Quelle: Shutterstock
Microservices sind nicht einheitlich definiert. Eine Definition bieten die Independent Systems Architecture (ISA) Principles [1]. Sie bestehen aus neun Prinzipien, denen eine gute Microservices-Architektur genügen muss. Das erste Prinzip besagt, dass Microservices Module sind. Microservices sind nur eine Möglichkeit, ein System zu modularisieren. Alternativen sind Packages, JAR-Dateien oder Maven-Projekte. Für Microservices gilt dasselbe wie für andere Arten von Modulen: So sollen sie beispielsweise lose gekoppelt sein.
Das zweite Prinzip besagt, dass die Module als Container umgesetzt werden. Das bietet mehrere Vorteile: So kann jeder Microservice unabhängig von den anderen neu deployt werden. Bei einem Absturz eines Microservice laufen die anderen Microservices weiter. Bei einem Deployment-Monolith hingegen würde ein Speicherleck die gesamte Anwendung zum Absturz bringen. So erhöhen Microservices die Entkopplung. Klassische Module entkoppeln nur die Entwicklung. Microservices entkoppeln auch andere Aspekte wie Deployment oder Ausfälle.
Ebenso sollen die Microservices Resilience bieten. Wenn ein Microservice ausfällt, müssen die anderen Microservices weiterhin laufen. Sonst ist die Entkopplung bezüglich Ausfällen nicht erreicht. Das System wäre außerdem nicht sonderlich stabil, da der Ausfall eines beliebigen Microservice zu einer Fehlerkaskade führen und das gesamte System zum Ausfall bringen kann. Bei der hohen Anzahl an Microservices ist das ein untragbares Risiko.
Mikro- und Makroarchitektur von Microservices
Die ISA-Prinzipien unterscheiden zwischen Mikro- und Makroarchitektur. Mikroarchitektur bezeichnet Entscheidungen, die auf der Ebene jedes Microservice anders getroffen werden können. Die Makroarchitektur beeinflusst hingegen alle Microservices. Sie muss langfristig stabil sein, denn Änderungen sind schwer umsetzbar. Schließlich beeinflussen sie alle Microservices. Außerdem soll die Makroarchitektur minimal sein, damit die unabhängige Entwicklung der Microservices möglichst wenig eingeschränkt wird.
Aus den ISA-Prinzipien lässt sich ableiten, dass Microservices lose gekoppelt sein sollen und Resilience unterstützen müssen. Das sind wichtige Faktoren bei der Auswahl passender Technologien. Die Aufteilung in Mikro- und Makroarchitektur hat ebenfalls Auswirkungen auf die Technologieauswahl. Das Framework und die Programmiersprache, mit denen ein Microservice umgesetzt wird, kann Teil der Mikroarchitektur sein. Schließlich ist es ein wesentlicher Vorteil von Microservices, dass jeder Microservice mit einer anderen Technologie umgesetzt werden kann. Wenn die Makroarchitektur langfristig stabil sein soll, ist es kaum sinnvoll, eine Programmiersprache oder ein Framework festzuschreiben.
Lesen Sie auch: Microservices mit Java EE: Realistisch und pragmatisch
Wer heute mit Java 9 und Spring Boot 2.0 entwickelt, kann sicher sein, dass der Stack in ein paar Jahren veraltet sein wird. Bei langlaufenden Projekten gilt daher: Wenn alle Microservices dieselben Technologien nutzen sollen, muss man entweder die Technologien veralten lassen oder man migriert alle Microservices gleichzeitig auf die aktuelle Technologie, was risikoreich und aufwendig ist. Nur wenn man unterschiedliche Technologien zulässt, kann man jeden Microservice einzeln modernisieren. Technologiefreiheit erlaubt Teams außerdem, das beste Werkzeug für die jeweilige Herausforderung zu wählen. Dennoch müssen bestimmte Technologien auf Ebene der Makroarchitektur festgeschrieben werden, etwa Technologien für die Kommunikation. Sie beeinflussen alle Microservices und sind daher auch nicht leicht zu ändern.
Microservices: UI-Integration
Ein Microservice kann auch ein UI enthalten. Zum Beispiel kann der Microservice eine HTML-Seite anzeigen. Die Integration eines anderen Microservice kann einfach ein Link sein. Ein konkretes Beispiel zeigt die Crimson Assurance, die als Demo mit einer ausführlichen Anleitung zum Download bereitsteht [2], aber auch online ausprobiert werden kann [3]. Das System ist ein Prototyp für eine Anwendung zur Unterstützung von Versicherungsmitarbeitern. Man kann Versicherte aufrufen und für ihre Autos Schäden erfassen. Das Erfassen des Schadens findet in einem anderen Microservice statt als die Auswahl und Anzeige des Kunden. Die Integration erfolgt über einen Link.
Eine solche Integration hat einige Vorteile: Die Kopplung ist sehr lose, nur das Format der URL muss festgelegt sein und der andere Service kann seine Webseite beliebig aufbauen. Auch für Resilience ist gesorgt: Wenn der verlinkte Microservice ausfällt, kann der Link immer noch angezeigt werden.
Nachdem der Nutzer einen Schaden eingegeben hat, wird er zur Hauptanwendung zurückgeschickt. Das Formular zur Registrierung des Schadens liegt im Schaden-Microservice. Nachdem das Formular abgeschickt ist, wird der Nutzer auf die Seite der Hauptanwendung mit Hilfe eines HTTP-Redirects zurückgeführt. Auch hier ist die Kopplung sehr lose und die Resilience recht gut umgesetzt.
Client-seitige Transklusion
Schließlich kann der Nutzer die Postbox aus dem Postbox-Microservice in die Webseite der Hauptanwendung einblenden. Man spricht von Transklusion. Auf der HTML-Seite ist ein Link mit einigen zusätzlichen Attributen enthalten. JavaScript-Code liest diese Attribute aus und ersetzt den Link durch einen Überblick aus dem Postbox-Microservice, wenn der Nutzer auf den Link klickt. Steht der Postbox-Microservice nicht zur Verfügung, zeigt der Code eine Fehlermeldung an.
Selbst wenn der JavaScript-Code gar nicht funktioniert, weil er nicht geladen werden konnte oder mit dem Browser des Benutzers inkompatibel ist, wird dennoch der Link angezeigt. Resilience ist also sichergestellt. Bei der Entkopplung ist es schwieriger: Damit die Postbox eingeblendet werden kann, muss das Layout zur Hauptanwendung passen. Ähnlich wie bei einer Schnittstellenabstimmung in einem klassischen System muss auch hier sichergestellt sein, dass die beiden Systeme zueinander passen.
Ein Vorteil dieser Integrationen ist, dass sie technologisch einfach ist. Die Integration nutzt fundamentale Konzepte von HTML und HTTP sowie ein wenig JavaScript-Code. Sie lässt sich mit beliebigen Backend-Technologien verwenden. Crimson Assurance besteht dementsprechend auch aus Spring Boot und Node.js Microservices.
Serverseitige Transklusion
Die Transklusion kann auch auf dem Server stattfinden. Das stellt sicher, dass keine Bestandteile der Seite nachgeladen werden müssen. Das kann beispielsweise für die Navigationsleiste sinnvoll sein. Für serverseitige Transklusion gibt es Standards wie SSI [4] oder ESI [5]. Ein Microservice liefert dann HTML aus, in dem SSI- bzw. ESI-Tags enthalten sind. Webserver interpretieren SSI-Tags während Webcaches ESI implementieren. Der Webserver oder Webcache lädt entsprechend den Tags HTML-Schnipsel anderer Microservices nach.
Das Beispiel [4] nutzt den Webcache Varnish (Abb. 1) und sollte dank einer ausführlichen Dokumentation sehr einfach zu starten sein. Diesen Cache kann eine Website nutzen, um Zugriffe auf die Backend-Services zu vermeiden und sie aus dem Webcache zu bedienen. Mit ESI kann der Cache sogar Webseiten mit dynamischen Anteilen cachen. Die dynamischen Anteile kommen aus dem Backend und werden mit ESI in die gecachten statischen Seiten integriert. Das Beispiel nutzt diesen Ansatz, um eine Navigationsleiste zu integrieren. Alle Bestandteile werden 30 Sekunden im Cache gehalten.
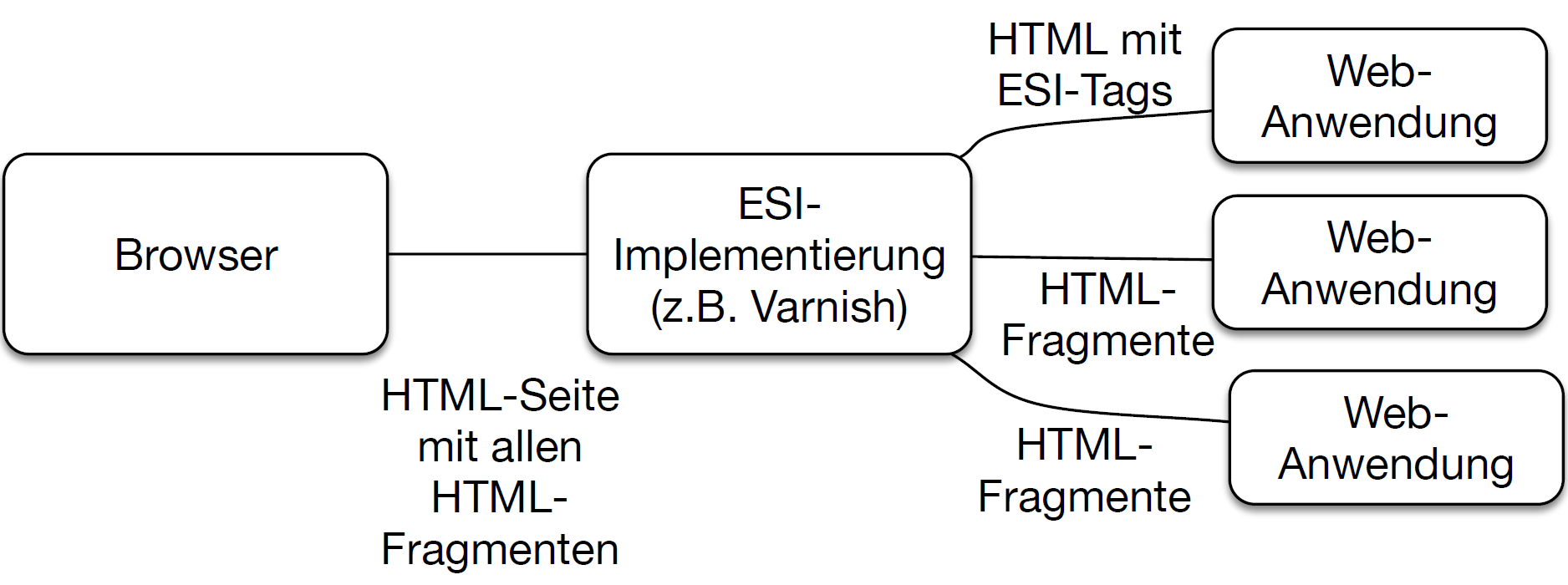
Abb. 1: Transklusion mit ESI und Varnish
Bezüglich der Kopplung gilt Ähnliches wie bei der clientseitigen Transklusion: Das Layout der Webinhalte muss so aufeinander abgestimmt sein, dass sie in einer Webseite kombiniert werden können. Bezüglich Resilience hilft der Cache ebenfalls: Wenn die Backends nicht verfügbar sind, werden die Daten 15 Minuten im Cache gehalten. So können Lesezugriffe weiterhin bearbeitet werden.
UI-Integration: Fazit
UI-Integration unterstützt lose Kopplung und Resilience. Technisch ist sie sehr einfach: Links, Redirects und ca. 60 Zeilen JavaScript können ausreichen. Oft trifft man auf das Vorurteil, dass ein UI, das von mehreren Microservices gemeinsam dargestellt wird, kein einheitliches Look and Feel haben kann. Aber auch bei einem Deployment-Monolith kann eine Webseite völlig anders aussehen als alle anderen Webseiten. Der einzige Weg zum einheitlichen Look and Feel ist ein Style Guide. Außerdem sind gemeinsame Assets hilfreich. Das setzt das Crimson-Assurance-Beispiel mit einem Assetprojekt um, während das ESI-Beispiel die Assets von einem Microservice ausliefern lässt.
Der Microservices & Architecture Track auf der JAX 2019
Asynchrone Microservices
Eine weitere Möglichkeit zur Kopplung von Microservices ist asynchrone Kommunikation. Das bedeutet: Wenn ein Microservice gerade einen Request bearbeitet, darf er keinen anderen Microservice aufrufen und auf eine Antwort warten. Er darf also einen anderen Microservice nur dann aufrufen, wenn er nicht auf eine Antwort wartet. Beispielsweise kann ein Microservice gerade einen Request für eine Bestellung bearbeiten. Als Teil der Logik kann der Microservice einen anderen Microservice aufrufen, der eine Rechnung schreiben soll. Allerdings darf er nicht auf eine Antwort warten, sondern muss weiterarbeiten. Wenn der Empfänger gerade nicht verfügbar ist, wird die Nachricht später übermittelt. Die Rechnung würde also später geschrieben und Resilience wäre gewährleistet.
Der Microservice kann auch andere Microservices aufrufen und auf eine Antwort warten. Allerdings nur, wenn der Microservice selbst nicht gerade einen Request behandelt. So kann der Service beispielsweise regelmäßig neue Kundendaten abfragen, auf die Daten warten und sie replizieren. Bei einem Ausfall des Microservice findet keine Replikation statt. Also veralten die Daten, aber das System funktioniert weiterhin und Resilience ist gewährleistet.
Asynchrone Kommunikation mit Message-oriented Middleware
Eine Message-oriented Middleware (MOM) kann eine Infrastruktur bereitstellen, um asynchrone Nachrichten zu verschicken. Eine MOM kann die Zustellung von Nachrichten mit einer hohen Sicherheit garantieren. Dazu muss sie allerdings die Nachrichten dauerhaft speichern. Schließlich kann nur so sichergestellt werden, dass die Nachricht auch dann zugestellt wird, wenn der Empfänger gerade ausgefallen ist.
MOM und Kafka
In der Java-Welt ist JMS (Java Message Service) [6] oft das Mittel der Wahl für asynchrone Kommunikation. Aber gerade im Microservices-Umfeld wird Kafka [7] zunehmend wichtiger. Während andere MOMs Nachrichten meist nur eine gewisse Zeit vorhalten, kann Kafka die Nachrichten beliebig lange speichern. Also kann ein Empfänger sich alle Nachrichten noch einmal zustellen lassen. Auch für die Nutzung von Kafka für Microservices-Systeme gibt es eine einfache Beispielanwendung, bei der aus einer Bestellung eine Rechnung und eine Lieferung werden sollen [8].
Asynchrones REST
Natürlich wäre es denkbar, statt Kafka eine andere MOM zu nutzen. Da alle Kommunikation zwischen den Microservices über die MOM gehen, muss es mit einer hohen Last zurechtkommen und hochverfügbar sein. Das ist an sich kein Problem: Schließlich gibt es schon lange MOM-Installationen, die unternehmenskritisch sind. Dennoch kann es anspruchsvoll sein, die MOM entsprechend zu tunen.
Es wäre schön, wenn es eine Möglichkeit für asynchrone Kommunikation gäbe, die ohne MOM auskommt. Genau das ist mit REST möglich. Ein Microservice holt sich per HTTP GET von einem anderen Microservice die Events ab. Dieses Vorgehen scheint nicht besonders effizient zu sein, denn die Services kommunizieren recht häufig miteinander und in den meisten Fällen gibt es keine neuen Events. Das kann durch HTTP Caching gelöst werden: Der Client schickt beim HTTP Request den Zeitstempel der letzten ihm bereits bekannten Änderung mit. Wenn es keine neuen Events gibt, antwortet der Server mit einem HTTP-Status 304 (Not Modified). Nur wenn es neue Nachrichten gibt, werden tatsächlich Daten mitgeschickt. Um keine überflüssigen Events zu übertragen, kann die Schnittstelle Optionen anbieten, um nur einige Events zu übertragen. So lässt sich die Kommunikation sehr effizient gestalten.
Wenn der Server sowieso die alten Events abgespeichert hat, dann kann er diese Events an der Schnittstelle anbieten, ohne dass dazu eine weitere Speicherung wie bei Kafka notwendig wäre. Das Beispiel [9] nutzt Atom, um die Events dem Client zur Verfügung zu stellen.
Dieses Datenformat wird sonst genutzt, um Abonnenten Blogs oder Podcasts zur Verfügung zu stellen.Im Gegensatz zu Kafka und den meisten anderen MOMs kann asynchrones REST Events nicht an nur einen Empfänger schicken. Jeder Empfänger bekommt alle neue Events und kann sie bearbeiten. So könnte eine Bestellung von mehreren Empfängern bearbeitet werden, sodass mehrere Rechnungen oder Lieferungen ausgelöst werden. Das Beispiel löst das Problem und schaut zunächst in der Datenbank nach, ob die Bestellung schon bearbeitet worden ist. Nur wenn das nicht der Fall ist, bearbeitet der Client die Bestellung; die Clients synchronisieren sich also über die Datenbank. Bezüglich Skalierung hat dieses Vorgehen Nachteile: Nur ein Client bearbeitet ein Event, aber alle anderen überprüfen, ob das Event schon bearbeitet worden ist und führen dabei eine Datenbankoperation aus.
Die Implementierung muss nicht nur für REST, sondern auch für Kafka mit doppelt übertragenen Events zurechtkommen. Wenn ein Event vom Empfänger nicht quittiert wird, geht die MOM davon aus, dass das Event nicht erfolgreich bearbeitet worden ist und überträgt es erneut. Es kann aber sein, dass der Empfänger das Event erfolgreich bearbeitet hat und nur den Empfang nicht quittiert hat. Für diesen Fall muss der Client überprüfen, ob das Event bereits bearbeitet worden ist.
Synchrone Kommunikation bei Microservices
Viele Microservices-Projekte nutzen synchrone Kommunikation mit REST, obwohl das viele Nachteile hat. Bei synchroner Kommunikation kann ein Microservice gerade an einem Request arbeiten und währenddessen einen anderen Microservice aufrufen, um beispielsweise die Kundendaten auszulesen. Wenn der Kundendatenservice gerade ausgefallen ist, muss der Aufrufer eine alternative Strategie umsetzten. Das kann eine fachliche Fragestellung sein: Nimmt man die Bestellung an, wenn man gerade die Zahlungsfähigkeit des Kunden nicht überprüfen kann? Es ist also viel schwieriger, Resilience sicherzustellen.
Bibliotheken wie Hystrix [10] können nur einen Teil der Resilience-Herausforderungen lösen: So kann ein Timeout vermeiden, dass Microservices zu lange auf andere Microservices warten und dadurch ausfallen. Hystrix ist in Java geschrieben und schränkt daher die Technologieauswahl ein. Eine Alternative ist Istio Proxy [11]. Dieser Proxy sichert den Netzwerkverkehr ab und hängt nicht von einer Programmiersprache ab. Einen Microservice mit einem durch das Netz erreichbaren Service gegen Probleme zum Beispiel beim Netzwerkzugriff abzusichern erscheint absurd, aber der Proxy kann auf derselben Hardware laufen und durch das Loopback-Device angesprochen werden.
Bei der Kopplung gilt dasselbe wie bei asynchroner Kommunikation: Für die Unabhängigkeit ist es wichtig, wer APIs und Datenstrukturen definiert und wie viele Microservices von Änderungen beeinflusst werden. Das ist unabhängig davon, ob die Kommunikation synchron oder asynchron ist.Synchrone Microservices müssen diese Herausforderungen lösen:
- Serviceinstanzen sind über eine IP-Adresse und einen Port erreichbar. Um einen Service zu finden, müssen diese Informationen anhand eines Servicenames ermittelt werden (Service Discovery).
- Von jedem Microservice kann es mehrere Instanzen geben. Die Last muss zwischen den Instanzen aufgeteilt werden (Load Balancing).
- Schließlich sollen die Microservices von außen wie ein einziges System wirken. Das Routing muss also einen Request an das System an den zuständigen Microservice weiterleiten.
Der Service Discovery kommt eine entscheidende Rolle zu, denn sie kann die Basis für die Lösung der anderen Herausforderungen sein.
Quarkus-Spickzettel

Quarkus – das Supersonic Subatomic Java Framework. Wollen Sie zeitgemäße Anwendungen mit Quarkus entwickeln? In unserem brandaktuellen Quarkus-Spickzettel finden Sie alles, was Sie zum Loslegen brauchen.
Consul
Consul [12] bietet eine Lösung für Service Discovery. Im Beispiel [13] benötigt die Registrierung eines Microservices nur die Spring Cloud Annotation @EnableDiscoveryClient, einige Einstellungen in der application.properties-Konfigurationsdatei und eine Abhängigkeit zur Bibliothek spring-cloud-starter-consul-discovery. Für das Load Balancing nutzt das Beispiel die Ribbon Library von Netflix. Sie liest alle Instanzen eines Microservice aus Consul aus. Jeder Aufruf geht an eine andere Instanz. So findet das Load Balancing vollständig auf dem Client statt. Ein zentraler Load Balancer, der sonst ein Bottleneck und ein Single Point of Failure wäre, wird vermieden.
Für das Routing von Aufrufen von außen auf den richtigen Microservice nutzt das Beispiel einen Apache-Webserver. Der muss aber so konfiguriert werden, dass er alle Microservices-Instanzen kennt. Consul Template [14] biete dafür eine Lösung: Es erstellt aus einem Template eine Konfigurationsdatei mit Einträgen aus der Consul Service Discovery. Der Apache-Webserver wird so als Reverse Proxy und Load Balancer konfiguriert. Bei einer Änderung in Consul erstellt Consul Template eine neue Version der Konfigurationsdatei und startet den Apache-Webserver neu. Der Webserver weiß nichts von Consul oder Service Discovery, sondern liest einfach nur Informationen aus der Konfigurationsdatei aus.
Lesen Sie auch: Jenkins in der Praxis – Verteilung eines Deployment-Servers
Dieser Aufbau führt aber zu Abhängigkeiten in den Spring-Boot-Projekten zu Consul, um die Registrierung in Consul umzusetzen und das Load Balancing zu implementieren. Das erfordert zwar keinen besonders großen Aufwand, aber die Abhängigkeiten machen es schwierig, Microservices mit einer anderen Technologie in das System einzuführen. Statt Ribbon und den Spring-Cloud-Funktionalitäten für die Registrierung in Consul müsste eine andere Bibliothek genutzt werden.
Für die Registrierung kann aber auch eine Lösung gewählt werden, die ohne Code oder Codeabhängigkeiten auskommt: Registrator [15] kann einen Docker-Container in einer Service Discovery wie Consul registrieren, wenn der Container gestartet wird. So wird der Code unabhängig von Consul. Schließlich kann der Zugriff auf Consul über DNS (Domain Name System) stattfinden, das im Internet auch für die Auflösung von Hostnamen zu IP-Adressen genutzt wird. Die DNS-Anfragen unterstützen auch Load Balancing, so dass die Abhängigkeit zu Ribbon ebenfalls verschwindet. Das Beispiel [16] wird so im Code vollständig unabhängig von Consul. Daher ist es auch kein Problem, einen Microservice in das System zu integrieren, der in einer anderen Programmiersprach oder mit anderen Frameworks implementiert ist.
Kubernetes
Kubernetes [17] ist eine Plattform, die es erlaubt, Docker-Container in einem Cluster ablaufen zu lassen. Kubernetes löst auch die typischen Herausforderungen für synchrone Microservices. Für Service Discovery bietet eine Kubernetes-Installation DNS an. Wenn ein Microservice in Kubernetes gestartet wird, wird er automatisch im DNS registriert. Load Balancing findet auf der Ebene von IP statt: Der Microservice ist unter einer IP-Adresse erreichbar, hinter der sich alle Instanzen verbergen. Im Gegensatz zum DNS-basierten Load Balancing kann dieses Vorgehen sicherstellen, dass DNS-Caches kein Problem sind.
Ein Caching von DNS-Ergebnissen kann nämlich dazu führen, dass die Last nicht zwischen allen Instanzen gleichmäßig verteilt wird, weil einige System veraltete Daten gecacht haben. Für das Routing der Zugriffen von außen bietet Kubernetes Node Ports. Der Kubernetes-Cluster besteht aus verschiedenen Servern bzw. Nodes. Auf jedem Node steht der Microservice unter seinem Node Port zur Verfügung, den ein externer Service nun nutzen kann. Kubernetes kann auch einen Load Balancer konfigurieren, um den Zugriff von außen auf die Microservices zu erlauben. Das Beispiel [18] setzt genau ein solches Vorgehen mit Kubernetes um.
Fazit
Microservices bieten Technologiefreiheit bei der Implementierung der einzelnen Microservices. Daher teilen die ISA-Prinzipien die Architekturentscheidungen in die globale Makro- und die nur einen einzelnen Microservices betreffende Mikroebene auf. Die Entscheidung für eine Programmiersprache oder ein Microservice-Framework kann ein Teil der Mikroarchitektur sein und ist sehr einfach zu revidieren: Man implementiert den nächsten Microservice mit einer anderen Programmiersprache und einem anderen Framework. Technologien zur Kommunikation hingegen sind auf der Makroebene angesiedelt. Eine Entscheidung für eine solche Technologie ist schwieriger zu revidieren, weil sie alle Microservices beeinflussen kann.
Für die Kommunikation gibt es zahlreiche Optionen (Abb. 2):
- UI-Integration bietet eine technologisch wenig aufwendige Alternative, die zu einer guten Resilience und Entkopplung führt.
- Ähnliches gilt für asynchrone Kommunikation. Wenn ein Service ausfällt, werden Nachrichten später übertragen, was zu Dateninkonsistenzen führen kann. Aber die anderen Microservices sind auf jeden Fall weiter nutzbar.
- Bei synchroner Kommunikation muss das System dagegen damit umgehen können, wenn ein Service ausgefallen ist.
Abb. 2: Die Integrationsmöglichkeiten im Überblick
Die verschiedenen hier gezeigten Alternativen stellen Optionen für die Makroarchitektur dar. In jedem Projekt muss diese Entscheidungen selbst getroffen werden. Es gibt bei den hier präsentierten Ansätzen auch viele Variationsmöglichkeiten. Gerade diese Abwägung und Auswahl ist ein Kern der Architekturarbeit.
Neben den hier näher erläuterten Beispielen gibt es eine weitere Demo [19] für typische Microservices-Technologien. Die hier gezeigten Ideen stehen auch im Mittelpunkt der kostenlosen Broschüre „Microservices Rezepte“[20] und des „Microservices Praxisbuchs“ [21]. Die kostenlose Broschüre „Microservices Überblick“ [22] und das Microservices-Buch [23] behandeln zwar auch Technologien, stellen aber die Architektur in den Mittelpunkt.
Links & Literatur
[1] Independent Systems Architecture (ISA) Principles: http://isa-principles.org/
[2] Crimson Assurance Demo: https://github.com/ewolff/crimson-assurance-demo
[3] Crimson Assurance: http://crimson-portal.herokuapp.com/
[4] SCS-ESI: https://github.com/ewolff/SCS-ESI
[5] Transklusion: https://git.io/vhl9q
[6] JMS: https://jcp.org/aboutJava/communityprocess/final/jsr914/index.html
[7] Kafka: https://kafka.apache.org/
[8] Microservice-Kafka: https://github.com/ewolff/microservice-kafka
[9] Microservcie-Atom: https://github.com/ewolff/microservice-atom
[10] Hystrix: https://github.com/Netflix/Hystrix
[11] Istio: https://istio.io/
[12] Consul: https://www.consul.io/
[13] Mircoservice-Consul: https://github.com/ewolff/microservice-consul
[14] Consul-Template: https://github.com/hashicorp/consul-template
[15] Registrator: https://github.com/gliderlabs/registrator
[16] Microservice-Consul-DNS: https://github.com/ewolff/microservice-consul-dns
[17] Kubernetes: https://kubernetes.io/
[18] Microservice-Kubernetes: https://github.com/ewolff/microservice-kubernetes
[19] Microservices-Demos: https://ewolff.com/microservices-demos.html
[20] Microservices Rezepte: https://microservices-praxisbuch.de/rezepte.html
[21] Microservices Praxisbuch: https://microservices-praxisbuch.de/
[22] Microservice Überblick https://microservices-buch.de/ueberblick.html
[23] Wolff, Eberhard: Microservices. https://microservices-buch.de/
Erfahren Sie mehr über Microservices & Architecture auf der W-JAX 2019:
● Microservices-Workshop: Idee, Architektur, Umsetzung und Betrieb
● Aus der Rubrik „Spaß mit Microservices“: Transaktionen