Quelle: Shutterstock
von Dr. Carola Lilienthal
Dieses Heilsversprechen klingt gut, beinhaltet aber viele Fallstricke, Missverständnisse und Herausforderungen. Ein Umbau hin zu Microservices ist aufwendig und kann, falsch eingeleitet, zu einem schlechteren Ergebnis führen als es die ursprüngliche Architektur einmal war. Auf Basis der Erfahrungen aus Kundenprojekten der letzten Jahre werde ich in diesem Artikel sinnvolle von unsinnigen Maßnahmen trennen und pragmatische Lösungen vorstellen.
Microservices: Warum?
Microservices sind in den letzten Jahren als neues Architekturparadigma aufgekommen. Viele Entwickler und Architekten dachten zuerst, es ginge bei Microservices nur darum, Softwaresysteme in voneinander unabhängig deploybare Services aufzuteilen. Aber eigentlich haben Microservices einen anderen Sinn: Bei Microservices geht es darum, Software so auf Entwicklungsteams aufzuteilen, dass die Teams unabhängig und eigenständig schneller entwickeln können als vorher. Bei Microservices geht es also zuerst einmal nicht um Technik, sondern um den Menschen.
Ein schlagkräftiges Entwicklungsteam hat eine Größe, bei der Urlaub und Krankheit nicht zu Stillstand führen (also ab drei Personen) und bei der die Kommunikation beherrschbar bleibt (also nicht mehr als sieben bis acht Personen, die sich gegenseitig auf dem Stand der Dinge halten müssen). Ein solches Team soll nun ein Stück Software, ein Modul zum (Weiter-)Entwickeln bekommen, das unabhängig vom Rest des Systems ist. Denn nur, wenn das Modul unabhängig ist, kann das Team eigenständig Entscheidungen treffen und sein Modul weiterentwickeln, ohne auf andere Teams und deren Zulieferungen zu warten.
Diese Unabhängigkeit von anderen Teams ist nur dann möglich, wenn das Softwaresystem nach fachlichen Kriterien zerlegt wird. Technische Kriterien führen dazu, dass es irgendwelche Arten von Frontend- und Backend-Teams gibt (Abb. 1). In so einer technischen Teamaufteilung ist mindestens das Frontend-Team davon abhängig, dass das Backend-Team die Frontend-Schnittstelle um die benötigten Features erweitert. Gibt es noch ein Datenbankteam, so hat das Backend-Team auch keine Freiheit und muss seinerseits auf Anpassungen durch das Datenbankteam warten. Neue Features betreffen in einer solchen Teamstruktur fast immer mehrere Teams, die bei der Umsetzung voneinander abhängig sind und viel miteinander kommunizieren müssen, damit die Schnittstellen stimmen.
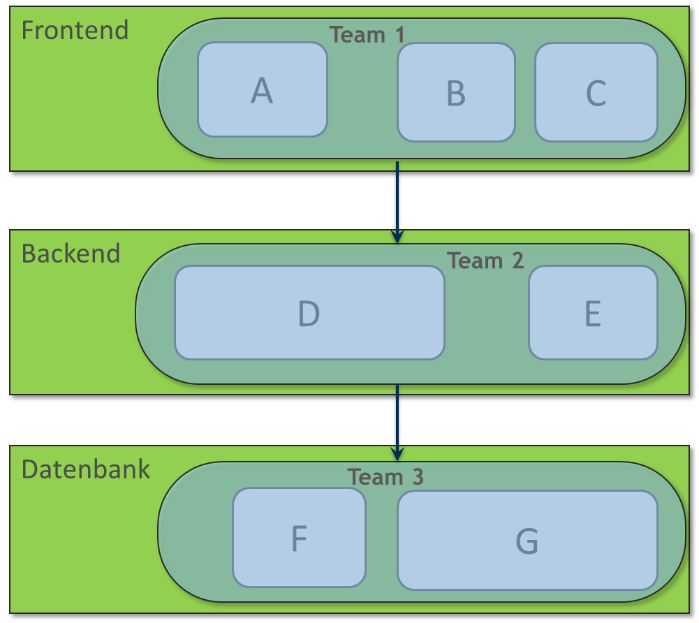
Abbildung 1: Technische Aufteilung von Teams
Eine Aufteilung von Teams nach fachlichen Kriterien macht es im Gegensatz dazu möglich, dass ein Team für ein fachliches Modul in der Software zuständig ist, das sich durch alle technischen Schichten von der Oberfläche bis zur Datenbank zieht (Abb. 2).
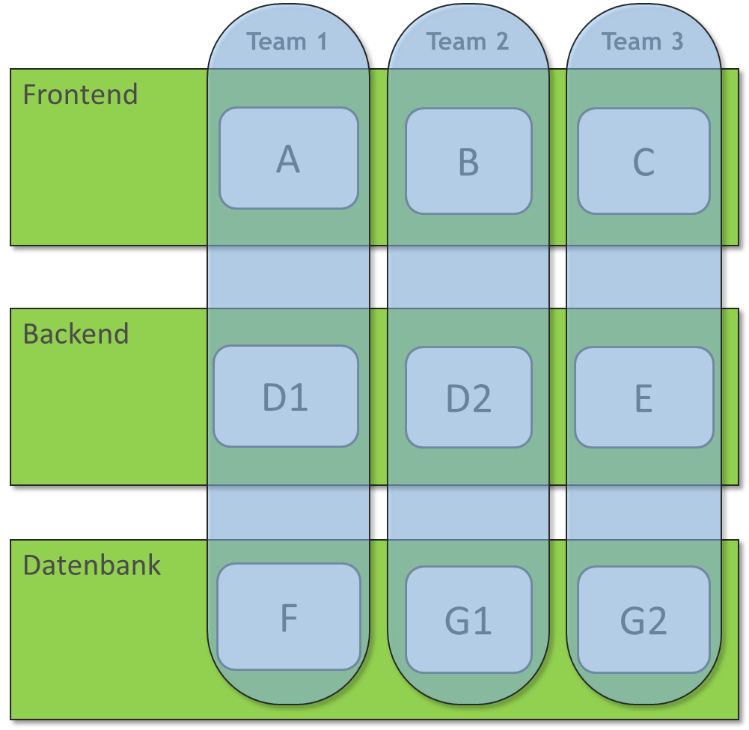
Abbildung 2: Fachliche Aufteilung von Teams
Neue Features sollten, wenn der Schnitt in fachliche Module gut gelungen ist, jeweils einem Team und seinem Modul zugeordnet werden können. Natürlich ist das erst einmal eine Idealvorstellung – in der Praxis können neue Features dazu führen, dass der Modulschnitt überdacht werden muss, weil das neue Feature die aktuelle fachliche Zerlegung über den Haufen wirft. Oder sie führen dazu, dass das wahrscheinlich etwas zu große Feature so geschickt in kleinere Features zerlegt werden muss, dass verschiedene Teams ihren jeweiligen fachlichen Anteil an dem großen Feature unabhängig von den anderen Teams umsetzen können. Die jeweiligen Teilfeatures sind dann hoffentlich auch allein sinnvoll und können unabhängig voneinander ausgeliefert werden. Der Mehrwert des großen Features wird dem Anwender allerdings erst am Ende zur Verfügung stehen, wenn alle beteiligten Teams fertig sind.
Fachliche Zerlegung: Wie geht das?
Strebt man eine fachliche Aufteilung seines großen Monolithen an, stellt sich die Frage: Wie findet man stabile, unabhängige fachliche Schnitte, entlang derer eine Zerlegung möglich wird? Das relativ vage beschriebene Konzept von Microservices gibt darauf keine Antwort. Deshalb hat in den letzten Jahren Domain-driven Design (DDD) von Eric Evans an Bedeutung gewonnen. DDD bietet neben vielen anderen Best Practices eine Anleitung, wie Domänen fachlich aufgeteilt werden können. Diese fachliche Aufteilung in Subdomänen überträgt Eric Evans auf Softwaresysteme. Das Äquivalent zu Subdomänen ist in der Software der Bounded Context. Sind die Subdomänen gut gewählt und die Bounded Contexts entsprechend in der Software umgesetzt, dann entsteht eine gute fachliche Zerlegung.
Um eine gute fachliche Zerlegung zu finden, hat es sich in unseren Projekten als sinnvoll erwiesen, den Monolithen und die in ihm möglicherweise vorhandene Struktur erst einmal beiseite zu legen und sich noch einmal grundlegend mit der Fachlichkeit, also der Aufteilung der Domäne in Subdomänen, zu beschäftigen. Wir fangen in der Regel damit an, uns zusammen mit den Anwendern und Fachexperten einen Überblick über unsere Domäne zu verschaffen. Das kann entweder mittels Event Storming oder mittels Domain Storytelling geschehen – zwei Methoden, die für Anwender und Entwickler gleichermaßen gut verständlich sind.
In Abbildung 3 ist eine Domain Story zu sehen, die mit den Anwendern und Entwicklern eines kleinen Programmkinos erstellt wurde. Die grundsätzliche Frage, die wir uns bei der Modellierung gestellt haben, ist: Wer macht was womit wozu? Nimmt man diese Frage als Ausgangspunkt, so lässt sich in der Regel sehr schnell ein gemeinsames Verständnis der Domäne erarbeiten.
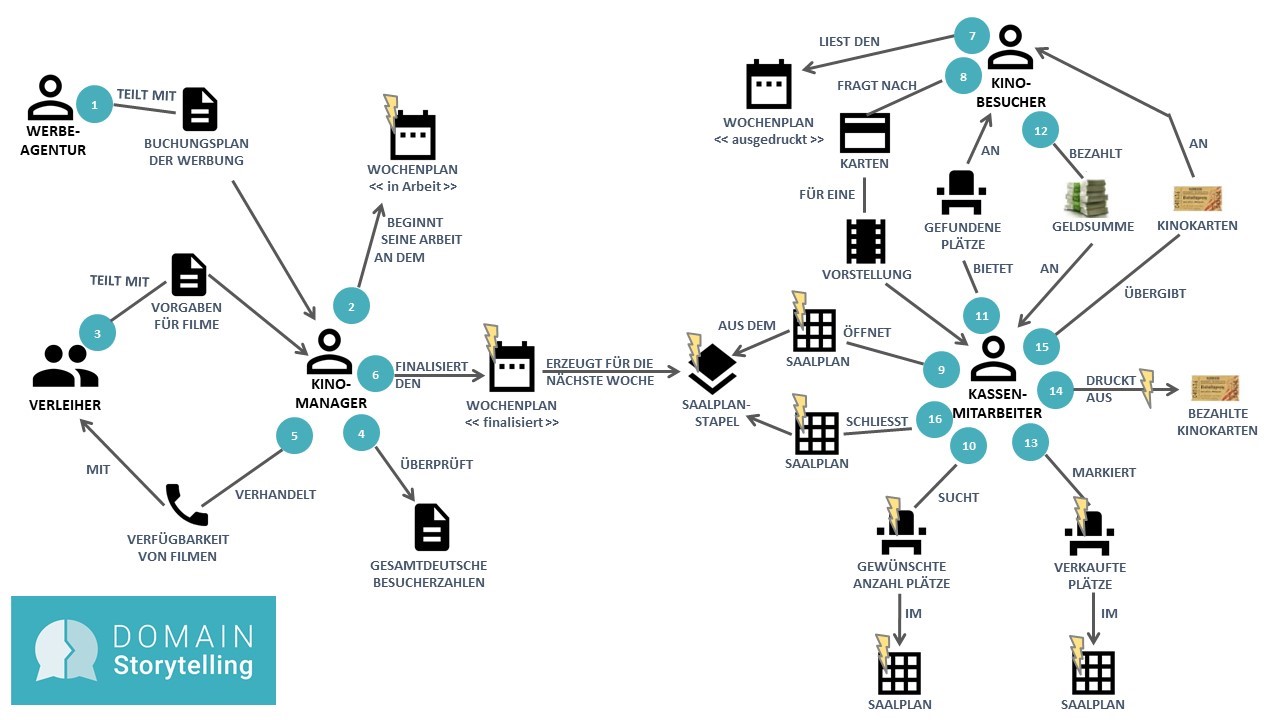
Abbildung 3: Überblicks-Domain-Story für ein Programmkino
Als Personen bzw. Rollen oder Gruppen sind in dieser Domain Story erkennbar: die Werbeagentur, der Kinomanager, der Verleiher, der Kassenmitarbeiter und der Kinobesucher. Die einzelnen Rollen tauschen Dokumente und Informationen aus, wie den Buchungsplan der Werbung, die Vorgaben für Filme und die Verfügbarkeit von Filmen. Sie arbeiten aber auch mit „Gegenständen“ aus ihrer Domäne, die in einem Softwaresystem abgebildet sind: dem Wochenplan und dem Saalplan. Diese computergestützten Gegenstände sind mit einem gelben Blitz in der Domain Story markiert. Die Überblicks-Domain-Story beginnt links oben mit der Ziffer 1, wo die Werbeagentur dem Kinomanager den Buchungsplan mit der Werbung mitteilt, und endet bei der 16, wenn der Kassenmitarbeiter den Saalplan schließt.
An diesem Überblick lassen sich verschiedene Indikatoren erklären, die beim Schneiden einer Domäne helfen:
Abteilungsgrenzen oder verschiedene Gruppen von Domänenexperten deuten darauf hin, dass die Domain Story mehrere Subdomänen enthält. In unserem Beispiel könnte man sich eine Abteilung Kinomanagement und eine Abteilung Kartenverkauf vorstellen (Abb. 4).
Werden Schlüsselkonzepte der Domäne von den verschiedenen Rollen unterschiedlich verwendet oder definiert, deutet das auf mehrere Subdomänen hin. In unserem Beispiel wird das Schlüsselkonzept „Wochenplan“ vom Kinomanager deutlich umfangreicher definiert als der ausgedruckte Wochenplan, den der Kinobesucher zu Gesicht bekommt. Für den Kinomanager enthält der Wochenplan neben den Vorstellungen in den einzelnen Sälen auch die geplante Werbung, den Eisverkauf und die Reinigungskräfte. Diese Informationen sind für den Kinobesucher irrelevant (gestrichelte Kreise in Abb. 4).
Enthält die Überblicks-Domain-Story Teilprozesse, die von verschiedenen Triggern ausgelöst werden und in unterschiedlichen Rhythmen ablaufen, dann könnten diese Teilprozesse eigene Subdomänen bilden (durchgezogene Kreise in Abb. 4).
Gibt es im Überblick Prozessschritte, an denen Information nur in eine Richtung läuft, könnte diese Stelle ein guter Ansatzpunkt für einen Schnitt zwischen zwei Subdomänen sein (hellblauer Pfeil in Abb. 4).
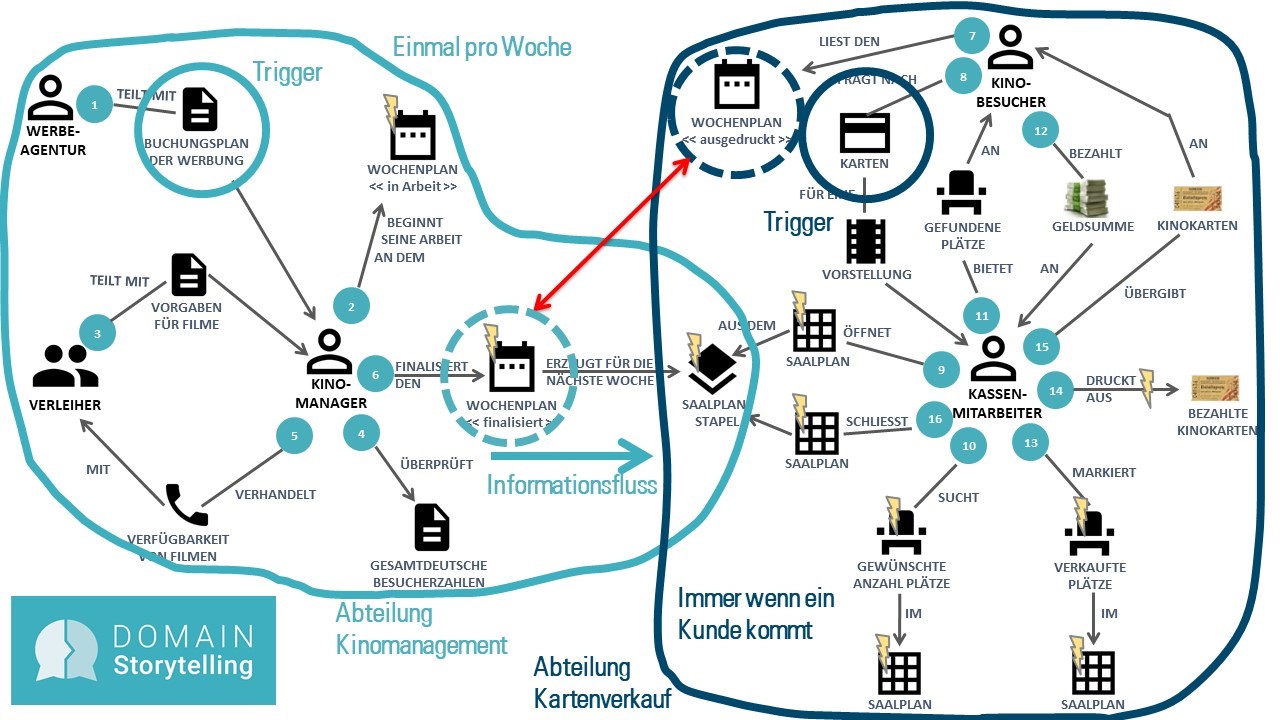
Abbildung 4: Überblicks-Domain Story mit Subdomänengrenzen
Für echte große Anwendungen in Unternehmen sind die Überblicks-Domain-Stories in der Regel deutlich größer und umfassen mehr Schritte. Sogar bei unserem kleinen Programmkino fehlen im Überblick die Eisverkäufer und das Reinigungspersonal, die sicherlich auch mit der Software interagieren werden. Die Indikatoren, nach denen man in seiner Überblicks-Domain-Story suchen muss, gelten allerdings sowohl für kleine als auch für größere Domänen.
Übertragung auf den Monolithen
Mit der fachlichen Aufteilung in Subdomänen im Rücken können wir uns nun wieder dem Monolithen und seinen Strukturen zuwenden. Bei dieser Zerlegung setzen wir Architekturanalysetools ein, die es uns erlauben, die Architektur im Tool umzubauen und Refactorings zu definieren, die für den echten Umbau des Sourcecodes notwendig sind. Hier eignen sich unterschiedliche Tools: der Sotograph, der Sonargraph, Structure101, Lattix, Teamscale, Axivion Bauhaus Suite und andere.
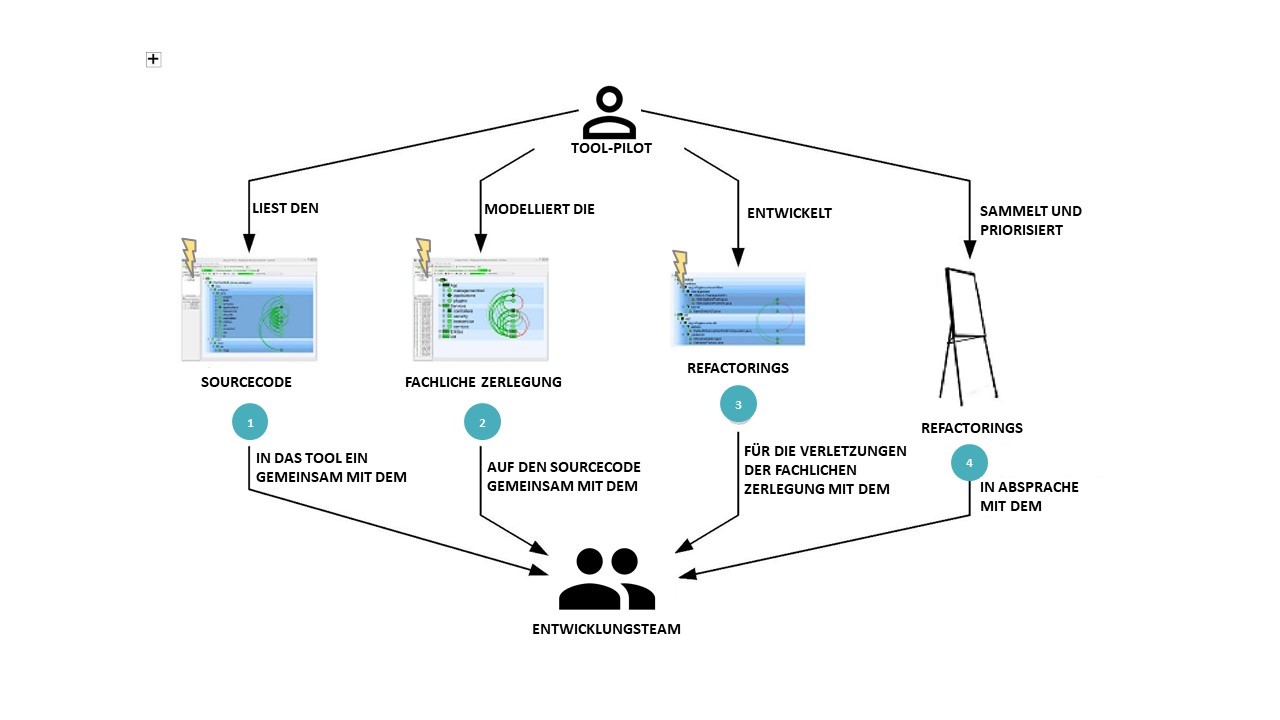
Abbildung 5: Mob Architecting mit dem Team
In Abbildung 5 sieht man, wie die Zerlegung des Monolithen mit einem Analysetool durchgeführt wird. Die Analyse wird von einem Tool-Pilot, der sich mit dem jeweiligen Tool und der bzw. den eingesetzten Programmiersprachen auskennt, gemeinsam mit allen Architekten und Entwicklern des Systems in einem Workshop durchgeführt. Zu Beginn des Workshops wird der Sourcecode des Systems mit dem Analysewerkzeug geparst (Abb. 5, 1) und so werden die vorhandenen Strukturen erfasst (zum Beispiel Build Units, Eclipse-/VisualStudio-Projekte, Maven-Module, Package-/Namespace-/Directory-Bäume, Klassen). Auf diese vorhandenen Strukturen werden nun fachliche Module modelliert (Abb. 5, 2), die der fachlichen Zerlegung entsprechen, die mit den Fachexperten entwickelt wurde. Dabei kann das ganze Team sehen, wo die aktuelle Struktur nahe an der fachlichen Zerlegung ist und wo es deutliche Abweichungen gibt. Nun macht sich der Tool-Pilot gemeinsam mit dem Entwicklungsteam auf die Suche nach einfachen Lösungen, wie vorhandene Struktur durch Refactorings an die fachliche Zerlegung angeglichen werden kann (Abb. 5, 3). Diese Refactorings werden gesammelt und priorisiert (Abb. 5, 4). Manchmal stellen der Tool-Pilot und das Entwicklungsteam in der Diskussion fest, dass die im Sourcecode gewählte Lösung besser oder weitergehender ist als die fachliche Zerlegung aus den Workshops mit den Anwendern. Manchmal ist aber auch weder die vorhandene Struktur noch die gewünschte fachliche Zerlegung die beste Lösung, und beides muss noch einmal grundsätzlich überdacht werden.
Erst modular, dann Micro
Mit den so gefundenen Refactorings kann die Arbeit am Monolithen beginnen. Endlich können wir ihn in Microservices zerlegen. Doch halt! Spätestens hier sollte man sich die Frage stellen, ob man sein System tatsächlich in einzelne deploybare Einheiten zerlegen will oder ob nicht ein gut strukturierter Monolith ausreicht. Durch das Aufsplitten des Monolithen in einzelne Deployables kauft man sich eine weitere Stufe von Komplexität ein, nämlich die Verteilung. Braucht man Verteilung, weil der Monolith nicht mehr performant genug ist, dann muss man diesen Schritt gehen. Unabhängige Teams kann man mit den heute sehr weit entwickelten Build-Pipelines aber auch in einem wohlstrukturierten Monolithen bekommen.
Ein wohlstrukturierter Monolith, also ein modularer Monolith oder (wie Dr. Gernot Starke einmal sagte) „ein Modulith“, besteht aus einzelnen fachlichen Modulen, die in einem Deployable existieren (Abb. 6). In manchen Architekturen sind die User Interfaces der einzelnen fachlichen Module hochintegriert. Details zu dieser Variante sprengen diesen Artikel und finden sich in [1].
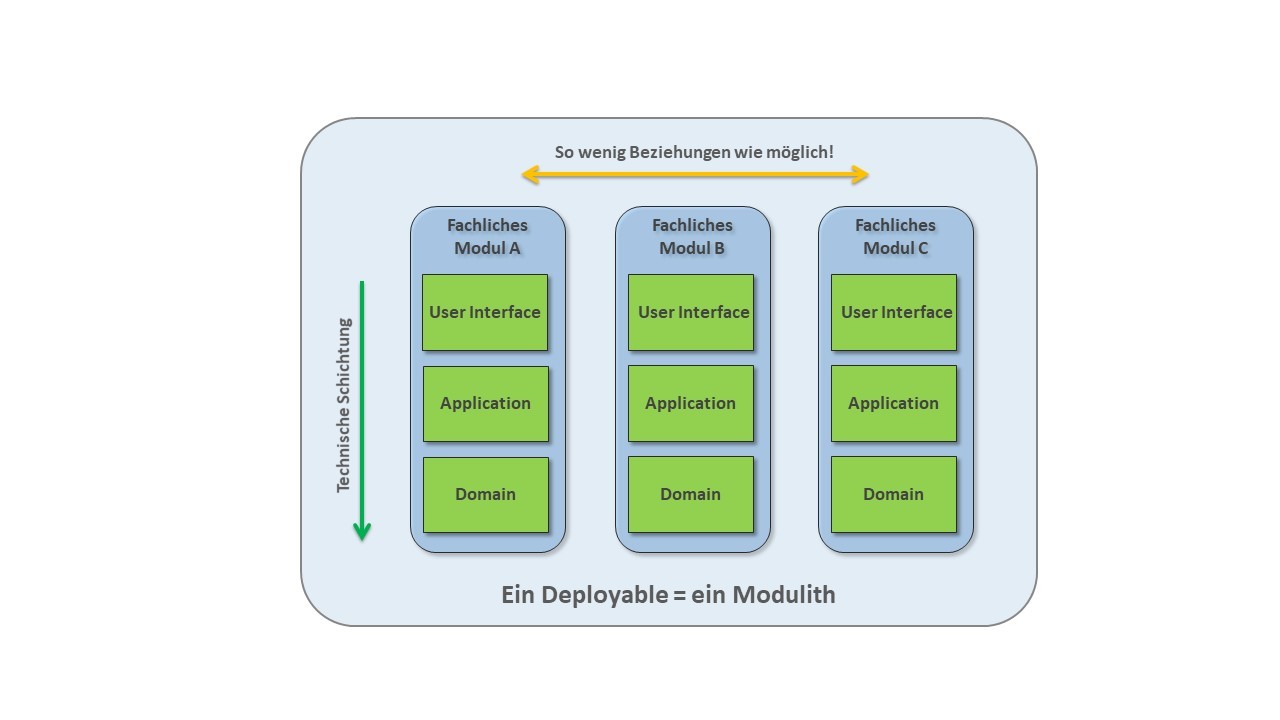
Abbildung 6: Der Modulith, ein wohlstrukturierter Monolith
Ein solcher Modulith setzt durch seine Aufteilung in möglichst unabhängige Module ein grundlegendes softwaretechnisches Prinzip guter Softwarearchitektur um: hohe Kohäsion und lose Kopplung. Die Klassen in den einzelnen fachlichen Modulen gehören jeweils zu einer Subdomäne und sind als Bounded Context in der Software zu finden. Das heißt, diese Klassen setzen gemeinsam eine fachliche Aufgabe um und arbeiten dafür umfassend zusammen. Innerhalb eines fachlichen Moduls herrscht also hohe Kohäsion. Um ihre fachliche Aufgabe zu erledigen, sollten die Klassen in einem Modul nichts von Klassen aus anderen fachlichen Modulen brauchen.
Maximal sollten fachliche Updates, zum Beispiel als Events, über für andere fachliche Module möglicherweise interessante Änderungen zwischen den Modulen ausgetauscht werden und Arbeitsaufträge, die in einen anderen Bounded Context gehören, als Command an andere Module weitergegeben werden. Allerdings sollte man hier immer darauf achten, dass diese Benachrichtigungen nicht überhandnehmen oder als verkappte direkte Aufrufe an andere fachliche Module missbraucht werden. Denn lose Kopplung zwischen fachlichen Modulen bedeutet, dass es so wenig Beziehungen wie möglich gibt. Lose Kopplung lässt sich niemals durch den Einsatz eines technischen Event-Mechanismus erreichen. Denn technische Lösungen schaffen eine technische Entkopplung, aber keine fachlich lose Kopplung.
So ein wohlstrukturierter Modulith ist hervorragend auf eine möglicherweise später notwendige Zerlegung in Microservices vorbereitet, weil er bereits aus fachlich möglichst unabhängigen Modulen besteht. Wir haben also alle Vorteile auf der Hand: Unabhängige Teams, die in den Grenzen ihres Bounded Contexts schnell arbeiten können, und eine Architektur, die auf Zerlegung in mehrere Deployables vorbereitet ist.
Der Knackpunkt: Das Domänenmodell
Wenn ich mir große Monolithen anschaue, dann finde ich dort in der Regel ein kanonisches Domänenmodell. Dieses Domänenmodell wird aus allen Teilen der Software verwendet, und die Klassen im Domänenmodell haben im Vergleich zum Rest des Systems sehr viele Methoden und viele Attribute. Die zentralen Domänenklassen, wie zum Beispiel Produkt, Vertrag, Kunde etc., sind dann meist auch die größten Klassen im System. Was ist passiert?
Jeder Entwickler, der neue Funktionalität in das System eingebaut hat, hat dafür die zentralen Klassen des Domänenmodells gebraucht. Allerdings musste er diese Klassen auch ein bisschen erweitern, damit seine neue Funktionalität umgesetzt werden konnte. So bekamen die zentralen Klassen mit jeder neuen Funktionalität ein bis zwei neue Methoden und Attribute hinzu. Genau! So macht man das! Wenn es schon eine Klasse Produkt im System gibt und ich Funktionalität entwickle, die das Produkt braucht, dann verwende ich die eine Klasse Produkt im System und erweitere sie so, dass es passt. Ich will nämlich die vorhandene Klasse wiederverwenden und nur an einer Stelle suchen müssen, wenn beim Produkt ein Fehler auftritt. Schade ist nur, dass diese neuen Methoden im Rest des Systems gar nicht benötigt, sondern nur für die neue Funktionalität eingebaut werden.
Domain-driven Design und Microservices gehen an dieser Stelle den entgegengesetzten Weg. In einem Modulithen, der fachlich zerlegt ist, oder in einer verteilten Microservices-Architektur gibt es in jedem Bounded Context, der die Klasse Produkt braucht, eine eigene Klasse Produkt. Diese kontextspezifische Klasse Produkt ist auf ihren Bounded Context zugeschnitten und bietet nur die Methoden an, die in diesem Kontext benötigt werden. Den Wochenplan aus unserem Kinobeispiel in Abbildung 3 und 4 gibt es im fachlich zerlegten System zweimal. Einmal im Bounded Context Kinomanagement mit einer sehr reichhaltigen Schnittstelle, über die man Werbung zu Vorstellungen einplanen und den Eisverkauf und die Reinigungskräfte einteilen kann. Und zum anderen im Bounded Context Kartenverkauf, wo die Schnittstelle lediglich das Suchen von Filmen und die Abfrage des Filmangebots zu bestimmten Zeiten ermöglicht. Werbung, Eisverkauf und Reinigungskräfte sind für den Kartenverkauf irrelevant und werden in diesem Bounded Context in der Klasse Wochenplan also auch nicht benötigt.
Will man einen Monolithen fachlich zerlegen, so muss man das kanonische Domänenmodell zerschlagen. Das ist in den meisten großen Monolithen eine Herkulesaufgabe. Zu verwoben sind die auf dem Domänenmodell aufsetzenden Teile des Systems mit den Klassen des Domänenmodells. Um hier weiterzukommen, kopieren wir zuerst die Domänenklassen in jeden Bounded Context. Wir duplizieren also Code und bauen diese Domänenklassen dann jeweils für ihren Bounded Context zurück. So bekommen wir kontextspezifische Domänenklassen, die von ihrem jeweiligen Team unabhängig vom Rest des Systems erweitert und angepasst werden können.
Selbstverständlich müssen bestimmt Eigenschaften von Produkt, beispielsweise die Produkt-ID und der Produktname, in allen Bounded Contexts gleich gehalten werden. Außerdem müssen neue Produkte in allen Bounded Contexts bekanntgemacht werden, wenn in einem Bounded Context ein neues Produkt angelegt wird. Diese Informationen werden über Updates von einem Bounded Context an alle anderen Bounded Contexts gemeldet, die mit Produkten arbeiten.
SOA ist keine Microservices-Architektur
Wenn ein System auf diese Weise zerlegt wird, entsteht eine Struktur, die einer IT-Landschaft aus dem Anfang der 2000er Jahre überraschend ähnelt. Verschiedene Systeme (möglicherweise von verschiedenen Herstellern) werden über Schnittstellen miteinander verbunden, arbeiten aber weiterhin autark auf ihrem eigenen Domänenmodell. In Abbildung 7 sieht man, dass es den Kunden in jedem der vier dargestellten Systeme gibt und die Kundendaten über Schnittstellen zwischen den Systemen ausgetauscht werden.
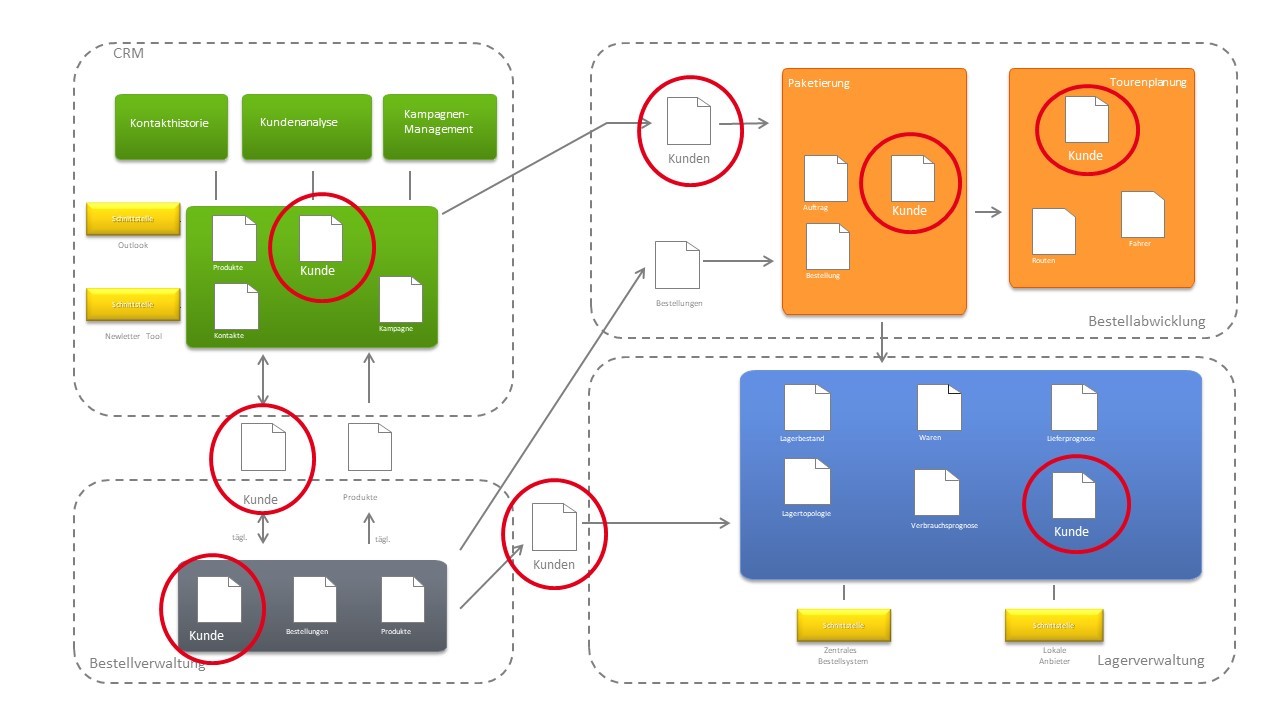
Abbildung 7: IT-Landschaft mit dem Kunden in allen Systemen
Anfang der 2000er wollte man dieser Verteilung der Kundendaten entgegenwirken, indem man Service-orientierte Architekturen (SOA) als Architekturstil verfolgt hat. Das Ergebnis waren IT-Landschaften, in denen es einen zentralen Kundenservice gibt, den alle anderen Systeme über einen Service Bus nutzen. Abbildung 8 stellt eine solche SOA mit einem Kundenservice schematisch dar.
So eine Service-orientierte Architektur mit zentralen Services hat im Lichte der Diskussion um Microservices den entscheidenden Nachteil, dass alle Entwicklungsteams, die den Kundenservice brauchen, nicht mehr unabhängig arbeiten können und damit an individueller Schlagkraft verlieren. Gleichzeitig ist es vermessen zu erwarten oder zu fordern, dass alle Großrechnersysteme, in denen in vielen Unternehmen die zentrale Datenhaltung sichergestellt wird und die als SOA-Services ansprechbar sind, auf Microservices-Architekturen umgebaut werden. In solchen Fällen treffe ich häufig eine Mischung aus SOA- und Microservices-Architektur an, was durchaus gut funktionieren kann.
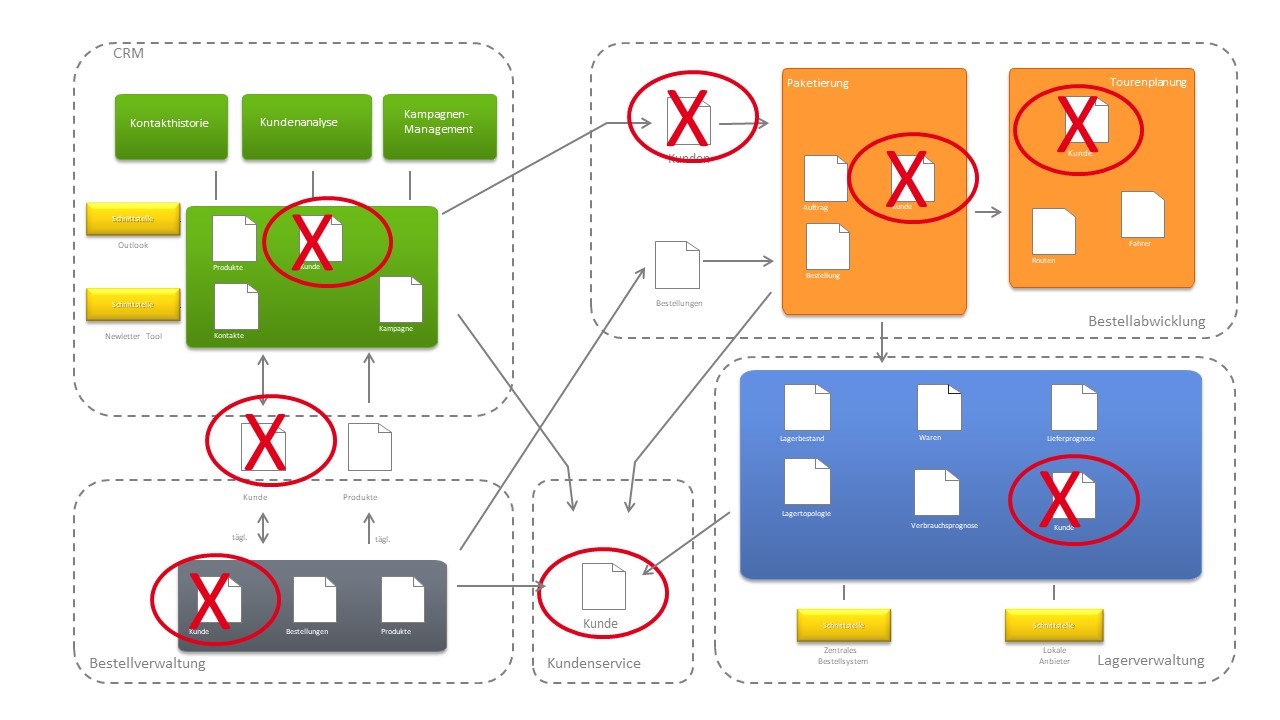
Abbildung 8: IT-Landschaft mit SOA und Kundenservice
Standortbestimmung
Um für Monolithen eine Bewertungsmöglichkeit zu schaffen, wie gut der Sourcecode auf eine fachliche Zerlegung vorbereitet ist, haben wir in den vergangenen Jahren den Modularity Maturity Index (MMI) entwickelt. In Abbildung 9 ist eine Auswahl von 21 Softwaresystemen dargestellt, die in einem Zeitraum von fünf Jahren analysiert wurden (X-Achse). Für jedes System ist die Größe in Lines of Code dargestellt (Größe des Punktes) und die Modularität auf einer Skala von 0 bis 10 (Y-Achse).
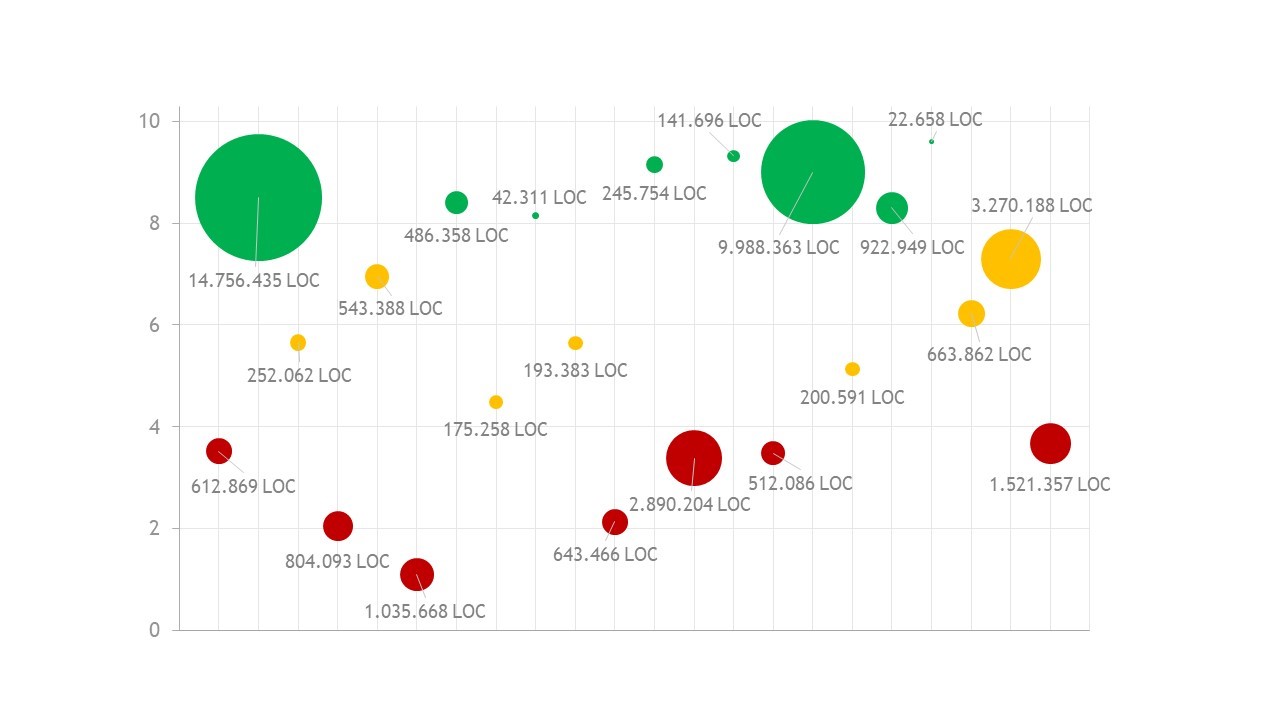
Abbildung 9: Modularity Maturity Index (MMI)
Liegt ein System in der Bewertung zwischen 8 und 10, so ist es im Inneren bereits modular aufgebaut und wird sich mit wenig Aufwand fachlich zerlegen lassen. Systeme mit einer Bewertung zwischen 4 und 8 haben gute Ansätze, jedoch sind hier einige Refactorings notwendig, um die Modularität zu verbessern. Systeme unterhalb der Marke 4 würde man nach Domain-driven Design als Big Ball of Mud bezeichnen. Hier ist kaum fachliche Struktur zu erkennen, und alles ist mit allem verbunden. Solche Systeme sind nur mit sehr viel Aufwand in fachliche Module zerlegbar.
Fazit
Microservices sind als Architekturstil noch immer in aller Munde. Inzwischen haben verschiedene Organisationen Erfahrungen mit dieser Art von Architekturen gemacht und die Herausforderungen und Irrwege sind deutlich geworden.
Um im eigenen Unternehmen einen Monolithen zu zerlegen, muss zuerst die fachliche Domäne in Subdomänen zerlegt und diese Struktur im Anschluss auf den Sourcecode übertragen werden. Dabei sind insbesondere das kanonische Domänenmodell, unsere Liebe zur Wiederverwendung und das Streben nach Service-orientierten Architekturen Hindernisse, die überwunden werden müssen.
Links & Literatur
[1] Lilienthal, Carola: „Langlebige Softwarearchitekturen – Technische Schulden analysieren, begrenzen und abbauen“; dpunkt.verlag, 2017.
Java-Dossier für Software-Architekten 2019

Mit diesem Dossier sind Sie auf alle Neuerungen in der Java-Community vorbereitet. Die Artikel liefern Ihnen Wissenswertes zu Java Microservices, Req4Arcs, Geschichten des DevOps, Angular-Abenteuer und die neuen Valuetypen in Java 12.