-and-npm</goal>
</goals>
<phase>generate-sources</phase>
<configuration>
<nodeVersion>v14.17.0</nodeVersion>
</configuration>
</execution>
<execution>
<id>npm install</id>
<goals>
<goal>npm</goal>
</goals>
<configuration>
<arguments>install</arguments>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>
<profile>
<id>Build the UI with AOT</id>
<activation>
<property>
<name>ui</name>
</property>
</activation>
<build>
<plugins>
<plugin>
<groupId>com.github.eirslett</groupId>
<artifactId>frontend-maven-plugin</artifactId>
<version>${version.frontend-maven-plugin}</version>
<executions>
<execution>
<id>npm run build</id>
<goals>
<goal>npm</goal>
</goals>
<configuration>
<arguments>run build</arguments>
</configuration>
<phase>generate-resources</phase>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>
</profiles>
Das Frontend-Plug-in muss noch wissen, in welchem Verzeichnis sich die Frontend-Sources befinden. Das Maven Resources-Plug-in muss auch konfiguriert werden, damit die fertigen Dateien im richtigen Verzeichnis im Target-Ordner landen. Hier muss vor allem darauf geachtet werden, den Applikationsnamen in der Ordnerstruktur nicht zu vergessen: <directory>webapp/dist/my-app</directory> (Listing 2).
Die Konfiguration des Maven Clean-Plug-in ist reine Bequemlichkeit, damit man nicht von Hand die Unterverzeichnisse löschen muss, wenn man das Frontend komplett neu bauen möchte.
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-clean-plugin</artifactId>
<version>${clean.plugin.version}</version>
<configuration>
<filesets>
<fileset>
<directory>webapp/dist</directory>
</fileset>
</filesets>
</configuration>
</plugin>
<!-- Used to run the angular build -->
<plugin>
<groupId>com.github.eirslett</groupId>
<artifactId>frontend-maven-plugin</artifactId>
<version>${version.frontend-maven-plugin}</version>
<configuration>
<workingDirectory>webapp</workingDirectory>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>${resources.plugin.version}</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>process-resources</phase>
<goals>
<goal>copy-resources</goal>
</goals>
<configuration>
<outputDirectory>${basedir}/target/classes/META-INF/resources/</outputDirectory>
<resources>
<resource>
<directory>webapp/dist/my-app</directory>
<filtering>false</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
Backend
Der Backend-Teil ist relativ straight forward, hat aber auch ein, zwei Punkte, die nicht offensichtlich sind. Das Verzeichnislayout bleibt so, wie wir es von Maven-Projekten gewohnt sind. Wenn man bei seinem Projekt CDI verwendet, muss man die CDI Bean Discovery durch die Verwendung des jandex-maven-plugins [7] explizit aktivieren. Interessant wird es auch bei der Konfiguration durch die application.properties-Datei. Diese wird in dem Runnable-Modul in das final ausführbare jar eingefügt. Quarkus, wie andere MicroProfile-Server auch, liest Properties von mehreren Quellen ein. Nach Standard werden die System- und Umgebungsvariablen gelesen und dann die META-INF/microprofile.properties-Datei. Hier wird noch eine zusätzliche Quelle eingefügt, die application.properties-Datei. Mit Hilfe dieser Datei lassen sich viele Serveroptionen sehr einfach konfigurieren, sie sind allerdings Quarkus-spezifisch und können nicht alle eins zu eins auf andere Server übertragen werden.
Für das Backend-Modul selbst ist diese Datei quasi nicht existent, weil sie im Runnable-Modul liegt. Dieser Umstand fällt erst so richtig auf, wenn man versucht, für Tests mit Wiremock die Ports zu ändern, und sich wundert, dass die geänderten Ports nicht verwendet werden (Listing 3).
# This port is being used e.g. for the WireMock server # 0 means random port assigned by the OS quarkus.http.test-port=0 quarkus.http.test-ssl-port=0
Da diese Einstellungen nur für die Tests gebraucht werden, können wir eine separate application.properties-Datei einfach in den src/test/resources-Pfad packen und mit den entsprechenden Werten für die Tests bestücken. Die Ausführung der Tests erfolgt nur im Kontext dieses Moduls, daher ist es völlig irrelevant, wo andere Konfigurationen hinterlegt sind. Wenn das Projekt später weiterwächst und mehrere Backend-Module enthält, kann somit jedes Backend-Modul seine eigenen Test-Properties mitbringen, ohne dass diese sich gegenseitig stören.
Runnable
Das Runnable-Modul hat nur eine Aufgabe, und zwar, eine ausführbare Datei zu bauen. Das kann eine ausführbare jar-Datei sein, ein Docker-Container oder ein Native Executable mit Hilfe des Graal Native Image Compilers [8]. Man muss sich auch nicht exklusiv für eine Methode entscheiden, sondern kann alle drei Möglichkeiten vorbereiten und dann das gewünschte Target beim Bauen auswählen. In diesem Modul befindet sich schließlich auch application.properties von Quarkus, welche die Laufzeitkonfiguration für das zu bauende Runnable enthält.
Etwas fehlt noch. Der Development Mode von Quarkus lässt sich mit dem Multi-Module-Set-up nicht mehr so einfach aktivieren. Ein etwas komplizierteres Maven Goal hilft hier weiter. Am besten legt man es direkt als Run-Konfiguration für Maven in der IDE an oder speichert es als Shell Script:
mvn -pl runnable -am compile quarkus:dev
Dieser Aufruf im Projekt-Root sorgt dafür, dass alle Module, welche als Dependency im Runnable-Modul eingetragen sind, kompiliert werden, und zwar im Quarkus-Dev-Modus. Damit der Dev-Modus auch wirklich aktiviert werden kann, muss noch das entsprechende Maven Plug-in im Runnable-Modul konfiguriert werden (Listing 4).
<plugin>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-maven-plugin</artifactId>
<version>${quarkus-plugin.version}</version>
<extensions>true</extensions>
<executions>
<execution>
<goals>
<goal>build</goal>
<goal>generate-code</goal>
<goal>generate-code-tests</goal>
</goals>
</execution>
</executions>
</plugin>
Das komplette Beispiel, aus dem die Code-Snippets stammen, ist auf GitHub [9] verfügbar.
Ausblick
Wir befinden uns erst am Anfang der Umstellung unserer Softwarearchitektur. Die Überlegungen, die Evaluation und die Vorbereitungen waren sehr umfangreich und haben auch schon einige Prototypen hervorgebracht. Die Erkenntnisse, die wir bis hierhin gewonnen haben, haben wir in diesem Artikel beschrieben. Für uns ist das aber nur der Start in ein sehr großes Unterfangen. Wir wollen auch in Zukunft unsere Erkenntnisse, Entwicklungen und Erfahrungen teilen und werden bestimmt mit dem einen oder anderen Artikel oder auch Vortrag wiederkommen.
Regelmäßig News zur Konferenz und der JAX-Community erhalten Stay tuned
Links & Literatur
[1] https://resources.sei.cmu.edu/library/asset-view.cfm?assetid=5177
[2] Fowler, Martin: https://martinfowler.com/bliki/StranglerFigApplication.html
[3] Parsons, R., Kua, P., Ford, N.: „Building Evolutionary Architectures: Support Constant Change“, O’Reilly, 2017
[5] Evans, Eric: „Domain-Driven Design: Tackling Complexity in the Heart of Software“, Addison-Wesley Professional, 2003
[6] https://github.com/eirslett/frontend-maven-plugin
[7] https://quarkus.io/guides/maven-tooling#multi-module-maven
[8] https://www.graalvm.org/reference-manual/native-image/
[9] https://github.com/Mr-Steel/quarkus_multimodule
Mehr zum Thema auf der W-JAX & JAX:
● Session: Hands-on mit Quarkus #Live-Coding
● Session: Hilfe, ich will meinen Monolithen zurück!




